版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sq347216161/article/details/79696642
-----本集群搭建案例,以4节点为例进行搭建
1.JDK环境安装(jdk-7u45-linux-x64.tar.gz 为例 下载地址: https://download.csdn.net/download/sq347216161/10308549)
1.1.上传jdk安装包
1.2.规划安装目录 ,解压到此目录 tar -zxvf jdk-7u45-linux-x64.tar.gz -C /usr/local/
1.3.设置环境变量:vi /etc/profile
#在文件最后添加
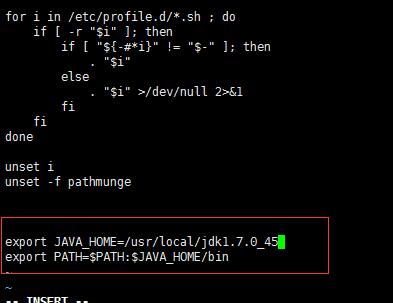
1.4.刷新环境变量配置:source /etc/profile
2.以hadoop用户为用户名登录
角色分配如下(hosts 映射好自己的ip和主机名):vi /etc/hosts

添加HADOOP用户:
useradd hadoop
passwd hadoop
为hadoop用户分配sudoer权限:vi /etc/sudoers
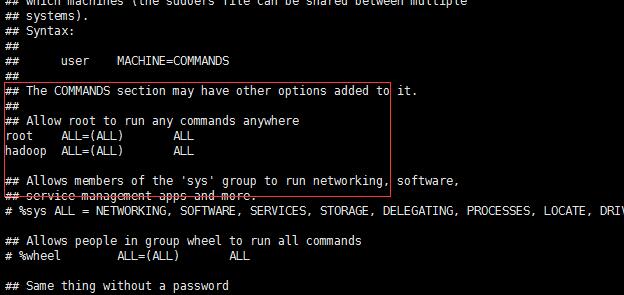
3.关闭防火墙
#查看防火墙状态:service iptables status
#关闭防火墙:service iptables stop
#查看防火墙开机启动状态:chkconfig iptables --list
#关闭防火墙开机启动:chkconfig iptables off
重启Linux :reboot
4.配置ssh免密登录(拷贝配置文件,以及后续hadoop集群批量启动会使用到):
ssh-keygen
ssh-copy-id hadoop4 (本机)
ssh-copy-id hadoop3
ssh-copy-id hadoop2
ssh-copy-id hadoop1
5.hadoop 环境 安装(hadoop 用户登录)
(以Centos 6.5 已经编译好的 安装包(centos-6.5-hadoop-2.6.4.tar.gz 下载地址: https://download.csdn.net/download/sq347216161/10308361)为例)
自己编译安装包方法教程文档: https://download.csdn.net/download/sq347216161/10308365
5.1 上传安装包 centos-6.5-hadoop-2.6.4.tar.gz
5.2 解压安装包
#创建文件夹: mkdir apps
#解压 tar -zxvf centos-6.5-hadoop-2.6.4.tar.gz -C apps/
5.3 修改配置文件(5个):
cd apps/hadoop-2.6.4/etc/hadoop/
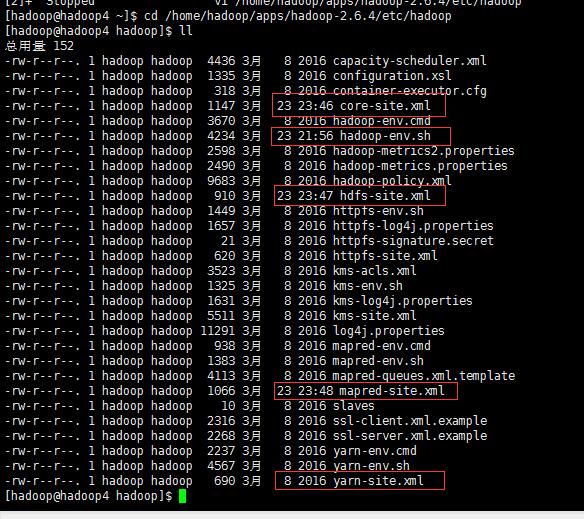
备注:mapred-site.xml 解压后原始名为:mapred-site.xml.template
改名:mv mapred-site.xml.template mapred-site.xml
5.3.1:vi hadoop-env.sh
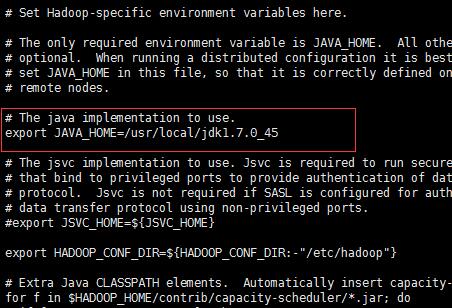
5.3.2: vi core-site.xml
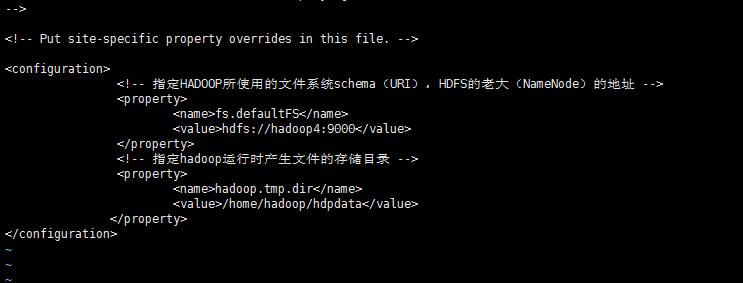
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop4:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
5.3.3:vi hdfs-site.xml
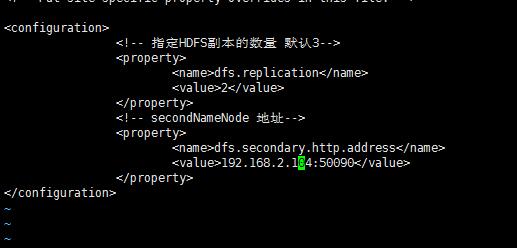
<!-- 指定HDFS副本的数量 默认3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- secondNameNode 地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.2.104:50090</value>
</property>
5.3.4:vi mapred-site.xml
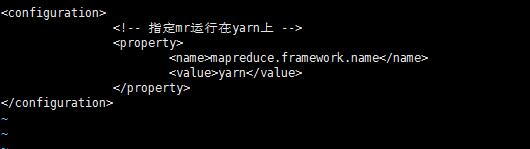
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5.3.5:vi yarn-site.xml
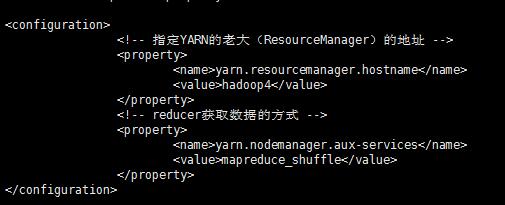
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop4</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
5.4 将hadoop添加到环境变量:vi /etc/profile
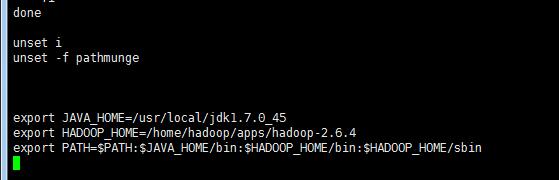
刷新环境变量配置:source /etc/profile
5.5 格式化namenode(是对namenode进行初始化):hadoop namenode -format
5.6 在其他机器上完成以上配置(4配置ssh免密登录不用),可以直接运用scp命令进行拷贝
5.7 配置hadoop集群启动: cd /home/hadoop/apps/hadoop-2.6.4/etc/hadoop
vi slaves

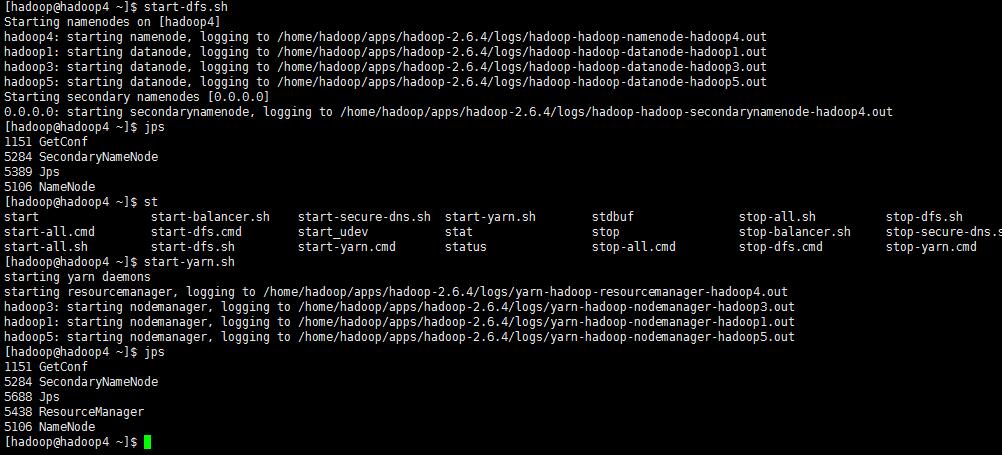
5.8 启动hadoop 集群
start-dfs.sh
start-yarn.sh
查看进程:jps
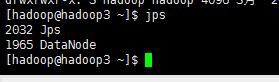
查看其他机器进程:jps
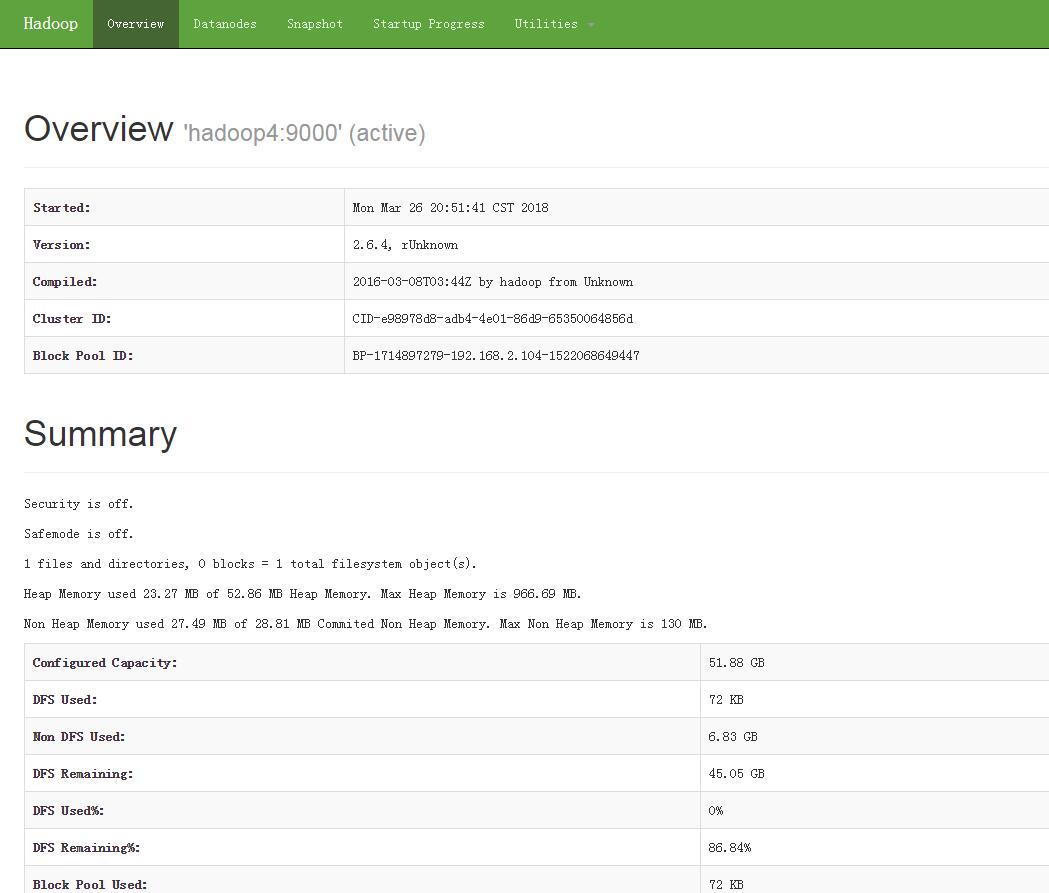
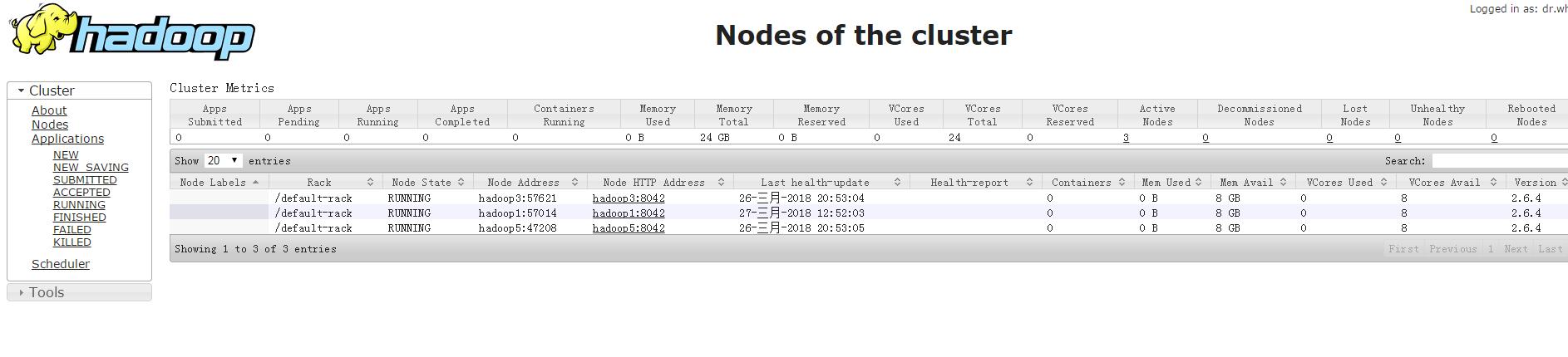
5.9 浏览器查看管理界面
http://hadoop4:50070/ (HDFS管理界面)
http://hadoop4:8088/ (MR管理界面)
1.JDK环境安装(jdk-7u45-linux-x64.tar.gz 为例 下载地址: https://download.csdn.net/download/sq347216161/10308549)
1.1.上传jdk安装包
1.2.规划安装目录 ,解压到此目录 tar -zxvf jdk-7u45-linux-x64.tar.gz -C /usr/local/
1.3.设置环境变量:vi /etc/profile
#在文件最后添加
1.4.刷新环境变量配置:source /etc/profile
1.5.检验jdk是否生效:java
2.以hadoop用户为用户名登录
角色分配如下(hosts 映射好自己的ip和主机名):vi /etc/hosts
添加HADOOP用户:
useradd hadoop
passwd hadoop
为hadoop用户分配sudoer权限:vi /etc/sudoers
3.关闭防火墙
#查看防火墙状态:service iptables status
#关闭防火墙:service iptables stop
#查看防火墙开机启动状态:chkconfig iptables --list
#关闭防火墙开机启动:chkconfig iptables off
重启Linux :reboot
4.配置ssh免密登录(拷贝配置文件,以及后续hadoop集群批量启动会使用到):
ssh-keygen
ssh-copy-id hadoop4 (本机)
ssh-copy-id hadoop3
ssh-copy-id hadoop2
ssh-copy-id hadoop1
5.hadoop 环境 安装(hadoop 用户登录)
(以Centos 6.5 已经编译好的 安装包(centos-6.5-hadoop-2.6.4.tar.gz 下载地址: https://download.csdn.net/download/sq347216161/10308361)为例)
自己编译安装包方法教程文档: https://download.csdn.net/download/sq347216161/10308365
5.1 上传安装包 centos-6.5-hadoop-2.6.4.tar.gz
5.2 解压安装包
#创建文件夹: mkdir apps
#解压 tar -zxvf centos-6.5-hadoop-2.6.4.tar.gz -C apps/
5.3 修改配置文件(5个):
cd apps/hadoop-2.6.4/etc/hadoop/
备注:mapred-site.xml 解压后原始名为:mapred-site.xml.template
改名:mv mapred-site.xml.template mapred-site.xml
5.3.1:vi hadoop-env.sh
5.3.2: vi core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop4:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
5.3.3:vi hdfs-site.xml
<!-- 指定HDFS副本的数量 默认3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- secondNameNode 地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.2.104:50090</value>
</property>
5.3.4:vi mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5.3.5:vi yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop4</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
5.4 将hadoop添加到环境变量:vi /etc/profile
刷新环境变量配置:source /etc/profile
5.5 格式化namenode(是对namenode进行初始化):hadoop namenode -format
5.6 在其他机器上完成以上配置(4配置ssh免密登录不用),可以直接运用scp命令进行拷贝
5.7 配置hadoop集群启动: cd /home/hadoop/apps/hadoop-2.6.4/etc/hadoop
vi slaves
5.8 启动hadoop 集群
start-dfs.sh
start-yarn.sh
查看进程:jps
查看其他机器进程:jps
5.9 浏览器查看管理界面
http://hadoop4:50070/ (HDFS管理界面)
http://hadoop4:8088/ (MR管理界面)