上一篇主要说的是安装
这一片说说怎么使用
启动 [hadoop@146 hadoop-3.0.0]$ ./sbin/start-all.sh
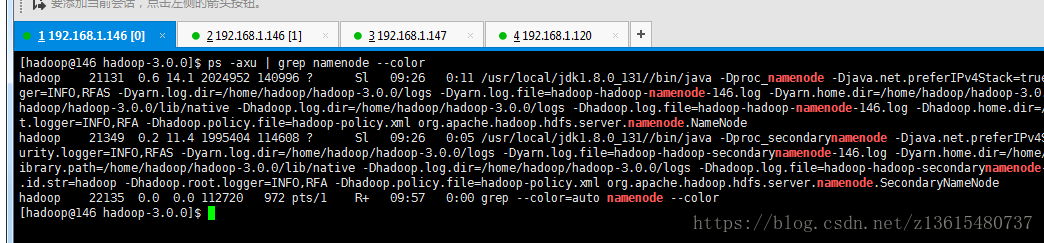
1、查看进程,此时master有进程:namenode和 secondarynamenode进程:
ps -axu | grep namenode --color
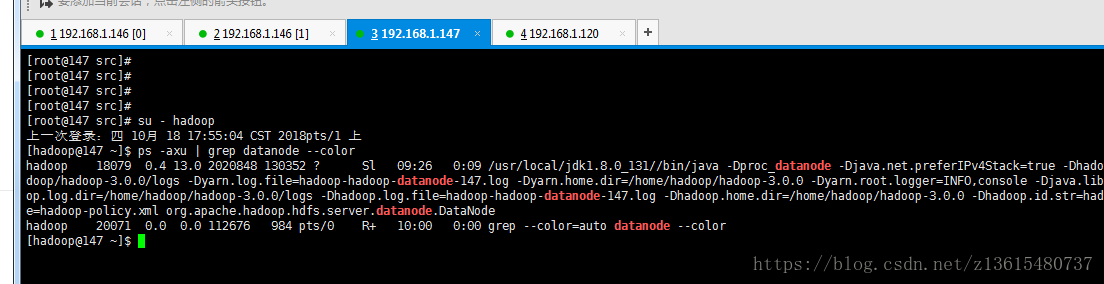
147和120上有进程:DataNode
ps -axu | grep datanode --color
2、在146上启动yarn: ./sbin/start-yarn.sh 即,启动分布式计算
/home/hadoop/hadoop-3.0.0/sbin/start-yarn.sh
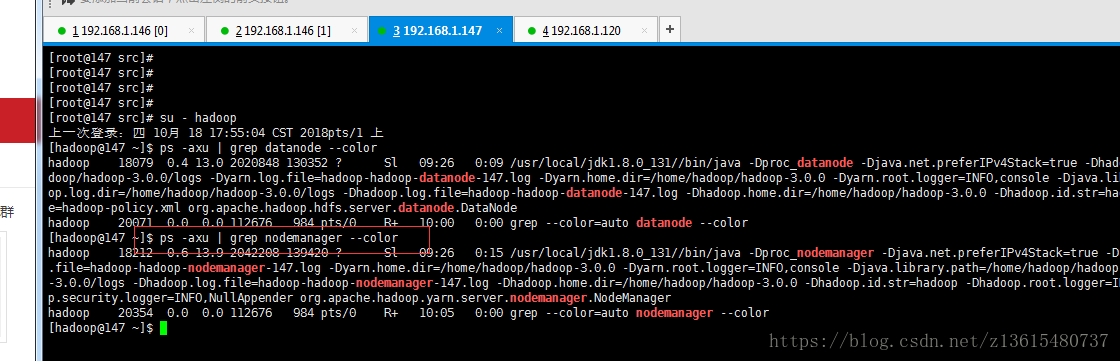
3、查看146上的ResourceManager进程,147和120上的进程:DataNode NodeManager
[root@146 ~]$ ps -axu | grep resourcemanager --color

[root@1467~]$ ps -axu | grep nodemanager --color
启动: jobhistory服务,查看mapreduce运行状态
[hadoop@146 ~]$ /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver
在主节点上启动存储服务和资源管理主服务。使用命令:
[hadoop@146 ~]$ /home/hadoop/hadoop-3.0.0/sbin/hadoop-daemon.sh start datanode #启动从存储服务
[hadoop@146 ~]$ /home/hadoop/hadoop-3.0.0/sbin/yarn-daemon.sh start nodemanager #启动资源管理从服务
查看HDFS分布式文件系统状态 /home/hadoop/hadoop-3.0.0/bin/hdfs dfsadmin -report
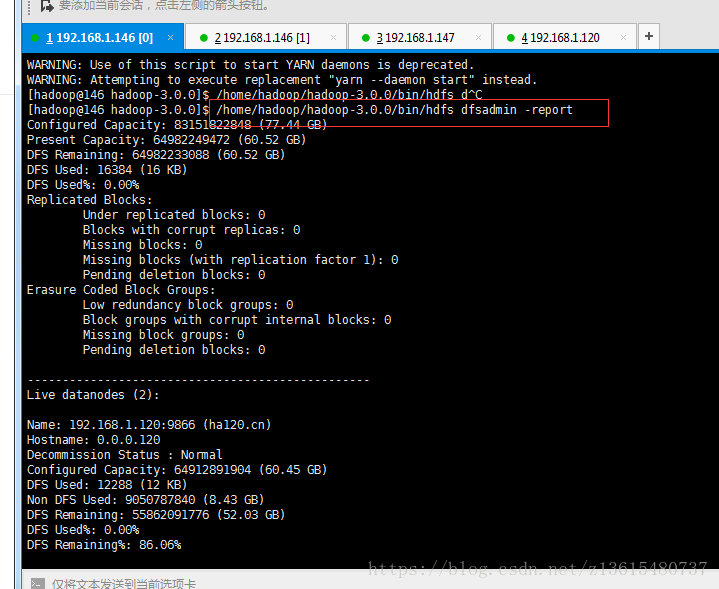
或:http://192.168.1.146:9870/dfshealth.html#tab-datanode
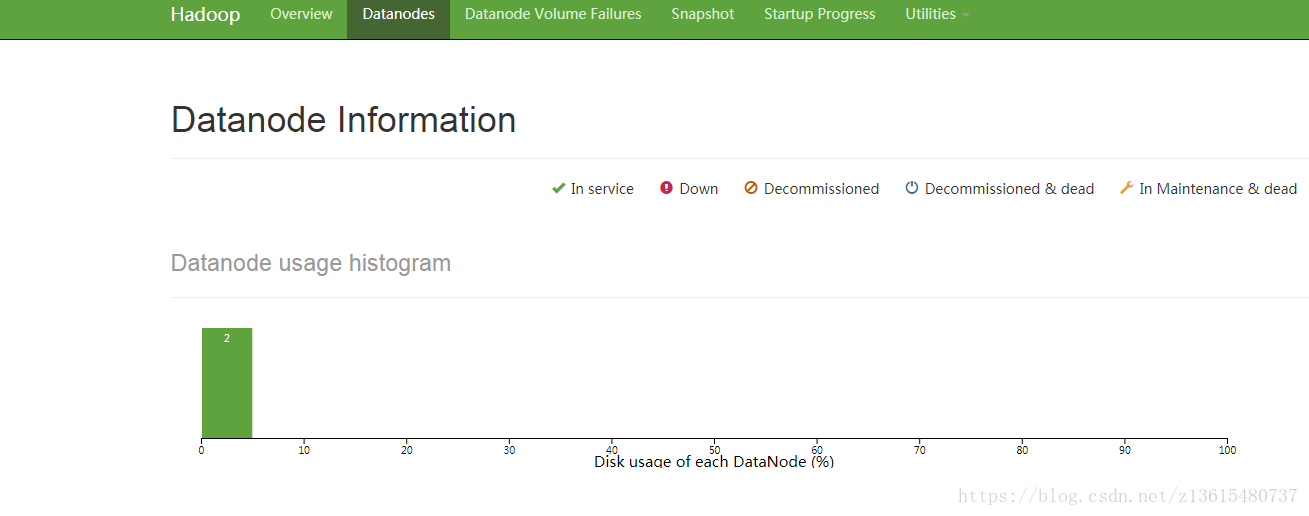
通过web界面来查看HDFS状态: http://192.168.1.146:9001/status.html
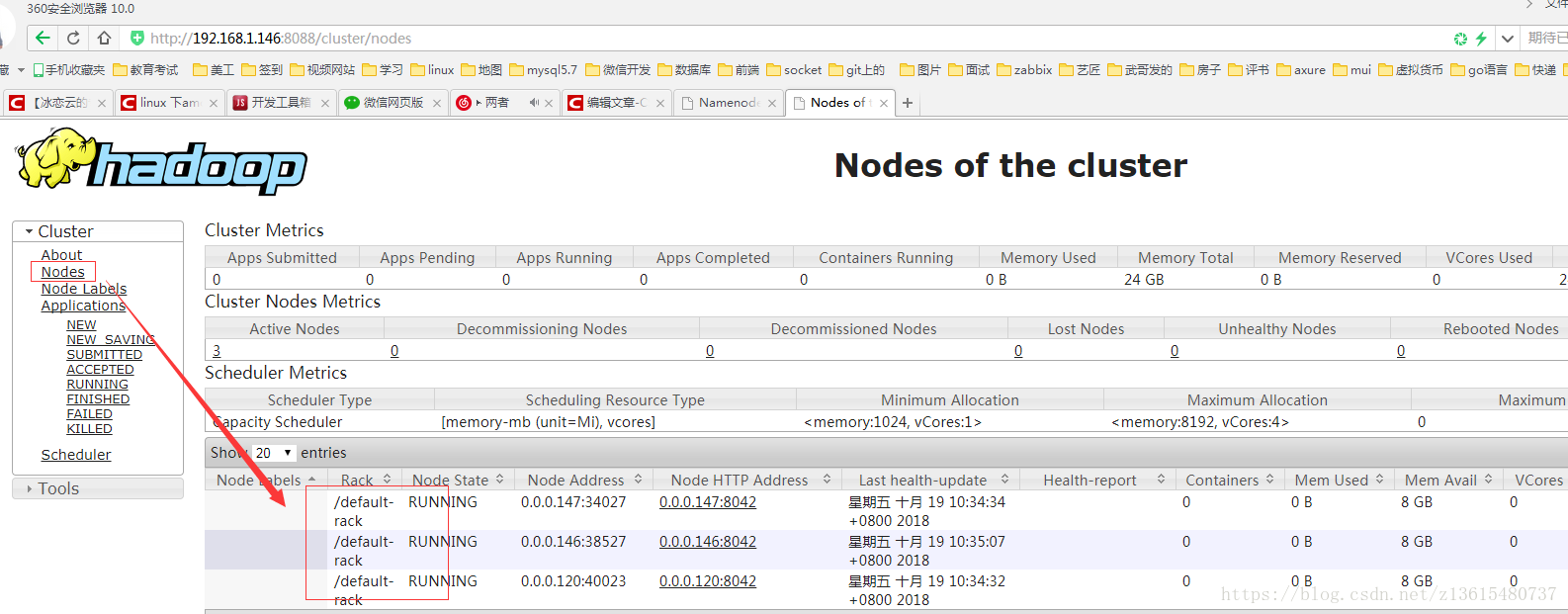
通过Web查看hadoop集群状态: http://192.168.1.146:8088
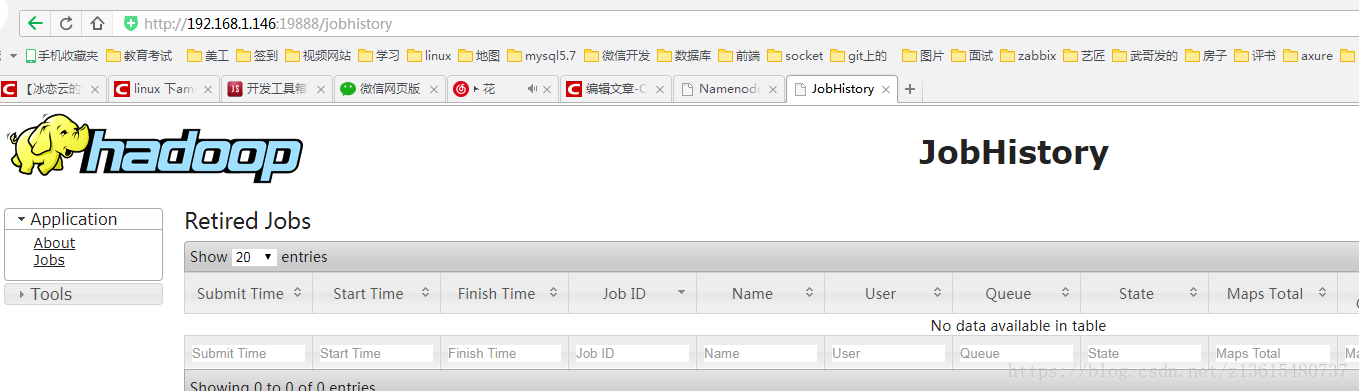
查看JobHistory的内容:http://192.168.1.146:19888/jobhistory