from sklearn.datasets.california_housing import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)一、介绍
对于不同类型的数据集,有三种不同类型的数据集接口。
1、生成数据函数与svmlight loader共享同一规则。
返回一元组tuple(X,y),X为array(n*m), y也为array(n*1)
2、其返回类似于字典类型的数据,有两个key:data与target
3、返回对象的数据描述:DESCR;feature_names; target_names
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.datasets.california_housing import fetch_california_housing
housing = fetch_california_housing()
print(housing.data[0:2])
print(housing.target)
type(housing.target)
print(housing.feature_names)
也可如此输入:
from sklearn.datasets import fetch_california_housing
dataset = fetch_california_housing()
X_full, y_full = dataset.data, dataset.target
二、数据集介绍
1、toy datasets
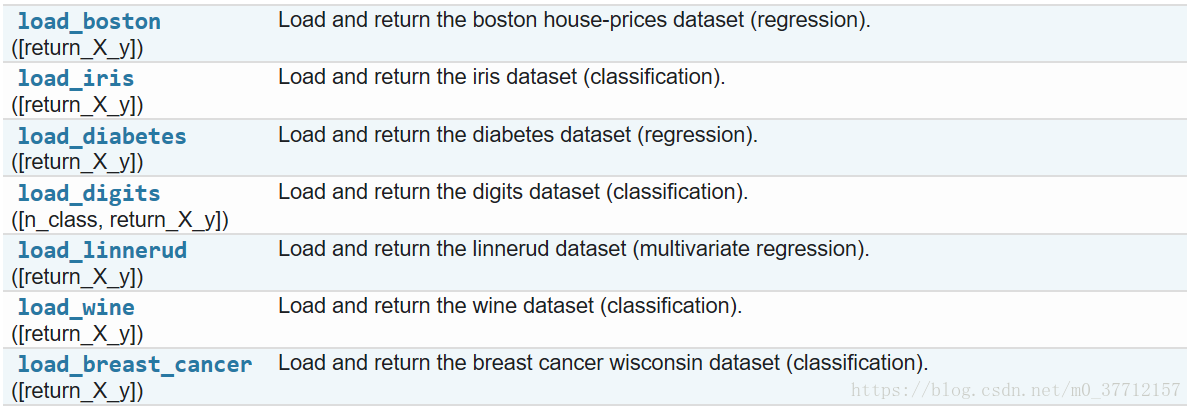
这些数据集有助于快速说明scikit中实现的各种算法的行为。然而,它们往往太小,不能代表现实世界中的机器学习任务。
2、sample images
scikit还嵌入了一些样本JPEG图像,这些图像是作者根据知识共享协议发布的。这些图像可用于测试算法和二维数据管道。
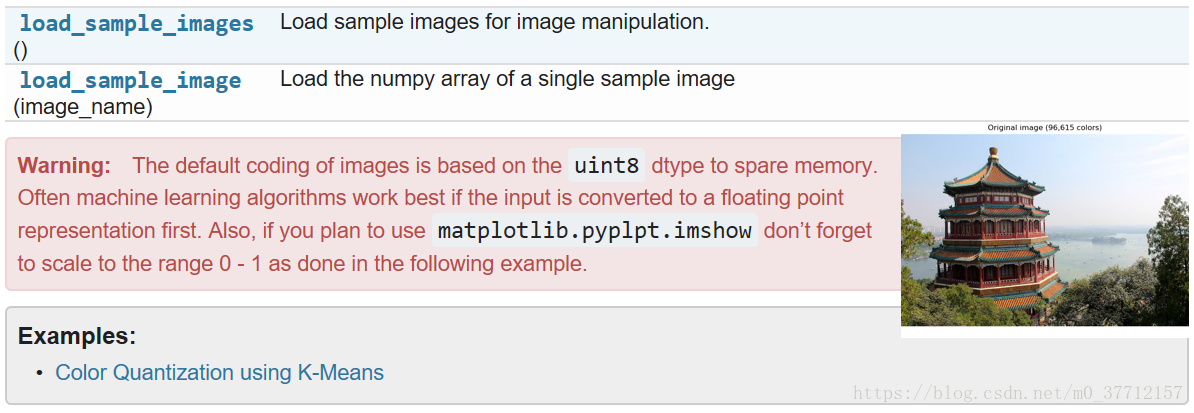
默认的图像编码是基于uint8 dtype来节省内存。通常,如果输入首先转换为浮点表示法,机器学习算法的工作效果最好。另外,如果您计划使用matplotlib.pyplpt。imshow不要忘记缩放到0 - 1的范围,如下例所示。
3、Sample generators
此外,scikit-learn还包含各种随机样本生成器,可用于构建控制大小和复杂性的人工数据集。
(1)、Generators for classification and clustering
这些发生器产生一个特征矩阵和相应的离散目标。
1)、single label
make_blob和make_classification都通过为每个类分配一个或多个正常分布的点集群来创建多类数据集。make_blob能够更好地控制每个集群的中心和标准差,并用于演示集群。make_classification主要通过以下方式引入噪声:相关的、冗余的和不提供信息的特征;每个类有多个高斯簇;特征空间的线性变换。
make_gaussian_quantiles将一个高斯簇划分为几乎相等大小的类,由同心圆超球体分隔。make_hastie_10_2生成了一个类似的二进制10维问题。
make_circles和make_moon生成的二维二进制分类数据集对某些算法(例如基于中心的聚类或线性分类)具有挑战性,包括可选的高斯噪声。它们对视觉化很有用。生成具有球形决策边界的高斯数据,用于二进制分类。
2)、multilabel
make_multilabel_classification生成带有多个标签的随机样本,反映了从多个主题中提取的一组单词。每个文档的主题数量来自泊松分布,主题本身来自固定的随机分布。类似地,单词的数量是从Poisson中提取的,单词是从多项中提取的,其中每个主题定义单词的概率分布。对真正的字库混合的简化包括:
- 每个主题的词分布是独立绘制的,在实际中,所有的词都将受到稀疏基分布的影响,并且是相互关联的。
- 对于由多个主题生成的文档,所有主题在生成其词包时都是同等权重的。
- 没有标签的文档是随机的,而不是基本分布的。
(2)、Generators for regression
make_regression生成带有噪声的随机特征的可选稀疏随机线性组合的回归目标。它的信息性特征可能是不相关的,或者等级低(很少的特征占大多数的方差)。
其他的回归生成器从随机特征中确定地生成函数。make_sparse_uncorrelation生成的目标是由四个固定系数的特征线性组合而成的。另一些则显式地编码非线性关系:make_friedman1通过多项式和正弦变换相关联;make_friedman2包括特性乘法和交互;make_friedman3与targe上的arctan转换类似.
补充:
1、Datasets in svmlight / libsvm format¶
scikit-learn包含用于加载svmlight / libsvm格式数据集的实用函数。在这种格式中,每一行的<标记> <特性id >:<特征值> <特性id >:<特征值> ....这种格式特别适合于稀疏数据集。在这个模块中,X使用scipy稀疏CSR矩阵,y使用numpy数组。
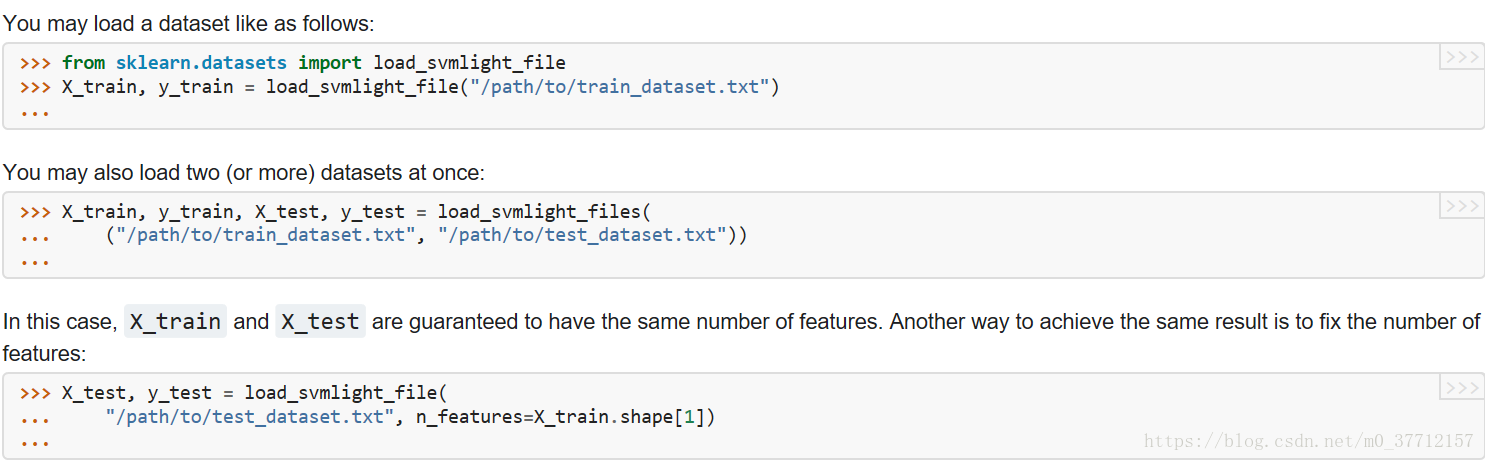
sklearn.datasets 的所有操作;
Loaders¶
datasets.clear_data_home([data_home]) |
Delete all the content of the data home cache. |
datasets.dump_svmlight_file(X, y, f[, …]) |
Dump the dataset in svmlight / libsvm file format. |
datasets.fetch_20newsgroups([data_home, …]) |
Load the filenames and data from the 20 newsgroups dataset. |
datasets.fetch_20newsgroups_vectorized([…]) |
Load the 20 newsgroups dataset and transform it into tf-idf vectors. |
datasets.fetch_california_housing([…]) |
Loader for the California housing dataset from StatLib. |
datasets.fetch_covtype([data_home, …]) |
Load the covertype dataset, downloading it if necessary. |
datasets.fetch_kddcup99([subset, data_home, …]) |
Load and return the kddcup 99 dataset (classification). |
datasets.fetch_lfw_pairs([subset, …]) |
Loader for the Labeled Faces in the Wild (LFW) pairs dataset |
datasets.fetch_lfw_people([data_home, …]) |
Loader for the Labeled Faces in the Wild (LFW) people dataset |
datasets.fetch_mldata(dataname[, …]) |
Fetch an mldata.org data set |
datasets.fetch_olivetti_faces([data_home, …]) |
Loader for the Olivetti faces data-set from AT&T. |
datasets.fetch_rcv1([data_home, subset, …]) |
Load the RCV1 multilabel dataset, downloading it if necessary. |
datasets.fetch_species_distributions([…]) |
Loader for species distribution dataset from Phillips et. |
datasets.get_data_home([data_home]) |
Return the path of the scikit-learn data dir. |
datasets.load_boston([return_X_y]) |
Load and return the boston house-prices dataset (regression). |
datasets.load_breast_cancer([return_X_y]) |
Load and return the breast cancer wisconsin dataset (classification). |
datasets.load_diabetes([return_X_y]) |
Load and return the diabetes dataset (regression). |
datasets.load_digits([n_class, return_X_y]) |
Load and return the digits dataset (classification). |
datasets.load_files(container_path[, …]) |
Load text files with categories as subfolder names. |
datasets.load_iris([return_X_y]) |
Load and return the iris dataset (classification). |
datasets.load_linnerud([return_X_y]) |
Load and return the linnerud dataset (multivariate regression). |
datasets.load_mlcomp(name_or_id[, set_, …]) |
DEPRECATED: since the http://mlcomp.org/ website will shut down in March 2017, the load_mlcomp function was deprecated in version 0.19 and will be removed in 0.21. |
datasets.load_sample_image(image_name) |
Load the numpy array of a single sample image |
datasets.load_sample_images() |
Load sample images for image manipulation. |
datasets.load_svmlight_file(f[, n_features, …]) |
Load datasets in the svmlight / libsvm format into sparse CSR matrix |
datasets.load_svmlight_files(files[, …]) |
Load dataset from multiple files in SVMlight format |
datasets.load_wine([return_X_y]) |
Load and return the wine dataset (classification). |
datasets.mldata_filename(dataname) |
Convert a raw name for a data set in a mldata.org filename. |
Samples generator¶
datasets.make_biclusters(shape, n_clusters) |
Generate an array with constant block diagonal structure for biclustering. |
datasets.make_blobs([n_samples, n_features, …]) |
Generate isotropic Gaussian blobs for clustering. |
datasets.make_checkerboard(shape, n_clusters) |
Generate an array with block checkerboard structure for biclustering. |
datasets.make_circles([n_samples, shuffle, …]) |
Make a large circle containing a smaller circle in 2d. |
datasets.make_classification([n_samples, …]) |
Generate a random n-class classification problem. |
datasets.make_friedman1([n_samples, …]) |
Generate the “Friedman #1” regression problem |
datasets.make_friedman2([n_samples, noise, …]) |
Generate the “Friedman #2” regression problem |
datasets.make_friedman3([n_samples, noise, …]) |
Generate the “Friedman #3” regression problem |
datasets.make_gaussian_quantiles([mean, …]) |
Generate isotropic Gaussian and label samples by quantile |
datasets.make_hastie_10_2([n_samples, …]) |
Generates data for binary classification used in Hastie et al. |
datasets.make_low_rank_matrix([n_samples, …]) |
Generate a mostly low rank matrix with bell-shaped singular values |
datasets.make_moons([n_samples, shuffle, …]) |
Make two interleaving half circles |
datasets.make_multilabel_classification([…]) |
Generate a random multilabel classification problem. |
datasets.make_regression([n_samples, …]) |
Generate a random regression problem. |
datasets.make_s_curve([n_samples, noise, …]) |
Generate an S curve dataset. |
datasets.make_sparse_coded_signal(n_samples, …) |
Generate a signal as a sparse combination of dictionary elements. |
datasets.make_sparse_spd_matrix([dim, …]) |
Generate a sparse symmetric definite positive matrix. |
datasets.make_sparse_uncorrelated([…]) |
Generate a random regression problem with sparse uncorrelated design |
datasets.make_spd_matrix(n_dim[, random_state]) |
Generate a random symmetric, positive-definite matrix. |
datasets.make_swiss_roll([n_samples, noise, …]) |
Generate a swiss roll dataset. |
参考地址:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets