Hadoop概述:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS分布式文件系统为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
网方网站:http://hadoop.apache.org/
废话不多说,下面开始搭建
一、实验环境 准备
安装前,3台虚拟机IP及机器名称如下:
主机名 IP地址 角色
ha146.cn 192.168.1.146 NameNode
ha147.cn 192.168.1.147 DataNode1
ha120.cn 192.168.1.120 DataNode2
因为是本地搭建所以直接关闭三台机器防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
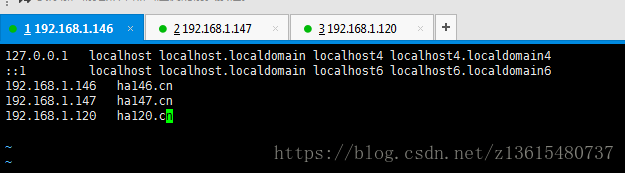
(1)三台机器上配置hosts文件,(三台都配置)
vim /etc/hosts 添加
192.168.1.146 ha146.cn
192.168.1.147 ha147.cn
192.168.1.120 ha120.cn
(2)创建运行hadoop用户账号和Hadoop目录(3台都创建)
useradd -u 8000 hadoop #设置账号
echo 123456 | passwd --stdin hadoop #设置密码
(3)给hadoop账户增加sudo权限
vim /etc/sudoers
添加 hadoop ALL=(ALL) ALL

:wq!强制保存
(4)配置Hadoop环境,安装Java环境JDK:三台机器上都要配置
我用的是源码安装 jdk1.8.0_131 。也可以yum安装 。
官方地址: http://www.oracle.com/technetwork/java/javase/downloads/index.htm
JDK下载地址 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
tar xvf jdk-linux-x64.tar.gz -C /usr/local/
配置环境变量 vim /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_131
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATHsource /etc/profile
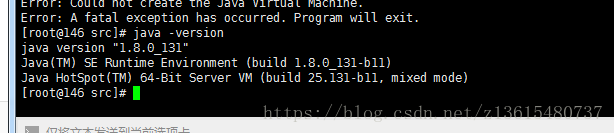
java -version 查看是否配置成功
(4)配置ssh无密码登录
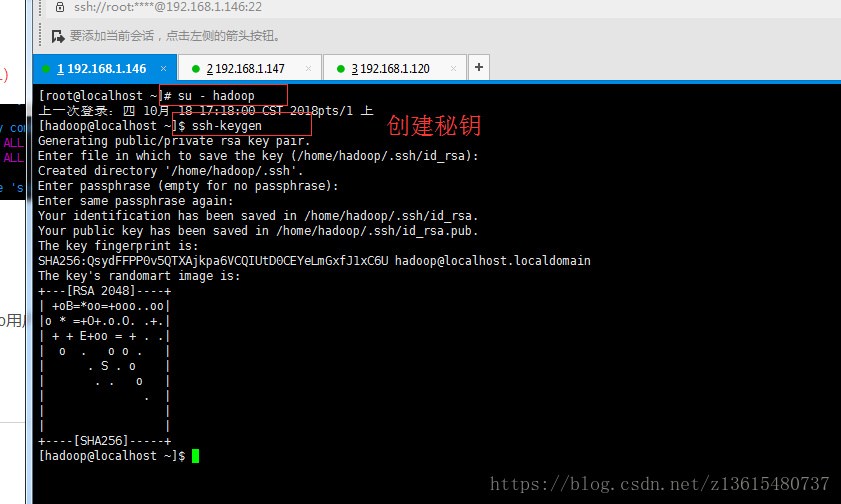
在146服务器上 切换到hadoop用户 su - hadoop
ssh-keygen
[hadoop@146 ~]$ ssh-copy-id 192.168.1.147
[hadoop@146 ~]$ ssh-copy-id 192.168.1.120
测试 ssh 192.168.1.147 如果直接登录,不需要密码说明成功
二、配置hadoop
在146上安装Hadoop 并配置成namenode主节点
Hadoop安装目录:/home/hadoop/hadoop-3.0.0
使用root帐号将hadoop-3.0.0.tar.gz 上传到服务器 可以去官网下载http://hadoop.apache.org/ 我的是3.0
上传到hadoop的家目录 切换到hadoop解压 只要解压文件就可以,不需要编译安装
tar xvf hadoop-3.0.0.tar.gz

创建hadoop相关的工作目录(每台机上都要创建目录)
mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp #每台机上都要创建目录
sudo chown -R hadoop:hadoop /home/hadoop/* # 确定每个目录下的所属都是hadoop 每台机都要执行
配置Hadoop:需要修改7个配置文件。进入配置文件 cd hadoop-3.0.0/etc/hadoop/
文件名称:hadoop-env.sh、yarn-evn.sh、workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
1、 vim hadoop-env.sh (指定java运行环境变量)
改:54 # export JAVA_HOME=
为:export JAVA_HOME=/usr/local/jdk1.8.0_131/
2、vim yarn-env.sh 保存yarn框架的运行环境
查看优先规则: 23行
## Precedence rules:
##
## yarn-env.sh > hadoop-env.sh > hard-coded defaults
3、vim core-site.xml,指定访问hadoop web界面访问路径
在19 20行添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://ha146.cn:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>13107</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>io.file.buffer.size 的默认值 4096 。这是读写 sequence file 的 buffer size, 可减少 I/O 次数。在大型的 Hadoop cluster,建议可设定为 65536
4、vim hdfs-site.xml dfs.http.address配置了hdfs的http的访问位置;dfs.replication配置了文件块的副本数,一般不大于从 机的个数。
还是19 20行 添加
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ha146.cn:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
注:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ha146.cn:9001</value> # 通过web界面来查看HDFS状态
</property>
<property>
<name>dfs.replication</name>
<value>2</value> #每个Block有2个备份。
</property>
5、vim mapred-site.xml 这个是mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数,同时指定:Hadoop的历史服务器historyserver Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器
$ /home/hadoop/hadoop-3.0.0/sbin/mr-jobhistory-daemon.sh start historyserver
historyserverWARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
WARNING: /home/hadoop/hadoop-3.0.0/logs does not exist. Creating.
这样我们就可以在相应机器的19888端口上打开历史服务器的WEB UI界面。可以查看已经运行完的作业情况。
还是19 20行
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>6、vim yarn-site.xml 该文件为yarn框架的配置,主要是一些任务的启动位置
同样还是在<configuration></configuration> 之间添加
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>ha146.cn:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>ha146.cn:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>ha146.cn:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>ha146.cn:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>ha146.cn:8088</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/home/hadoop/hadoop-3.0.0/etc/hadoop:/home/hadoop/hadoop-3.0.0/share/hadoop/common/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/common/*:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/hdfs/*:/home/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-3.0.0/share/hadoop/yarn/* </value>
</property>注意classpath下面只有一行没有回车
7、vim workers 编辑datanode节点host
ha147.cn
ha120.cn

三、复制配置初始化 启动
上面是146主服务配置完了 需要将=刚刚配置的文件复制到147和120服务器上
scp /home/hadoop/hadoop-3.0.0/etc/hadoop/* 192.168.1.147:/home/hadoop/hadoop-3.0.0/etc/hadoop/
scp /home/hadoop/hadoop-3.0.0/etc/hadoop/* 192.168.1.120:/home/hadoop/hadoop-3.0.0/etc/hadoop/
在146上初始化 Hadoop hadoop namenode的初始化,只需要第一次的时候初始化,之后就不需要了
/home/hadoop/hadoop-3.0.0/bin/hdfs namenode -format
echo $? 看执行成功没
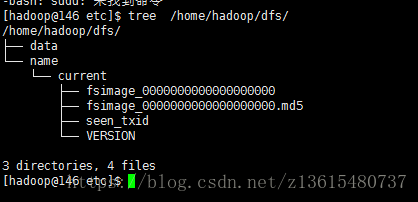
tree /home/hadoop/dfs/
/home/hadoop/hadoop-3.0.0/sbin/start-dfs.sh 启动
/home/hadoop/hadoop-3.0.0/sbin/stop-dfs.sh 关闭
/home/hadoop/hadoop-3.0.0/sbin/start-all.sh 启动全部
添加环境变量 HADOOP_HOME
[root@146~]# vim /etc/profile #添加追加以下内容:
export HADOOP_HOME=/home/hadoop/hadoop-3.0.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@146~]# source /etc/profile
[root@146~]# start #输入start 按两下tab键,测试命令补齐