背景:最近新的工作要接触大数据,所以需要先接触一下hadoop,一步步学习下去,暂时没有固定的学习路线,还是看公司工作需要。先把hadoop环境跑起来,再多想想为什么。
**目的:部署的集群结构如下:
- master
- slave1
- slave2**
**第一步:**虚拟机安装linux系统,我使用的是centos7。常规安装,网上很多教程,因为做这个没有遇到什么错误。需要提一下的是:网络连接用的是NAT模式:为了不想踩权限的抗,我都是用root用户操作。
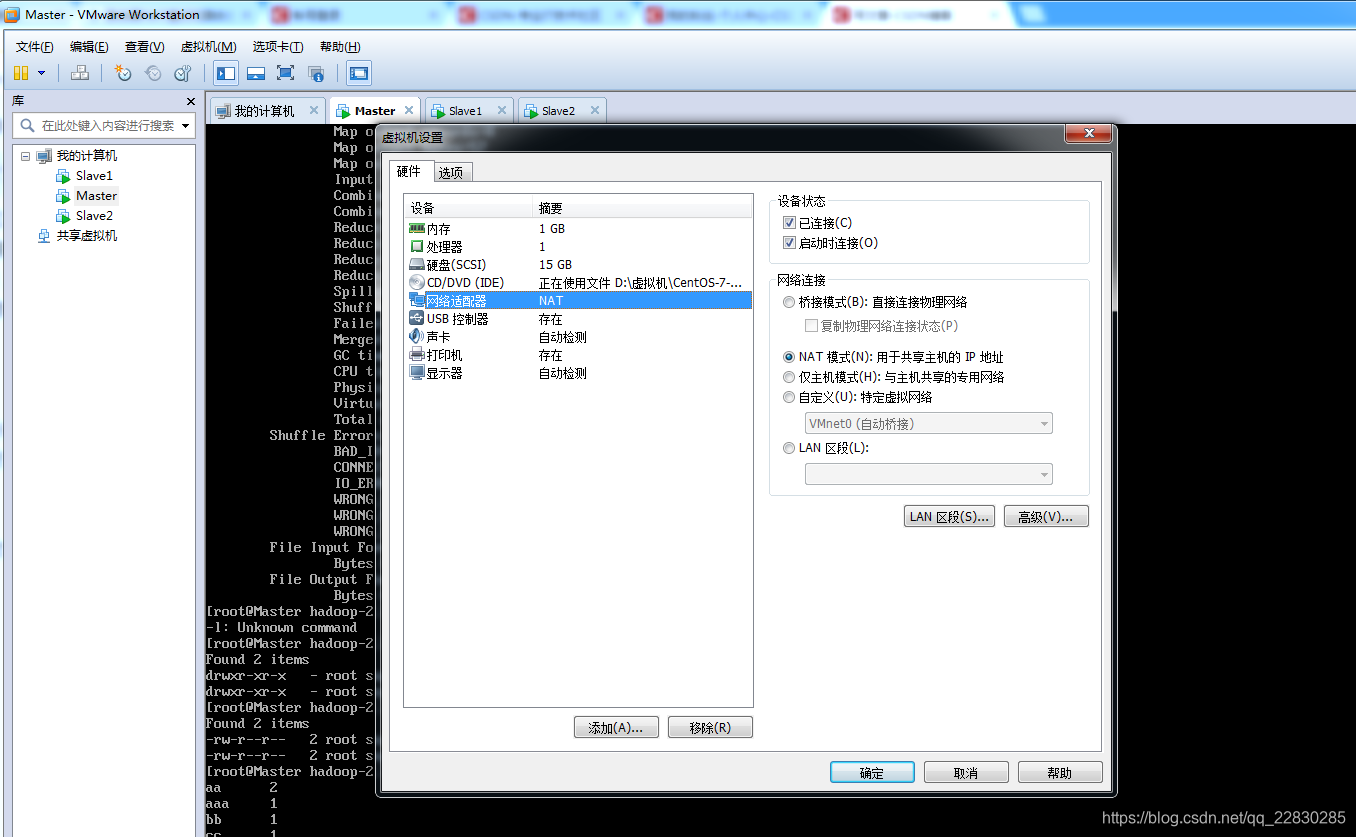
*第二步;*设置静态IP,这个是必须的,
我这个版本的linux 网络设置的文件是在/etc/sysconfig/network_scripts 下面的ifcfg-ens33,如下图:其实不同版本的linux对应的文件名可能是不一样的,但一般都会在/etc/sysconfig/network_scripts目录下的第一个。

修改 ifcfg-ens33的配置。我的修改后如下:
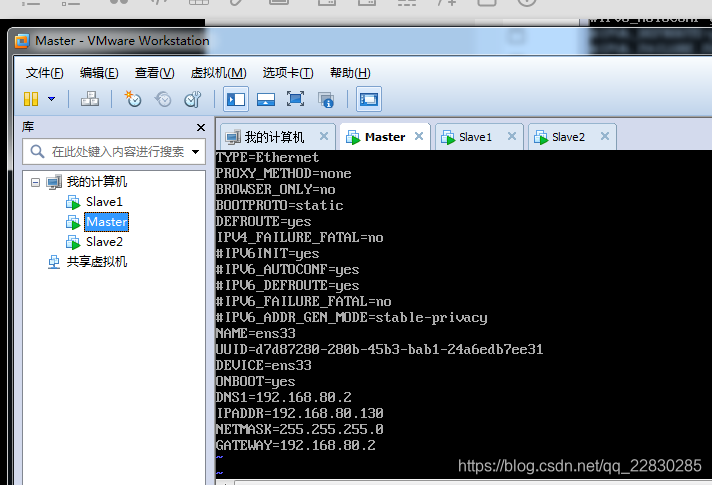
这里说一下需要修改的位置:
#修改
BOOTPROTO=static #这里讲dhcp换成ststic
ONBOOT=yes #将no换成yes
#新增
IPADDR=192.168.80.130 #静态IP(一般跟你的宿主主机ip在同一个网段,)
GATEWAY=192.168.80.2 #默认网关
NETMASK=255.255.255.0 #子网掩码
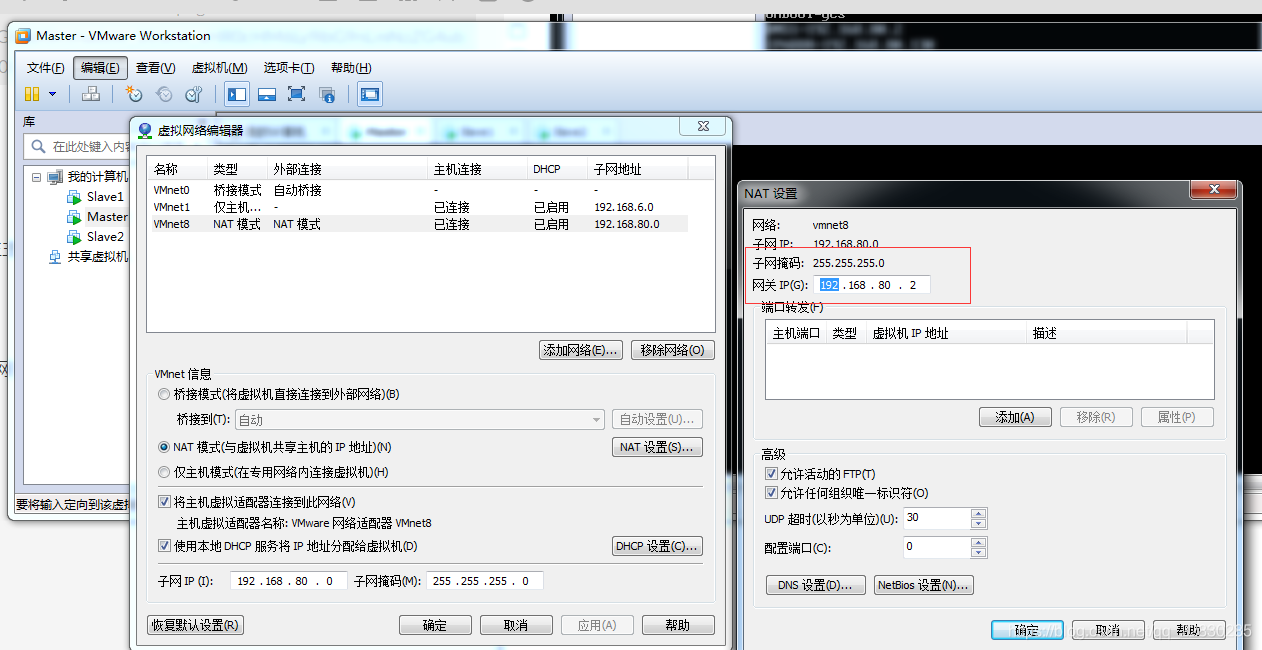
注意:掩码一般设置成255.255.255.0就行了,默认网关要和NAT里面的设置一样,见图
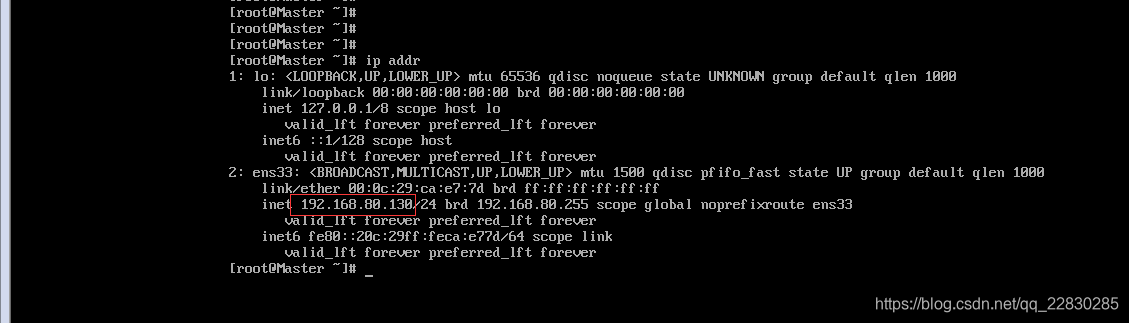
修改并保存好ifcfg-eng33 配置文件之后,一定要记得 用 service network restart 重起一下。
然后用 ip addr 命令查看一下当前的ip地址是不是刚才设置的。
三个虚拟机都需要这样设置静态IP,
第三步 IP地址映射:关闭防火墙
为了方便以后的操作,给静态的ip 地址作一下映射,在/etc/hosts 文件添加映射就行。如图:
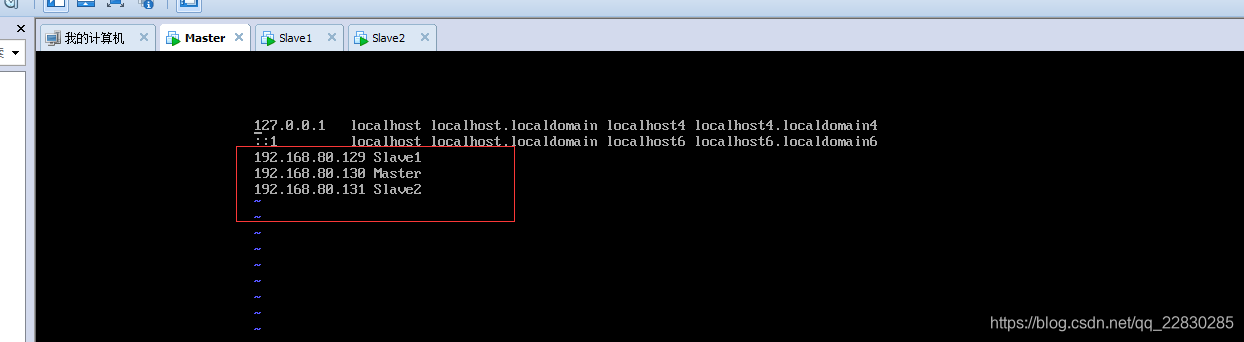
这样,Master 就相当于 192.168.80.130, 3个linux系统都这么配置。
关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
第四步:设置SSH免密登录。
4.1首先要确保各个系统可以相互Ping 通,如果ping 不通一定是网络链接的设置问题。
4.2,关于免密登录的原理有必要说一下,因为知道了原理,后面的操作就显得很明了。
我们都知道,网络安全里有私钥和公钥 这两个名词。假如有A,B 两个服务器,如果要实现A 免密登录B,那么A需要把他 的公钥发到B 服务器里,等A请求B的时候,B就会根据A的公钥生成加密的字符发送到A ,A再用自己的私钥解密,然后将解密得到的字符串发送给B,B服务对比是否相同,若相同,则不需要密码登录。
4.3 生成公钥和私钥:#进入到我的home目录
cd ~/.ssh使用ssh-keygen -t rsa命令,然后一直回车回车即可,执行完这个命令后,.ssh目录会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。如下图

上面是在slave2的机子上操作的,
第二步就是把slave2的公钥发给 master 机子,
,ssh-copy-id Master,
将公共密钥填充到一个远程机器上(master)的authorized_keys文件中.。
因为我搭建的是一个主namenode,两个datanode 的集群。根据上面的操作,把slave1 和slave2 的公钥发到master 的authorized_keys。然后,将Master 它本身的公钥拷贝到(authorized_keys)
cat ~/.ssh/ id_rsa.pub >> ~/.ssh/authorized_keys,
最后将Master 的authorized_keys 拷贝覆盖slave1,slave2的 authorized_keys文件。在master执行以下命令。
scp ~/.ssh/authorized_keys slave1:~/.ssh/authorized_keys #拷贝到salve1上
scp ~/.ssh/authorized_keys slave2:~/.ssh/authorized_keys #拷贝到slave2上
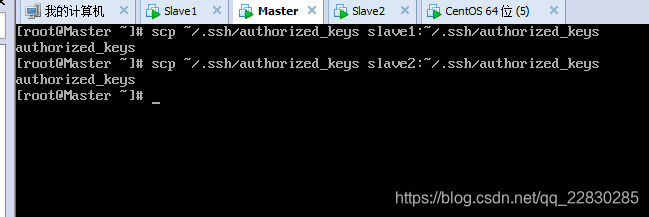
做完这些,master,slave1,slave2 之间就可以相互免密登录了。用ssh hostname(主机名) 就可以登录其他机子了。
**第五步:Master部署 jdk,hadoop **
5.1准备安装包:
jdk-8u191-linux-x64.tar.gz,下载地址:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
hadoop-2.7.7.tar.gz
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
我这边先是用win7系统下载到本地E 盘根目录,然后通过pscp 远程复制命令复制到linux 系统上。
pscp E:/jdk-8u191-linux-x64.tar.gz [email protected]:/home/
pscp E:/hadoop-2.7.7.tar.gz [email protected]:/home/
(注:pscp 命令win 系统本身不具备,需要到putty 官网下载 https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html)
pscp 命令安装教程可以参考 https://jingyan.baidu.com/article/60ccbceb551d3164cab19719.html
5.2 linux 解压安装包进入home 目录解压
tar -zxvf jdk-8u191-linux-x64.tar.gz
tar -zxvf hadoop-2.7.7.tar.gz
5.3 配置jdk ,hadoop 环境变量
在 master /etc/目录下的profile 加入如图红框的内容:
命令 vi /etc/profile 编辑 profile
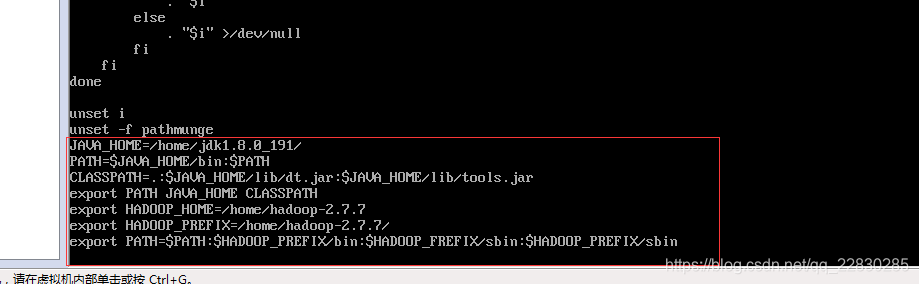
保存之后,用命令 source /etc/profile 重起系统环境变量,立刻生效。
第六步:修改hadoop的配置文件
文件位置:/home/hadoop-2.7.7/etc/hadoop,
文件名称:hadoop-env.sh、yarn-evn.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
hadoop-env.sh和yarn-evn.sh ,加入jdk的目录
export JAVA_HOME=/home/jdk1.8.0_191
修改 core-site.xml 文件,在configuration添加配置
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop-2.7.7/tmp/</value>
</property>
</configuration>
修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/dfs/data</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
修改 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
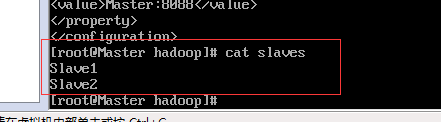
修改 slaves文件,同样在这个目录下
添加从机的名字
Slave1
Slave2
第七步,同步从机
因为上面的配置都是在master上,slave1,slave2跟master的保持一致就行。
用scp 命令将 hadoop-2.7.7,jdk1.8.0_191复制到slave1 ,slave2 的home 目录下
scp /home/hadoop-2.7.7 slave1:/home/
scp /home/hadoop-2.7.7 slave2:/home/
scp /home/jdk1.8.0_191 slave1:/home/
scp /home/jdk1.8.0_191 slave2:/home/
配置profile的环境变量
scp /etc/profile slave1:/etc/profile
scp /etc/profile slave2:/etc/profile
分别在slave1,slave2 source重起一下
source /etc/profile
第八步:运行hadoop
8.1在 hadoop 目录下执行下面语句初始化 HDFS,一定要在hadoop目录下执行
bin/hdfs namenode -format

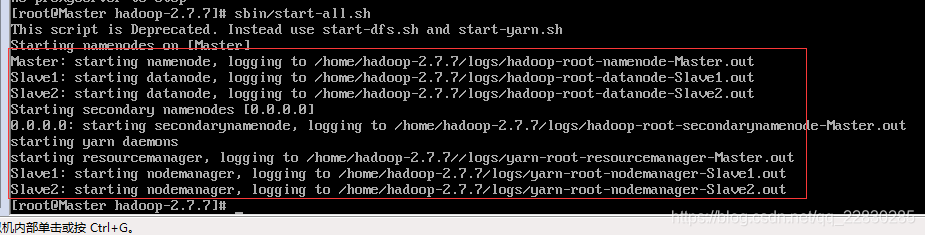
8.2 运行hadoop
sbin/start-all.sh
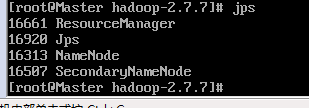
8.3 用jps 命令查看hadoop 运行的组件
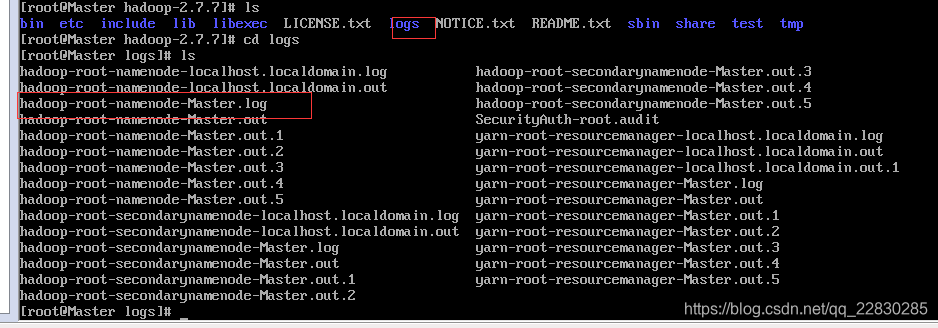
8.4 如果jps ,没看到相应的,那应该是启动不成功,或许是配置文件有错,这时候就去找相应的日志文件,在hadoop 下有一个logs的文件夹,包含了启动的日志。比如,如果jps没有看到 resourceManager,可以看相应的manager日志。
8.5,win系统浏览器查看hadoop web
浏览器打开地址:http://192.168.80.130:50070/dfshealth.html#tab-datanode
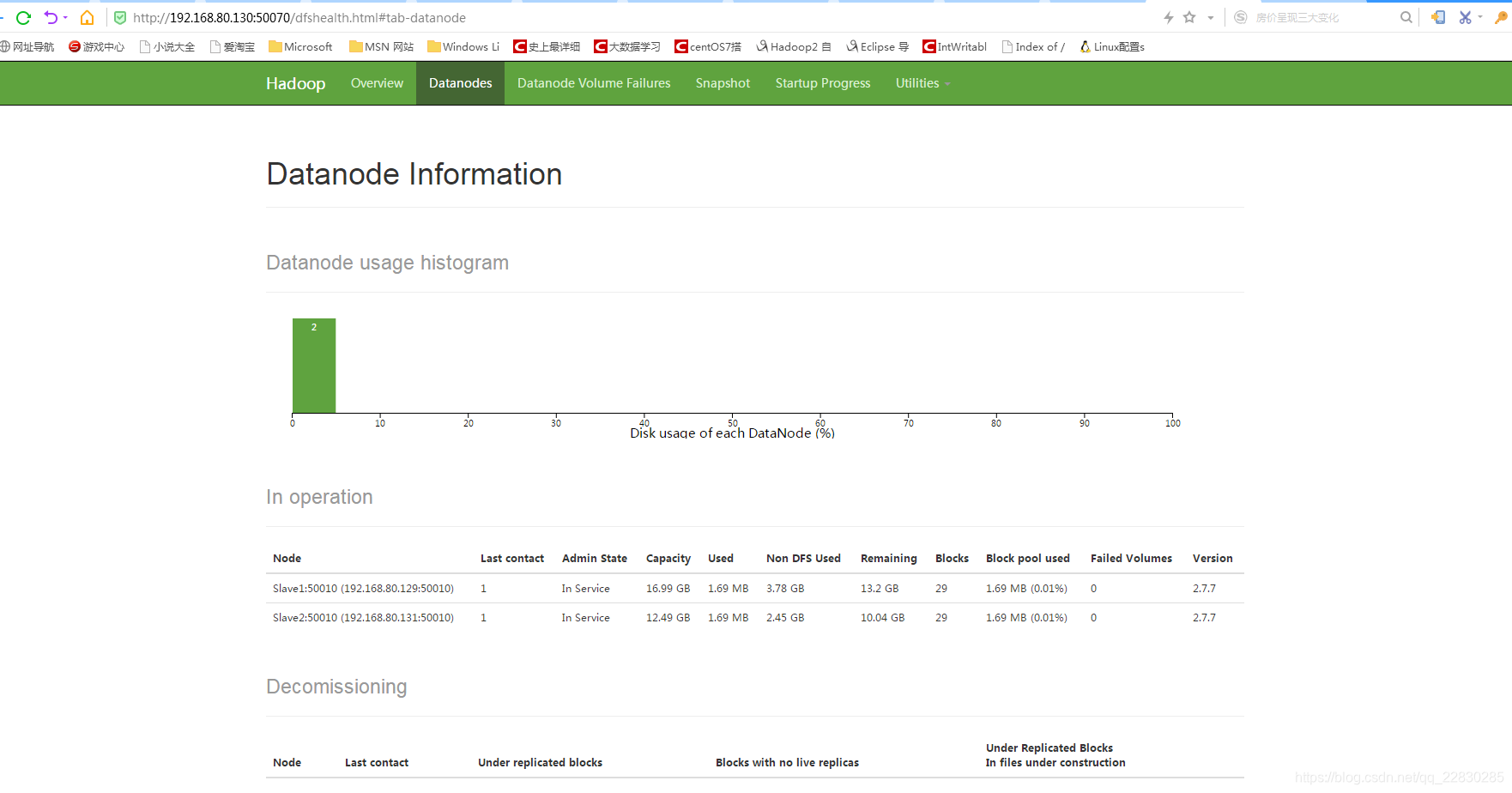
8.6 查看hadoop 集群 applitions
浏览器打开地址:http://192.168.80.130:8088
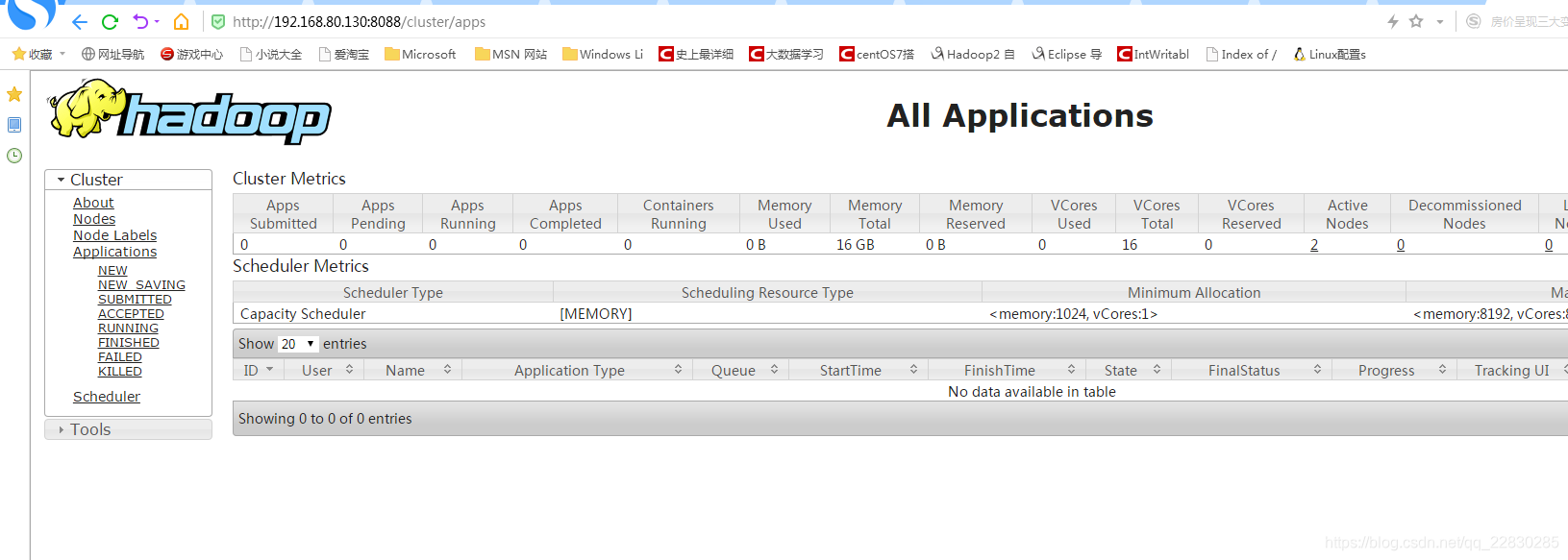
参照资料:https://blog.csdn.net/yujuan110/article/details/78457259
linux 运行wordcount :https://blog.csdn.net/qq_22830285/article/details/84143774