该方法出自论文S3FD: Single Shot Scale-invariant Face Detector
文章改进点:
(1)基于不同layer层的不同scale的anchor策略
其中各个卷积层的滑动步长,anchor大小,感受野大小分别如下,其中anchor 的aspect ratio为1:1。
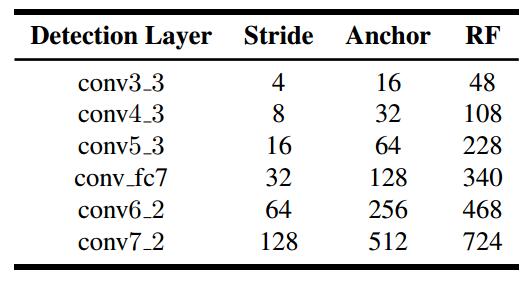
这样的设置,主要是由于作者在实际真实数据样本中得出,anchor面积要小于感受野面积,这样才可以保证anchor对于小人脸的覆盖率。
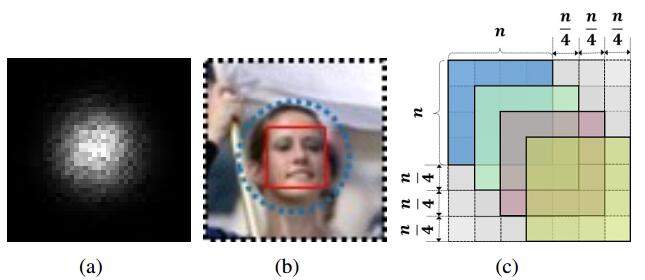
如上图所示,其中(a)中黑色的整个区域表示theoretical receptive field (TRF),而白色的区域表示effective receptive field (ERF),可以看出ERF只是TRF的其中一部分。
(b)为与(a)对应的一个真实的例子,其中黑色虚线为整个的TRF,蓝色的虚线为ERF,红色的实线为anchor,可以看出大小上TRF>ERF>anchor
(c)为相同比例间隔的采样策略,就是本人中的anchor的stride为anchor大小的1/4
(2)一个尺度修正策略来提高对小人脸的召回率
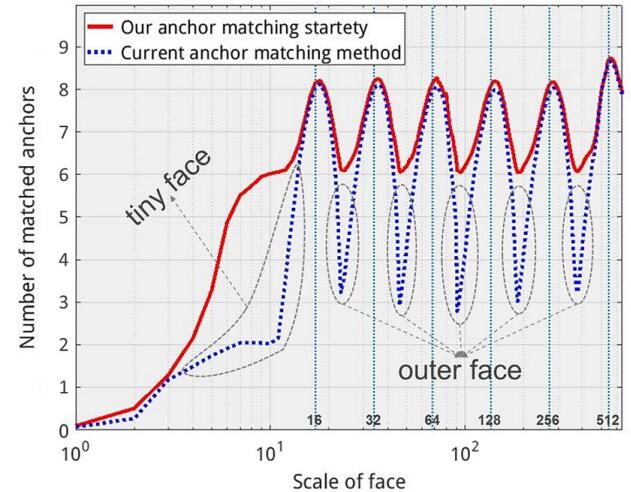
主要分为2个步骤,首选将原始的anchor阈值从0.5降低为0.35,然后再在IOU大于0.1的anchor中取top-N,其中N为第一步中的anchor大于0.35的平均值。
从下面的结果曲线可以看出,使用该策略小人脸的召回率得到了很大的提高。图中,红色的为尺度修正策略后的结果,蓝色的为原始的结果。
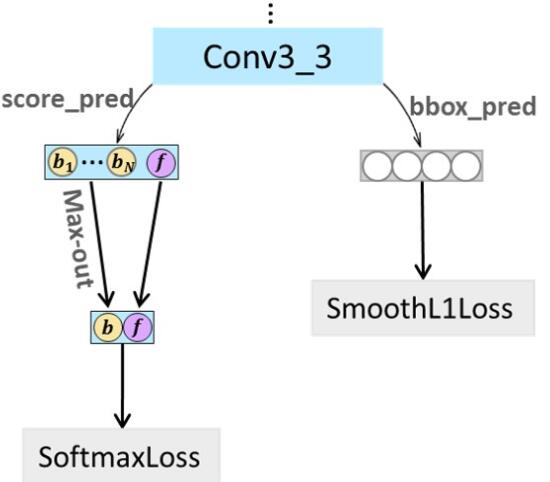
(3)max-out类型的分类训练策略,用来减少小人脸的falsepositive率
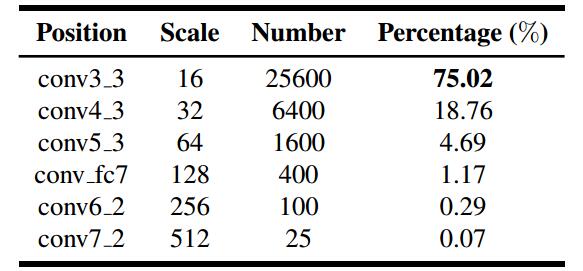
这个改进是对conv3_3层进行的改进,由于刚开始的卷积层特征图比较大,作者又做了比较密集的anchor来提高对小人脸的召回率,这样就引入了新的问题,正负样本出现了严重不平衡。如下图所示。其中conv3_3层的false positive率达到了75.02%。
为了解决上面的不平衡问题,作者提出了max-out策略。如下图所示,作者在分类中,使用预测分数最高的anchor进行梯度的回传,大大的减少了正负样本不平衡的现象。
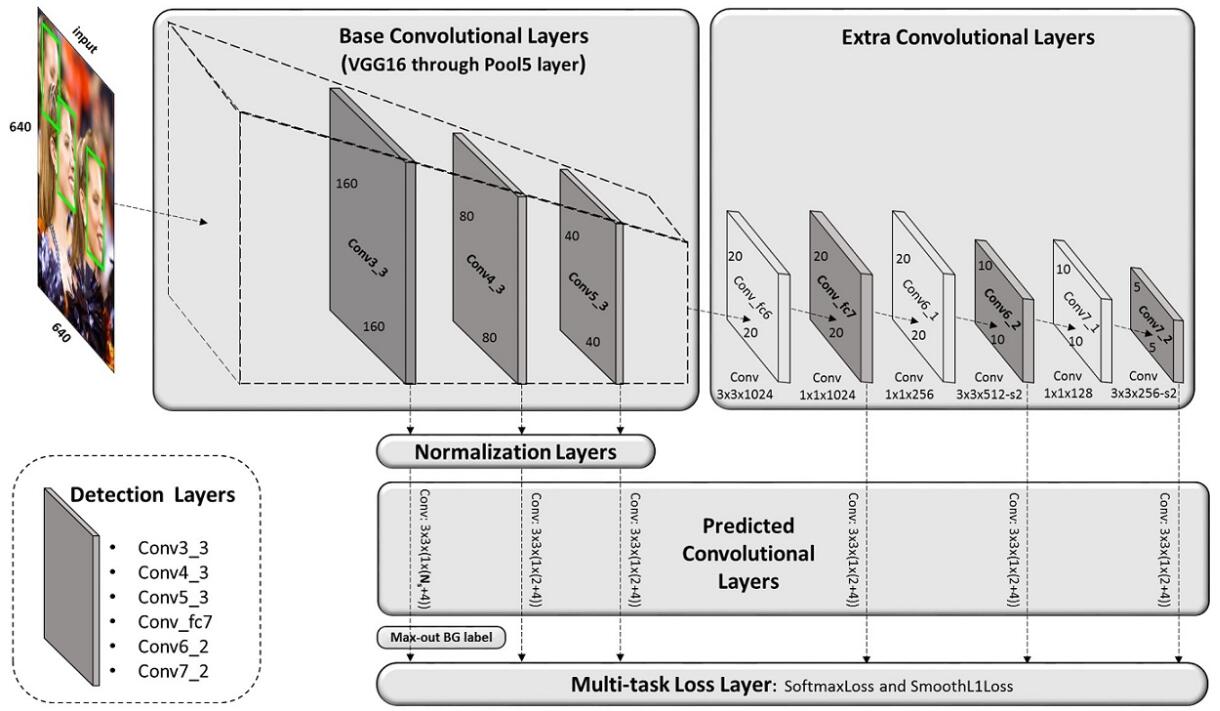
整体网络分为以下6个部分,Base Convolutional Layers,Extra ConvolutionalLayers ,Detection Convolutional Layers,Normalization Layers,PredictedConvolutional Layers,Multi-task Loss Layer。
总结:
整体来看,文章的第一个scale创新就是ssd中就有的东西。人脸尺度修正策略简单的说就是通过小阈值来提高召回率,然后再辅之一些后处理。Max-out的策略,也不像OHEM,focal loss那样创新性高。整体来看创新性不是很高。
References:
https://github.com/sfzhang15/SFD