Hadoop集群部署
环境
VMware Workstation Pro:VMware 16.0 及以上版本
虚拟机镜像:CentOS-7-x86_64-Minimal-2009
JDK版本:jdk1.8.0_371
Hadoop版本:hadoop-3.3.6
Hadoop目录结构
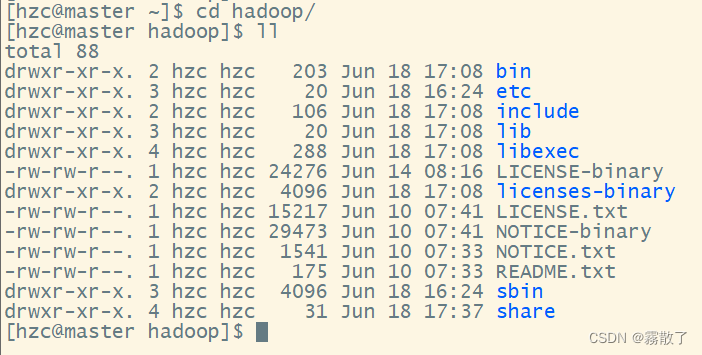
各个文件夹含义如下:
bin,存放Hadoop的各类程序 (命令)
etc,存放Hadoop的配置文件
include,C语言的一些头文件
lib,存放Linux系统的动态链接库 (.so文件)
libexec,存放配置Hadoop系统的脚本文件 (.sh和cmd)
licenses-binary,存放许可证文件
sbin.管理员程序 (super bin)
share,存放二进制源码 (Java jar包)
Hadoop集群规划
Hadoop 集群包含两个集群:HDFS 集群和 YARN 集群,两个集群在逻辑上是分离的,但在物理上是一起的。两个集群都是标准的主从架构的集群。
HDFS 集群有三个主要角色:主节点管理者 NameNode、从节点工作者 DataNode、主节点辅助 SecondaryNameNode。主管分布式存储

YARN 集群共有四个主要角色:集群资源管理者 ResourceManager、单机资源管理者 NodeManager,代理服务器提供安全性 ProxyServer 、记录历史信息和日志 JobHistoryServer。 主管资源管理和调度。
这里我们主要采用下面的集群规划:
| 节点 | 服务 |
|---|---|
| master | NameNode、SecondaryNameNode、DataNode、ResourceManager、NodeManager、ProxyServer 、JobHistoryServer |
| slave1 | DataNode、NodeManager |
| slave2 | DataNode、NodeManager |
Hadoop下载
Hadoop 下载会有两种不同的方法,可以使用 wget 指令进行下载,也可以使用 Xftp 等工具进行传输,具体情况看大家网络情况如何再进行决定。
下面将使用 wget 指令进行下载。
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz -P downloads/
下载的时候可能会有下面的报错,这个是一个证书过期的错误,这个错误很好解决,直接忽略证书检查即可,即在后面加上 --no-check-certificate。

wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz -P downloads/ --no-check-certificate
此时虽然还会显示警告,但是可以进行下载了,后面的 -P 选项是选择保存的路径,因为已经新建了一个 downloads 目录用于存储安装包,所以我这里后面直接加上了 downloads,表示存储在当前工作目录下的 downloads 目录下。

下载完后即可使用 ls 指令查看

Hadoop安装配置
解压
这里我们选择的安装路径为 /usr/local 目录下,方便以后得安装修改,在 /usr/local/ 目录下安装 Hadoop 是一种良好的做法,因为 /usr/local/ 通常用于存放用户自行安装的软件。将 Hadoop 安装在这个标准目录下,有助于统一管理和维护系统中的软件。
使用 tar 指令对 downloads 目录下的 hadoop-3.3.6.tar.gz 压缩包进行解压并存放到 /usr/local 目录下。这里需要使用到 sudo 指令提高权限。
sudo tar -zxf downloads/hadoop-3.3.6.tar.gz -C /usr/local/
文件夹重命名
对于安装 Hadoop 这类软件,将文件夹重命名并移动到指定目录是为了方便管理和使用。
- 易于识别和调用:
Hadoop官方发布的软件包文件夹名称通常是hadoop-x.x.x(其中 “x.x.x” 是版本号),这样的名称可能会随着不同版本的发布而不断变化。为了方便识别和调用,将文件夹重命名为hadoop(或其他合适的名称)有助于避免版本号等不稳定因素对后续操作造成混淆。- 方便使用环境变量: 将文件夹重命名为 “hadoop” 并将其移动到
/usr/local/hadoop目录下,可以方便地设置环境变量,例如在/etc/profile中配置Hadoop的路径。这样一来,您可以直接使用环境变量$HADOOP_HOME指代Hadoop的安装路径,而不需要担心具体的版本号。- 降低配置复杂性: 在
Hadoop配置文件中,有些属性会使用预定义的路径或文件夹名称,比如HADOOP_HOME。如果不将文件夹重命名为hadoop,您可能需要在配置文件中多处修改路径,增加了配置的复杂性。
虽然将文件夹重命名不是强制性的步骤,但它是一个良好的实践,能够使安装和管理 Hadoop 更加方便和清晰。同时,这也有助于减少潜在的错误和混淆,使整个过程更加流畅和可维护。
sudo mv /usr/local/hadoop-3.3.6/ /usr/local/hadoop # 将 /usr/local 目录下的 hadoop-3.3.6 重命名为 hadoop

赋予权限
将 Hadoop 的安装目录设置为普通用户所拥有的属主和属组是出于安全和权限管理的考虑。这样做有以下几个原因:
最小权限原则: 为了保护系统的安全性,最佳实践是使用最小权限原则。将
Hadoop安装目录的属主和属组设置为普通用户,可以限制对Hadoop文件和目录的访问权限,从而减少潜在的安全漏洞。安全隔离:
Hadoop是一个分布式系统,其中包含许多关键的配置文件、日志和数据目录。将Hadoop的属主和属组设置为普通用户,可以确保只有授权的用户能够访问和修改这些重要的资源,从而提高系统的安全性。避免使用 root 权限: 安装和运行
Hadoop不应该使用root用户权限,因为root用户拥有系统中最高的权限,一旦出现问题,可能会导致系统的不稳定甚至崩溃。通过将Hadoop的属主和属组设置为普通用户,可以避免使用root权限,并降低系统被不必要的风险所影响的可能性。易于管理: 将
Hadoop的属主和属组设置为普通用户有助于简化管理。例如,在团队合作中,每个成员都可以拥有自己的普通用户账户,并且可以根据需要授予特定用户访问权限,而无需共享 root 用户密码。
在将 Hadoop 的属主和属组设置为普通用户之前,确保这些用户具有所需的权限,并且能够正常访问安装目录和相关资源。这样做可以帮助确保系统的安全性和稳定性,同时方便团队合作和权限管理。
sudo chown -R hzc:hzc /usr/local/hadoop/ # 将 /usr/local/ 下的 hadoop 目录及其子文件的所有者和所有组更改为hzc。
设置软连接
在构建软连接(符号链接)从用户目录指向 Hadoop 安装目录时,可以获得以下几个好处:
- 简化路径访问: Hadoop 的安装目录可能位于系统中的某个固定位置,而用户在日常操作中可能需要频繁访问 Hadoop 相关文件或执行 Hadoop 相关命令。通过在用户目录创建软连接指向 Hadoop 安装目录,用户可以简化访问路径,使得操作更加方便。
- 不受 Hadoop 安装目录变化影响: 如果 Hadoop 安装目录由于版本升级或其他原因而发生变化,软连接仍然指向原来的路径。这样,在 Hadoop 升级或迁移时,用户无需手动修改路径,软连接会自动指向新的 Hadoop 安装目录。
- 用户私有定制: 每个用户可能都有不同的 Hadoop 配置和环境需求。通过在用户目录创建软连接,用户可以针对自己的需求对 Hadoop 进行私有定制,而不会影响其他用户的配置。
- 安全隔离: 在共享环境中,每个用户可能有不同的权限要求,通过软连接,可以确保用户只能访问他们具有权限的 Hadoop 相关资源,而不能访问其他用户的资源。
- 避免权限问题: 将软连接创建在用户目录下,可以避免需要在全局范围内设置权限。用户可以在自己的目录下创建软连接,而不需要特殊的管理员权限。
创建软连接的步骤如下,将 Hadoop 安装目录链接到用户目录
# 进入用户目录
cd
# 创建软连接
ln -s /usr/local/hadoop hadoop
请确保 /usr/local/hadoop 是 Hadoop 的实际安装目录,而 /home/your_username 是您的用户目录。
需要注意的是,软连接只是一个指向目标的快捷方式,并不复制目标文件或目录,因此不会占用额外的磁盘空间。软连接的权限由目标文件或目录决定,即使软连接的创建者没有访问权限,只要目标文件或目录对该用户可见,软连接也可以使用。
总的来说,通过在用户目录创建软连接指向 Hadoop 安装目录,可以提高用户操作的便利性,方便管理和维护,并允许用户在共享环境中进行个性化的配置和定制。

配置环境变量
配置环境变量是为了方便系统中的各种应用程序和用户,在运行过程中能够快速访问特定的可执行文件、库文件、配置文件等资源。环境变量在操作系统中起到了重要的作用,以下是需要配置环境变量的几个主要原因:
快速访问可执行文件: 环境变量中包含了系统中常用的可执行文件的路径,这样用户在终端或命令行中可以直接输入命令名称,而无需指定完整的文件路径。例如,配置了
Java的环境变量后,用户可以直接运行java命令,而不必输入完整的Java可执行文件路径。共享重要路径: 环境变量的配置可以实现路径的共享和统一管理。对于一些常用的软件或工具,将其安装路径添加到环境变量中,所有用户和应用程序都可以方便地访问,而无需每次都指定完整路径。
简化配置: 某些应用程序可能需要引用一些共享的配置文件或数据文件,通过环境变量配置这些文件的路径,可以使配置过程更简洁,易于维护。
避免重复设置: 通过配置环境变量,可以避免在不同的应用程序中重复设置相同的路径信息,从而减少了配置文件的冗余,提高了系统的整洁性。
方便切换版本: 在有多个版本的软件或工具时,可以通过环境变量快速切换使用不同版本。只需要更改环境变量指向的路径,即可切换到不同的软件版本,而不需要修改每个应用程序的配置。
在安装和配置大型软件,如 Hadoop、Java、Python 等,配置环境变量是一个常见的步骤。对于 Hadoop 来说,配置 HADOOP_HOME 和 PATH 等环境变量可以使用户和系统在运行 Hadoop 相关命令时更加便捷,简化操作,提高效率。
vim ~/.bashrc # 修改当前用户环境变量
追加下面内容:
#Hadoop
export HADOOP_HOME=/usr/local/hadoop # 输入Hadoop的安装目录
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出后输入下面指令重新加载环境变量
source ~/.bashrc # 重新加载环境变量
配置文件修改
配置 HDFS 集群,我们主要涉及到如下文件的修改:
workers:配置从节点(DataNode)有哪些
hadoop-env.sh:配置Hadoop的相关环境变量
core-site.xml:Hadoop核心配置文件
hdfs-site.xml:HDFS核心配置文件
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
配置 YARN集群,我们主要设涉及如下文件修改:
mapreduce-site.xml:MapReduce核心配置文件
yarn-site.xml:YARN核心配置文件这些文件均存在与
$HADOOP_HOME/etc/hadoop文件夹中。
HDFS集群
workers
在 Hadoop 集群中,workers 文件是用于配置数据节点(DataNode)的文件。每个数据节点都在这个文件中列出,Hadoop 的启动脚本会根据这个文件来识别哪些节点将作为数据节点参与分布式存储和计算。
需要修改 workers 文件的主要原因有以下几点:
标识数据节点: workers 文件的作用是用来标识哪些机器是数据节点,即存储实际数据的节点。通过修改 workers 文件,您可以明确指定哪些机器应该被作为数据节点加入到 Hadoop 集群中。
调整集群规模: 随着集群规模的变化,您可能需要调整数据节点的数量。通过修改 workers 文件,您可以添加或移除数据节点,从而动态地调整集群的规模。
分布式计算: Hadoop 是一个分布式计算框架,数据节点负责存储和处理数据块。通过修改 workers 文件,您可以确保数据在多个节点上分布,从而实现并行处理和负载均衡。
故障恢复: 当某个数据节点出现故障时,您可能需要将该节点从 workers 文件中移除,避免数据节点列表中包含已经不可用的节点,以保证系统的可靠性。
修改 workers 文件的步骤如下:
-
打开 workers 文件:使用文本编辑器(如
vi、vim、nano或gedit)打开Hadoop安装目录下的workers文件。vim $HADOOP_HOME/etc/hadoop/workers # 编辑workers文件 -
添加或删除节点:在文件中添加或删除要作为数据节点的主机名或 IP 地址,每行一个节点。
master slave1 slave2 -
保存文件:保存修改后的 workers 文件。
:wq -
分发文件:将修改后的
workers文件拷贝到所有的Hadoop节点上,确保每个节点都使用相同的 workers 文件配置。scp -r $HADOOP_HOME/hadoop/etc/workers slave1:$HADOOP_HOME/hadoop/etc/workers scp -r $HADOOP_HOME/hadoop/etc/workers slave2:$HADOOP_HOME/hadoop/etc/workers -
重新启动 Hadoop:在修改了 workers 文件后,需要重新启动 Hadoop 集群,以使新的配置生效。
stop-hdfs.sh start-hdfs.sh
请注意,在修改 workers 文件后,确保新的节点符合 Hadoop 集群的硬件和网络要求,以免影响整个集群的性能和稳定性。
总结来说,修改 workers 文件是为了明确指定数据节点,调整集群规模,实现分布式计算和故障恢复。通过正确配置 workers 文件,可以确保 Hadoop 集群正常运行,并充分利用集群中的计算和存储资源。
hadoop-env.sh
hadoop-env.sh 是 Hadoop 的环境配置脚本,用于设置 Hadoop 各个组件运行所需的环境变量和其他参数。需要修改 hadoop-env.sh 文件的主要原因如下:
Java 环境设置:
hadoop-env.sh文件中定义了Hadoop使用的Java环境变量,例如JAVA_HOME和HADOOP_CLASSPATH。通过修改这些变量,您可以指定Hadoop使用的特定 Java 安装路径和类路径,确保Hadoop正确地运行在您期望的Java环境下。内存设置:
Hadoop的各个组件在运行时可能需要分配一定的内存,hadoop-env.sh中定义了用于控制这些内存设置的环境变量,如HADOOP_HEAPSIZE、HADOOP_NAMENODE_OPTS、HADOOP_DATANODE_OPTS等。通过修改这些变量,您可以根据集群的硬件配置和应用场景来调整Hadoop的内存分配策略。优化 JVM 参数:
JVM的参数设置对于Hadoop集群的性能至关重要。hadoop-env.sh中的一些环境变量允许您设置JVM参数,如HADOOP_OPTS和HADOOP_CLIENT_OPTS。通过调整这些参数,您可以优化JVM的性能,提高Hadoop集群的整体性能。其他环境变量:
hadoop-env.sh文件还可以设置其他一些重要的环境变量,例如HADOOP_LOG_DIR、HADOOP_PID_DIR、HADOOP_IDENT_STRING等。这些变量对于Hadoop各个组件的日志、进程管理和标识都非常重要。自定义变量: 您可以在
hadoop-env.sh文件中添加自定义的环境变量,以满足特定的需求。这样,您可以方便地在脚本中使用这些自定义变量,而不需要在每个组件的启动脚本中重复定义。
修改 hadoop-env.sh 文件的步骤如下:
-
打开
hadoop-env.sh文件:找到Hadoop安装目录下的etc/hadoop/hadoop-env.sh文件。cd $HADOOP_HOME/etc/hadoop/ -
编辑文件:使用文本编辑器(如
vi、vim、nano或gedit)打开hadoop-env.sh文件。vim hadoop-env.sh -
修改环境变量:根据需要,修改相关的环境变量值或添加新的环境变量。
下面我们需要修改文件中四个环境变量,可以直接进行追加,也可以找到对应位置,把
#删去,再修改变量的值。export JAVA_HOME=/usr/local/jvm/jdk1.8.0_371 export HADOOP_HOME=/usr/local/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_LOG_DIR=$HADOOP_HOME/logs -
保存文件:保存修改后的
hadoop-env.sh文件。:wq -
分发文件:将修改后的
hadoop-env.sh文件拷贝到所有的Hadoop节点上,确保每个节点都使用相同的配置。scp -r $HADOOP_HOME/hadoop/etc/hadoop-env.sh slave1:$HADOOP_HOME/hadoop/etc/ scp -r $HADOOP_HOME/hadoop/etc/hadoop-env.shs slave2:$HADOOP_HOME/hadoop/etc/ -
重启
Hadoop:在修改了hadoop-env.sh文件后,需要重新启动Hadoop集群,以使新的配置生效。stop-hdfs.sh start-hdfs.sh
总结来说,修改 hadoop-env.sh 文件是为了配置 Hadoop 各个组件的环境变量,设置 Java 环境、调整内存分配、优化 JVM 参数等。通过正确配置 hadoop-env.sh 文件,可以实现对 Hadoop 集群运行环境的定制,满足不同的应用需求,提高集群的性能和可靠性。
core-site.xml
在 Hadoop 集群中,core-site.xml 是 Hadoop 核心配置文件之一,它包含了一些重要的全局配置属性,影响着 Hadoop 分布式文件系统 (HDFS) 和 Hadoop MapReduce 的行为。需要修改 core-site.xml 文件的主要原因如下:
指定默认文件系统: 在
core-site.xml中,有一个重要的属性是fs.defaultFS。这个属性用于指定Hadoop集群的默认文件系统的 URI(Uniform Resource Identifier),即HDFS的访问地址。通过修改这个属性,您可以指定Hadoop集群中默认的文件系统,例如:“hdfs://namenode:8020”。配置数据目录:
core-site.xml中的hadoop.tmp.dir属性用于配置Hadoop运行时产生的临时文件和目录的存储位置。您可以根据实际需求,设置这个属性指向一个适当的目录,以确保有足够的磁盘空间和性能来处理临时数据。开启跨域访问:
Hadoop集群中的各个组件可能会运行在不同的机器上,为了实现跨域访问,需要修改 core-site.xml 中的 hadoop.proxyuser.* 属性。通过配置这些属性,可以允许特定用户从远程机器上访问集群中的服务,实现安全的跨域访问。配置数据副本数:
core-site.xml中的dfs.replication属性用于配置HDFS存储的数据副本数。通过修改这个属性,您可以设置HDFS中数据块的冗余副本数,以提高数据的可靠性和容错性。设置权限检查级别:
core-site.xml中的dfs.permissions.enabled属性用于开启或关闭HDFS的权限检查功能。通过修改这个属性,可以调整HDFS对文件和目录访问权限的检查级别。配置日志目录:
Hadoop在运行过程中会产生大量日志,core-site.xml中的hadoop.log.dir属性用于配置Hadoop日志文件的存储位置。通过修改这个属性,您可以将Hadoop日志文件保存在指定的目录,方便日后排查问题。
修改 core-site.xml 文件的步骤如下:
-
打开
core-site.xml文件:找到Hadoop安装目录下的etc/hadoop/core-site.xml文件。cd $HADOOP_HOME/etc/hadoop/ -
编辑文件:使用文本编辑器(如
vi、vim、nano或 gedit)打开 core-site.xml 文件。vim core-site.xml -
修改属性:根据需要,修改相关的属性值。
fs.defaultFS: 默认文件系统的名称。一个 URI,其方案和权限决定了文件系统的实现。uri 的方案决定了命名 FileSystem 实现类的配置属性 (fs.SCHEME.impl)。uri 的权限用于确定文件系统的主机、端口等。默认值:file:///,这里我们将其设置为在master下的8020端口io.file.buffer.size:序列文件中使用的缓冲区的大小。该缓冲区的大小可能应该是硬件页面大小的倍数(Intel x86 上为 4096),并且它决定在读写操作期间缓冲多少数据。默认值:4096,这里我们将其设置为131072,单位为bit。<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration> -
保存文件:保存修改后的
core-site.xml文件。:wq -
分发文件:将修改后的
core-site.xml文件拷贝到所有的Hadoop节点上,确保每个节点都使用相同的配置。scp -r $HADOOP_HOME/hadoop/etc/core-site.xml slave1:$HADOOP_HOME/hadoop/etc/ scp -r $HADOOP_HOME/hadoop/etc/core-site.xml slave2:$HADOOP_HOME/hadoop/etc/ -
重启
Hadoop:在修改了 core-site.xml 文件后,需要重新启动Hadoop集群,以使新的配置生效。stop-hdfs.sh start-hdfs.sh
总结来说,修改 core-site.xml 文件是为了配置 Hadoop 的全局属性,指定默认文件系统、配置数据目录、设置权限检查级别、配置数据副本数等。通过正确配置 core-site.xml 文件,可以影响 Hadoop 集群的行为和性能,满足实际需求,并提高系统的可靠性和性能。
hdfs-site.xml
在 Hadoop 集群中,hdfs-site.xml 是 Hadoop 分布式文件系统 (HDFS) 的配置文件,它包含了一些关键的属性,用于配置 HDFS 的行为和特性。需要修改 hdfs-site.xml 文件的主要原因如下:
数据副本数:
hdfs-site.xml中的dfs.replication属性用于配置HDFS存储的数据副本数。通过修改这个属性,您可以设置HDFS中数据块的冗余副本数,以提高数据的可靠性和容错性。这是保证数据持久性和容错性的关键配置。块大小:
hdfs-site.xml中的dfs.blocksize属性用于配置HDFS数据块的大小,默认情况下为 128 MB。通过修改这个属性,您可以调整数据块的大小,以适应不同大小的数据和存储设备。数据节点和名称节点目录:
hdfs-site.xml中的dfs.datanode.data.dir和dfs.namenode.name.dir属性分别用于配置数据节点(DataNode)和名称节点(NameNode)的数据目录。通过修改这些属性,您可以指定数据节点和名称节点存储数据和元数据的位置。文件系统权限:
hdfs-site.xml 中的dfs.permissions.enabled和dfs.permissions.superusergroup属性用于配置HDFS的权限检查功能。通过修改这些属性,可以开启或关闭HDFS对文件和目录访问权限的检查,以及设置超级用户组。数据节点心跳和块报告频率:
hdfs-site.xml中的dfs.heartbeat.interval和dfs.blockreport.intervalMsec属性用于配置数据节点向名称节点发送心跳和块报告的频率。通过修改这些属性,可以调整数据节点与名称节点的通信频率,以适应不同的网络环境和节点数量。数据节点同步频率:
hdfs-site.xml中的dfs.datanode.synconclose属性用于配置数据节点在关闭文件时是否将未同步的数据块强制同步到名称节点。通过修改这个属性,可以影响数据节点关闭文件的行为。
修改 hdfs-site.xml 文件的步骤如下:
-
打开
hdfs-site.xml文件:找到Hadoop安装目录下的etc/hadoop/hdfs-site.xml文件。cd $HADOOP_HOME/etc/hadoop/ -
编辑文件:使用文本编辑器(如
vi、vim、nano或gedit)打开hdfs-site.xml文件。vim hdfs-site.xml -
修改属性:根据需要,修改相关的属性值。
dfs.datanode.data.dir.perm:DFS 数据节点存储其块的本地文件系统上的目录的权限。权限可以是八进制或符号。默认值:700dfs.namenode.name.dir:确定 DFS 名称节点应在本地文件系统上的何处存储名称表 (fsimage)。如果这是逗号分隔的目录列表,则名称表将复制到所有目录中,以实现冗余。默认值:file://${hadoop.tmp.dir}/dfs/namedfs.datanode.data.dir:确定 DFS 数据节点应在本地文件系统上的何处存储其块。如果这是一个以逗号分隔的目录列表,则数据将存储在所有命名目录中,通常位于不同的设备上。目录应标记相应的存储类型([SSD]/[DISK]/[ARCHIVE]/[RAM_DISK])以实现 HDFS 存储策略。如果目录没有显式标记的存储类型,则默认存储类型将为 DISK。如果本地文件系统权限允许,将创建不存在的目录。默认值:file://${hadoop.tmp.dir}/dfs/datadfs.datanode.data.dir.perm:DFS 数据节点存储其块的本地文件系统上的目录的权限。权限可以是八进制或符号。默认值:700dfs.blocksize: 新文件的默认块大小(以字节为单位)。您可以使用以下后缀(不区分大小写):k(kilo)、m(mega)、g(giga)、t(tera)、p(peta)、e(exa) 来指定大小(例如 128k、512m) 、1g 等),或提供以字节为单位的完整大小(例如 134217728 表示 128 MB)。默认值:134217728,这里我们设置为:268435456(256MB)dfs.namenode.handler.count:监听客户端请求的Namenode RPC服务器线程数。如果未配置 dfs.namenode.servicerpc-address ,则 Namenode RPC 服务器线程侦听来自所有节点的请求。默认值:10,这里我们设置为100,提高并发线程数。<configuration> <property> <name>dfs.datanode.data.dir.perm</name> <value>700</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop/data/nn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop/data/dn</value> </property> <property> <name>dfs.datanode.data.dir.perm</name> <value>700</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> </property> </configuration> -
保存文件:保存修改后的
hdfs-site.xml文件。:wq -
分发文件:将修改后的
hdfs-site.xml文件拷贝到所有的Hadoop节点上,确保每个节点都使用相同的配置。scp -r $HADOOP_HOME/hadoop/etc/hdfs-site.xml slave1:$HADOOP_HOME/hadoop/etc/ scp -r $HADOOP_HOME/hadoop/etc/hdfs-site.xml slave2:$HADOOP_HOME/hadoop/etc/ -
重启
Hadoop:在修改了hdfs-site.xml文件后,需要重新启动Hadoop集群,以使新的配置生效。stop-hdfs.sh start-hdfs.sh
总结来说,修改 hdfs-site.xml 文件是为了配置 HDFS 的行为和特性,设置数据副本数、块大小、数据节点和名称节点目录、文件系统权限等。通过正确配置 hdfs-site.xml 文件,可以满足不同需求下对 HDFS 的存储和访问要求,保障数据的安全性和可靠性,并提高 HDFS 集群的性能和效率。
YARN集群
mapred-env.sh(可选配置)
这里我们设置俩参数:
HADOOP_JOB_HISTORYSERVER_HEAPSIZE: JobHistoryServer 的进程内存,这里我们设置为 1000(1G)。
HADOOP_JHS_LOGGER :日志级别,这里我们设置为 INFO,RFA
export JAVA_HOME=/usr/local/jvm/jdk1.8.0_371
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_JHS_LOGGER=INFO,RFA
这里的配置可以不做,也可以去了解一下这个配置文件然后根据自身情况自行配置。
yarn-env.sh(可选配置)
export JAVA_HOME=/usr/local/jvm/jdk1.8.0_371
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
mapreduce-site.xml
在 Hadoop 集群中,mapred-site.xml 是 Hadoop MapReduce 的配置文件,用于配置 MapReduce 框架的行为和特性。需要修改 mapred-site.xml 文件的主要原因如下:
设置作业调度器:
mapred-site.xml中的mapreduce.framework.name属性用于配置作业调度器。通过修改这个属性,可以选择使用 YARN 或者经典的MapReduce作业调度器(Classic MapReduce)来执行作业。调整任务并发数:
mapred-site.xml中的mapreduce.jobtracker.handler.count和mapreduce.tasktracker.reduce.tasks.maximum属性用于调整作业跟踪器(JobTracker)和任务跟踪器(TaskTracker)的并发数。通过修改这些属性,可以根据集群的规模和性能调整并发任务的数量。配置任务重试次数:
mapred-site.xml中的mapreduce.map/reduce.maxattempts属性用于配置任务的最大重试次数。通过修改这些属性,可以调整任务失败后的重试行为,以增强作业的容错性。自定义输出压缩:
mapred-site.xml中的mapreduce.output.fileoutputformat.compress和mapreduce.output.fileoutputformat.compress.codec属性用于配置输出结果的压缩方式和压缩编解码器。通过修改这些属性,可以选择输出结果是否进行压缩以及压缩的编解码器。调整 Shuffle 阶段参数:
mapred-site.xml中的mapreduce.task.io.sort.mb和mapreduce.reduce.shuffle.input.buffer.percent属性用于调整 Shuffle 阶段的内存占用和缓冲区配置。通过修改这些属性,可以优化 Shuffle 阶段的性能和效率。启用任务跟踪器数据本地化:
mapred-site.xml中的mapreduce.tasktracker.cache.local.enable属性用于配置是否启用任务跟踪器的数据本地化功能。通过修改这个属性,可以决定是否将作业使用的数据本地化到任务跟踪器节点上,以减少数据网络传输开销。
修改 mapred-site.xml 文件的步骤如下:
-
打开
mapred-site.xml文件:找到Hadoop安装目录下的etc/hadoop/mapred-site.xml文件。cd $HADOOP_HOME/etc/hadoop/ -
编辑文件:使用文本编辑器(如
vi、vim、nano或gedit)打开mapred-site.xml文件。vim mapreduce-site.xml -
修改属性:根据需要,修改相关的属性值。
mapreduce.framework.name:用于执行 MapReduce 作业的运行时框架。可以是lcoal、classic或yarn之一。默认值:lcoal,这里设置为yarn。mapreduce.jobhistory.address:历史服务器的通讯端口,默认值:0.0.0.0:10020,这里我们设置为master:10020mapreduce.jobhistory.webapp.address:历史服务器的Web端通讯端口,默认值:0.0.0.0:19888,这里设置为master:19888mapreduce.jobhistory.intermediate-done-dir:历史信息在HDFS中的临时记录路径,默认值:${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate,这里设置为file:///usr/local/hadoop/data/mr-history/tmpmapreduce.jobhistory.done-dir:历史信息在HDFS中的记录路径,默认值:${yarn.app.mapreduce.am.staging-dir}/history/done,这里设置为file:///usr/local/hadoop/data/mr-history/doneyarn.app.mapreduce.am.env:用户为MR App Master过程添加了环境变量,指定为逗号分隔列表。示例:1)A=foo这将设置env变量A为foo 2)B= B : c 这是继承 t a s k t r a c k e r 的 B e n v 变量。要单独定义环境变量,可以指定多个属性,格式为 y a r n . a p p . m a p r e d u c e . a m . e n v . V A R N A M E ,其中 V A R N A M E 是环境变量的名称。这是当变量的值包含逗号时添加变量的唯一方法。这里我们设置为 ‘ H A D O O P M A P R E D H O M E = B:c这是继承tasktracker的B env变量。要单独定义环境变量,可以指定多个属性,格式为yarn.app.mapreduce.am.env.VARNAME,其中VARNAME是环境变量的名称。这是当变量的值包含逗号时添加变量的唯一方法。这里我们设置为 `HADOOP_MAPRED_HOME= B:c这是继承tasktracker的Benv变量。要单独定义环境变量,可以指定多个属性,格式为yarn.app.mapreduce.am.env.VARNAME,其中VARNAME是环境变量的名称。这是当变量的值包含逗号时添加变量的唯一方法。这里我们设置为‘HADOOPMAPREDHOME=HADOOP_HOME`mapreduce.map.env、mapreduce.reduce.env:为 Map 任务和 Reduce 用户设置环境变量。MapReduce的环境变量。这里设置为Hadoop的安装目录。<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>执行 MapReduce 作业的运行时框架</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> <description>历史服务器的通讯端口</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> <description>历史服务器的 Web 端通讯端口</description> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>file:///usr/local/hadoop/data/mr-history/tmp</value> <description>历史信息在 HDFS 中的临时记录路径</description> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>file:///usr/local/hadoop/data/mr-history/done</value> <description>历史信息在 HDFS 中的记录路径</description> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> <description></description> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> <description></description> </property> </configuration> -
保存文件:保存修改后的
mapred-site.xml文件。:wq -
分发文件:将修改后的
mapred-site.xml文件拷贝到所有的Hadoop节点上,确保每个节点都使用相同的配置。scp -r $HADOOP_HOME/hadoop/etc/mapred-site.xml slave1:$HADOOP_HOME/hadoop/etc/ scp -r $HADOOP_HOME/hadoop/etc/mapred-site.xml slave2:$HADOOP_HOME/hadoop/etc/ -
重启
Hadoop:在修改了mapred-site.xml文件后,需要重新启动Hadoop集群,以使新的配置生效。stop-yarn.sh start-yarn.sh
总结来说,修改 mapred-site.xml 文件是为了配置 Hadoop MapReduce 框架的行为和特性,选择作业调度器、调整任务并发数、设置任务重试次数、自定义输出压缩等。通过正确配置 mapred-site.xml 文件,可以优化作业的执行和性能,满足不同应用场景下的需求。
yarn-site.xml
在 Hadoop 集群中,yarn-site.xml 是 YARN(Yet Another Resource Negotiator)的配置文件,用于配置 Hadoop 集群的资源管理和任务调度。需要修改 yarn-site.xml 文件的主要原因如下:
配置资源管理器地址:
yarn-site.xml中的yarn.resourcemanager.address和yarn.resourcemanager.scheduler.address属性用于配置资源管理器(ResourceManager)和调度器(Scheduler)的地址。通过修改这些属性,可以指定ResourceManager和调度器监听的地址,以便应用程序和客户端能够连接到正确的资源管理器和调度器。调整节点管理器心跳和资源请求频率:
yarn-site.xml中的yarn.nodemanager.heartbeat.interval-ms和yarn.client.app-submission.poll-interval-ms属性用于调整节点管理器(NodeManager)发送心跳和资源请求的频率。通过修改这些属性,可以优化集群资源管理和任务调度的性能。设置任务容器的最大和最小资源:
yarn-site.xml中的yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb属性用于设置单个任务容器的最大和最小资源分配。通过修改这些属性,可以限制任务的资源使用,避免过度占用集群资源。启用跨站点高可用性:
yarn-site.xml中的yarn.resourcemanager.ha.enabled属性用于配置是否启用ResourceManager的跨站点高可用性。通过修改这个属性,并配置ResourceManager的多个实例,可以提高ResourceManager的可用性,确保集群的稳定性。配置本地资源优先级:
yarn-site.xml中的yarn.nodemanager.localizer.cache.target-size-mb属性用于配置本地资源(如文件、库等)的缓存大小。通过修改这个属性,可以调整本地资源缓存的大小,以提高本地资源的访问效率。启用容器日志聚合:
yarn-site.xml中的yarn.log-aggregation-enable属性用于配置是否启用容器日志的聚合。通过修改这个属性,可以决定是否将容器的日志聚合到一个统一的位置,方便后续的日志管理和分析。
修改 yarn-site.xml 文件的步骤如下:
-
打开
yarn-site.xml文件:找到Hadoop安装目录下的etc/hadoop/yarn-site.xml文件。cd $HADOOP_HOME/etc/hadoop/ -
编辑文件:使用文本编辑器(如
vi、vim、nano或gedit)打开yarn-site.xml文件。vim yarn-site.xml -
修改属性:根据需要,修改相关的属性值。
yarn.resourcemanager.hostname:ResourceManager运行的主机名称,默认值:0.0.0.0,这里我们设置为masteryarn.nodemanager.local-dirs: 存储本地化文件的目录列表。应用程序的本地化文件目录位于:${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}。单个容器的工作目录,称为container_${contid},将是它的子目录。默认值:${hadoop.tmp.dir}/nm-local-dir。这里设置为file:///usr/local/hadoop/data/nm-localyarn.nodemanager.log-dirs:存放集装箱日志的位置。应用程序的本地化日志目录将在${yarn. nodemerator.log-dirs}/application_${appid}中找到。单个容器的日志目录将位于此目录之下,位于名为container_{$contid}的目录中。每个容器目录将包含由该容器生成的文件stderr、stdin和syslog。默认值:${yarn.log.dir}/userlogs,这里设置为file:///usr/local/hadoop/data/nm-logsyarn.nodemanager.aux-services:以逗号分隔的服务列表,其中服务名称应仅包含a-zA-Z 0 -9_且不能以数字开头。这里设置为mapreduce_shuffleyarn.log.server.url:历史日志聚合服务器的URL,这里设置为http://master:19888/jobhistory/logsyarn.web-proxy.address:Web代理的地址为HOST:PORT,如果未指定,则代理将作为ResourceManager的一部分运行,这里设置为master:8089yarn.log-aggregation-enable:是否启用日志聚合。日志聚合收集每个容器的日志并将这些日志移动到文件系统上,例如HDFS,应用程序完成后。用户可以配置“yarn.nodemanager.remote-app-log-dir”和“yarn.nodemanager.remote-app-log-dir-suffix”属性来确定这些日志移动到的位置。用户可以通过Application时间轴Server访问日志。默认值:false,这里设置为trueyarn.nodemanager.remote-app-log-dir:日志聚合的存储路径。默认值:/ tmp/logs,这里设置为file:///usr/local/hadoop/tmp/logsyarn.resourcemanager.scheduler.class:用作资源计划程序的类。默认值:org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler,这里设置为org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> <description></description> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>file:///usr/local/hadoop/data/nm-local</value> <description>NodeManager中间数据的本地存储路径</description> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>file:///usr/local/hadoop/data/nm-logs</value> <description>NodeManager数据日志本地保存路径</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>开启 shuffle 服务</description> </property> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs</value> <description>历史日志服务器的 url</description> </property> <property> <name>yarn.web-proxy.address</name> <value>master:8089</value> <description>代理服务器主机和端口</description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>开启日志聚合</description> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>file:///usr/local/hadoop/tmp/logs</value> <description>程序日志 HDFS 存储路径</description> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>选择公平调度器</description> </property> </configuration> -
保存文件:保存修改后的
yarn-site.xml文件。:wq -
分发文件:将修改后的
yarn-site.xml文件拷贝到所有的Hadoop节点上,确保每个节点都使用相同的配置。scp -r $HADOOP_HOME/hadoop/etc/yarn-site.xml slave1:$HADOOP_HOME/hadoop/etc/ scp -r $HADOOP_HOME/hadoop/etc/yarn-site.xml slave2:$HADOOP_HOME/hadoop/etc/ -
重启 Hadoop:在修改了 yarn-site.xml 文件后,需要重新启动 Hadoop 集群,以使新的配置生效。
stop-yarn.sh start-yarn.sh
总结来说,修改 yarn-site.xml 文件是为了配置 Hadoop 集群的资源管理和任务调度,设置资源管理器地址、调整心跳和资源请求频率、配置任务容器资源等。通过正确配置 yarn-site.xml 文件,可以优化集群的资源利用率和任务调度性能,提高集群的稳定性和可靠性。
部署启动
格式化HDFS
格式化 HDFS 是在部署或重新启动 Hadoop 集群之前的一个必要步骤。它会创建 HDFS 的初始目录结构,并在文件系统的 NameNode 上建立起必要的元数据信息。格式化 HDFS 的主要原因和作用如下:
创建命名空间:
HDFS是一个分布式文件系统,它的文件和目录都存储在NameNode上的命名空间中。在格式化HDFS之前,这个命名空间是不存在的。通过格式化HDFS,会创建一个全新的命名空间,从而确保集群的文件系统处于一个干净、初始的状态。建立元数据信息:
HDFS的元数据信息,如文件和目录的层次结构、文件块的位置、权限设置等,都存储在NameNode上。格式化HDFS会清空之前的元数据信息并重新建立起一个空的NameNode元数据数据库,以备集群重新启动时使用。清除之前的数据: 在格式化
HDFS过程中,之前存储在HDFS中的数据也会被删除。这是因为HDFS的设计目标之一是高容错性,为了确保文件系统处于可靠的状态,格式化会清空之前的数据,让集群处于一个空白的状态。确保一致性:
Hadoop集群中有多个数据节点(DataNode),它们存储着HDFS中的数据块。在某些情况下,如果某个数据节点的数据损坏或不一致,会导致HDFS的可靠性问题。通过格式化HDFS,可以确保所有数据节点中的数据一致,并且从头开始建立数据副本,确保数据的一致性和完整性。
需要特别注意的是,格式化 HDFS 是一个不可逆的操作。一旦执行格式化操作,之前存储在 HDFS 中的所有数据都将被删除。因此,在进行 HDFS 格式化之前,务必备份重要的数据,并确保已经完成必要的数据迁移和数据备份工作。
格式化 HDFS 的具体步骤通常是通过执行 Hadoop 的 hdfs namenode -format 命令来实现。执行格式化操作后,建议对集群进行全面测试,确保 HDFS 和集群的其他组件正常运行,并可以正确地处理和存储数据。
总结来说,格式化 HDFS 是为了创建命名空间、建立元数据信息、清除之前的数据、确保一致性,以及确保 Hadoop 集群从一个干净、初始的状态开始运行。这是部署或重新启动 Hadoop 集群的必要步骤,但需要谨慎对待,确保在格式化之前做好数据备份和迁移工作。
cd $HADOOP_HOME # 进入 Hadoop 安装目录
hdfs namenode -format # 格式化 HDFS

启动 HDFS 集群
启动时如无存在日志目录将会自行创建。
start-dfs.sh
启动后可以使用 jps 指令进行查看,如下图所示即可认为成功:
master 节点

slave1 节点
slave2 节点

启动成功后,我们可以访问 http://[IP]:9870 或 http://[主机名]:9870,来访问 HDFS 的 Web 管理 UI。这里的主机名和IP均指代NameNode的主机名和IP地址。
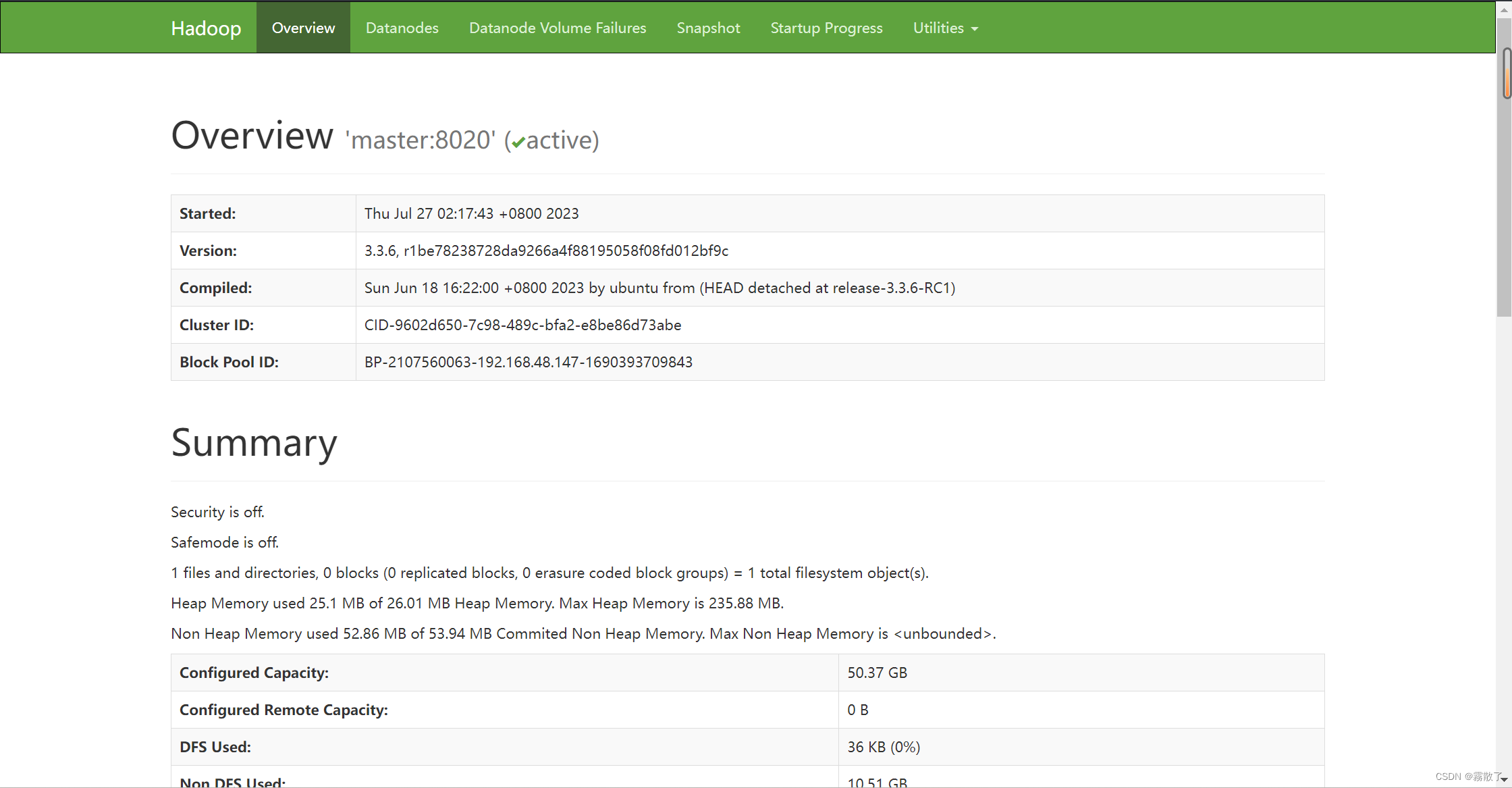
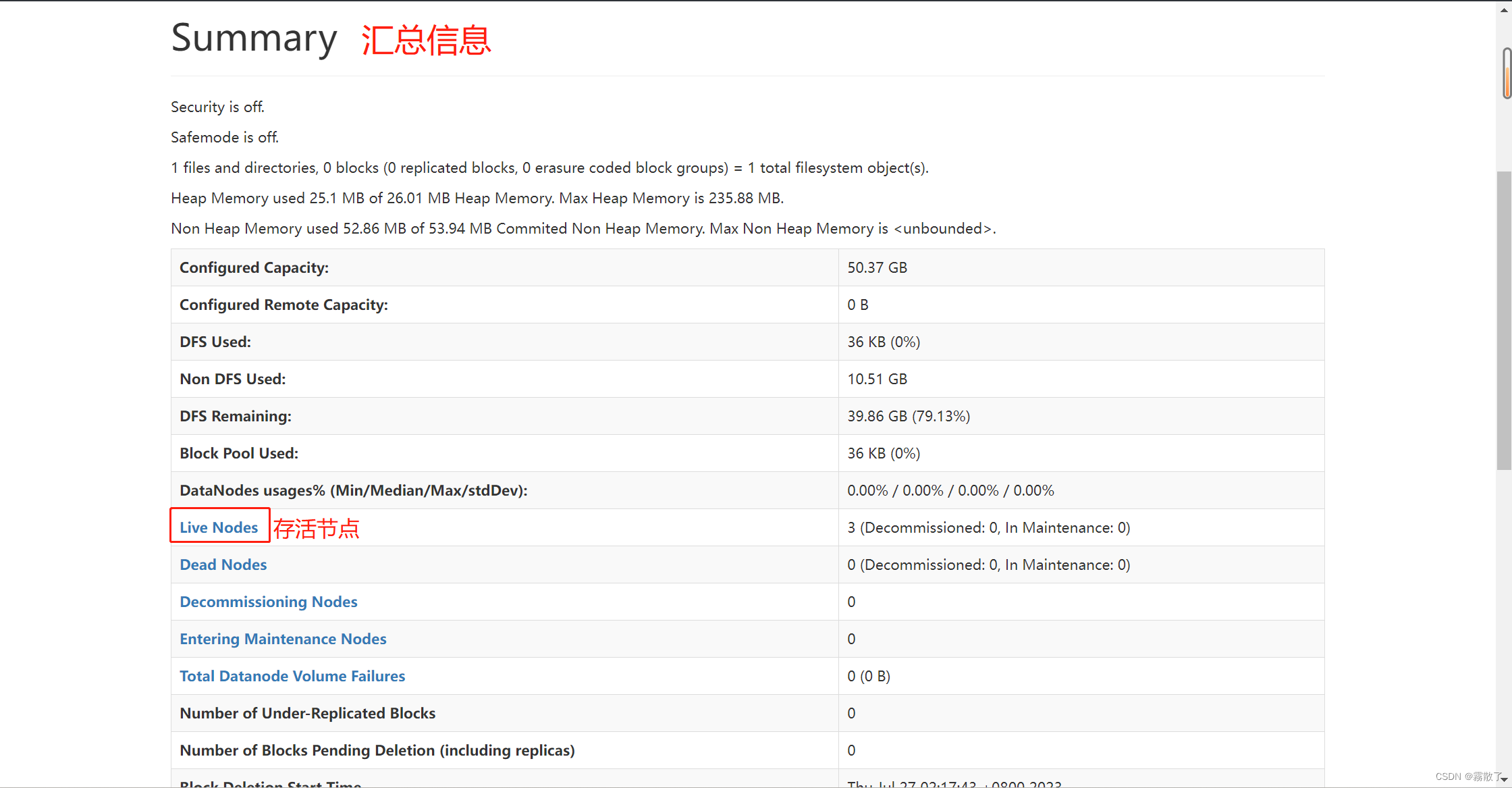
进入 Live Nodes,即可看见当前正在使用的节点。
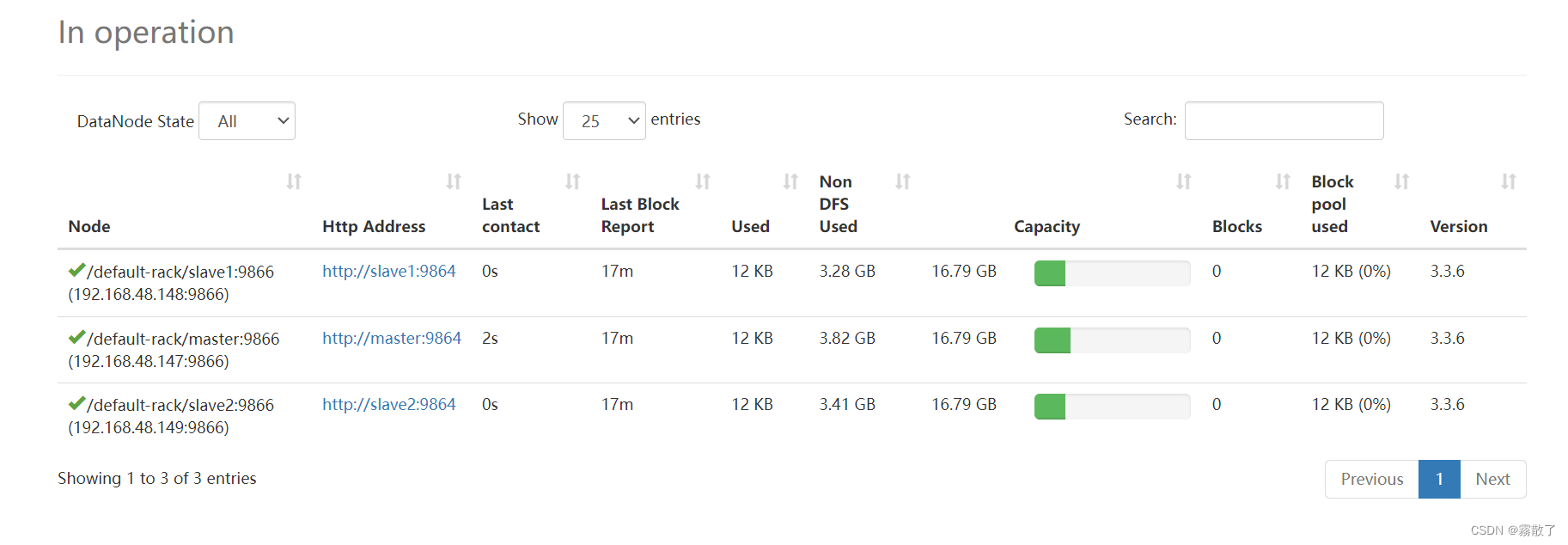
到这里,我们对于 HDFS 集群的部署就已经完成了。
启动 YARN 集群
在启动 YARN 集群之前,请先保证已经启动 HDFS 集群。
cd $HADOOP_HOME #
./bin/start-yarn.sh
master 节点
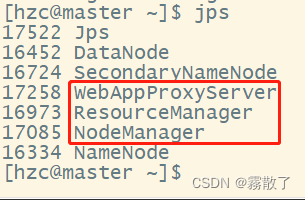
slave1 节点

slave2 节点

启动 JobHistory
mapred --daemon start historyserver

启动成功后,我们可以访问 http://[IP]:8088 或 http://[主机名]:8088,来访问 YARN 的 Web 管理 UI。这里的主机名和IP均指代NameNode的主机名和 IP地址。
因为是刚刚部署完成,所以下面并没有显示东西,当后面有程序运行时,便会显示在下面。

点击左边 Nodes ,即可查看现存在的节点

集群关闭
最后在关机前我们需要将集群关闭,以免出现一些意外情况。
首先是先关闭 JobHistoryServer
cd $HADOOP_HOME # 进入 Hadoop 安装目录
./bin/mapred --daemon stop historyserver
然后再关闭 YARN 集群
cd $HADOOP_HOME # 进入 Hadoop 安装目录
./bin/stop-yarn.sh
最后关闭 HDFS集群
cd $HADOOP_HOME # 进入 Hadoop 安装目录
./bin/stop-dfs.sh
或者可以使用脚本一键关闭 YARN 和 HDFS 集群
cd $HADOOP_HOME # 进入 Hadoop 安装目录
./bin/stop-all.sh

可以看到,关闭之后就已经没有相关进程存在了。
到这里有关 Hadoop 集群的部署已经全部完成了。