前言 :
Hadoop 发展前景 :
(1)分布式文件系统 HDFS (GFS) 。
(2)数据的计算 : 分布式计算。
1 MapReduce , 搜索排名
2 大任务 拆分成小任务
3 Map 阶段 进行任务拆分,Reduce 阶段进行数据计算汇总 。(3)bigTable — Hbase (nosql), 行键 、列族。
启动 :start-all.sh
HDFS : 存储数据。
Yarn : Mapreduce 的运行容器。
访问 :
(1)命令行
(2)java api
(3) Web Console 管理界面
本地模式 :
特点:不具备 HDFS , 只能测试MapReduce 程序。
伪分布式模式 :
特点:具备Hadoop 所有功能,在单机上模拟一个分布式的环境。
(1)HDFS : 主 : NameNode , 数据节点 : DataNode
(2)Yarn : 容器 :运行MapReduce 程序 。
主节点 : ResourceManager 。
从节点 :NodeManager
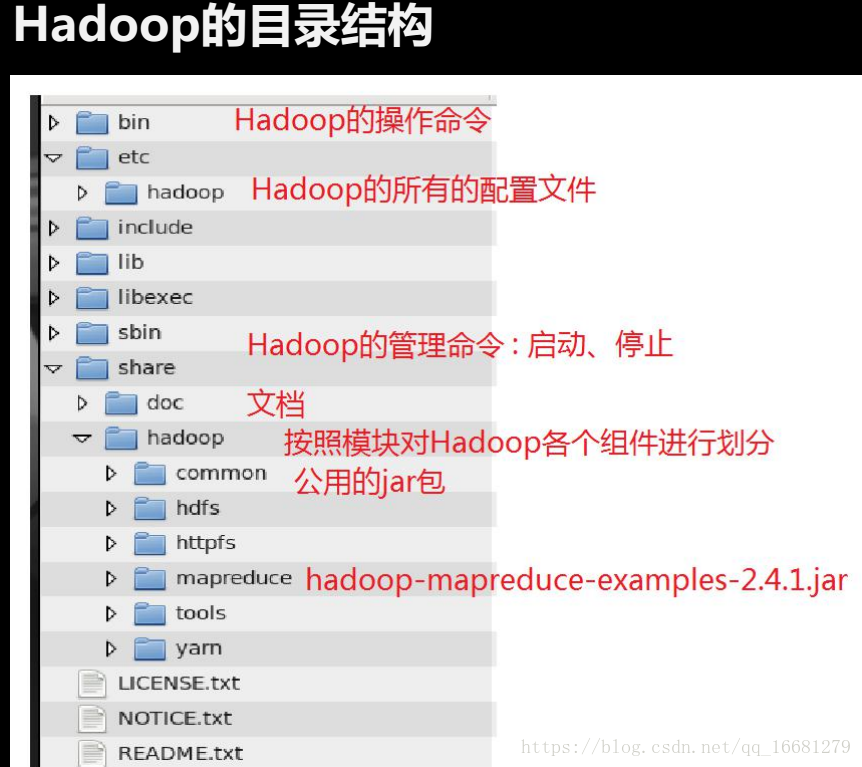
MapReduce 的使用 :agui/hadoop/hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar
[root@nn mapreduce]# hadoop jar hadoop-mapreduce-examples-2.8.3.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
[root@nn mapreduce]#
个人备忘
简单记录下操作过程,以及一些必要的配置和一些爬过的坑,希望对其他同学有帮助。
图中提到的关键性 “名词”这里暂不做解释~可自行查阅。
想要搭建集群,需要大家至少知道,我们要“一主几从”,这里的namenode 就可以当成主 ,其他的datanode 可以看成从。
大体思路 :
1)配置ip 映射 (可有可无)
2)防火墙关闭 或者 开放端口。
3)静态ip 网络配置(虚拟机专用),阿里云的服务器,ip 不会变,不必配置。
4)下载lrzsz ,用于 win 与 linux 的文件上传和下载。(Xsftp 也可 , 可有可无)。
5)添加hadoop 用户(可有可无,我用的是root 用户)
6)配置无密码的ssh 认证 (不做这步,初始化hdfs 的时候,会让你输入各个datanode 服务器的密码,可有可无)
7)下载hadoop 压缩包,解压缩安装。
8)对 hadoop 安装文件夹做映射 (可有可无)。
9)配置环境变量 cd ~ , ls -a 下的 .bashrc 文件 vim 打开,配置 hadoop 路径。
10) 开始hadoop 的集群配置,所有的配置文件都在 hadoop-2.8.3 下的 etc/hadoop 文件夹下。
11) 修改配置文件 vim hadoop-env.sh ,配置你本地的java路径。
12) 修改配置core-site.xml , hdfs-site.xml, mapred-site.xml , yarn-site.xml , slaves文件(namenode 节点配置即可,其他不用)。
对操作系统的要求 :
1、Hadoop生产环境要求Linux操作系统;
2、Hadoop官网只提供64位的安装包,我们的Linux系统也需是64的;
3、Hadoop程序中包含对本地库的调用,linux内核的glibc库版本必须匹配Hadoop的本地库版本要求。
如 hadoop-2.8.以上要求的glibc版本为2.14,如果我们Linux系统用CentOS,则需用CentOS-7.的版本,不能用CentOS-6.,CentOS-6.的glibc版本为2.12。
对JDK的要求 :
Hadoop版本与java版本的对应关系如下:
hadoop3.0 java8
hadoop2.7及后续版本 最低 java7
hadoop2.6及以前的版本 最低 java6
hadoop所有版本暂不鼓励用java9。
步骤一 : 配置主机名 -ip 映射
//修改主机名:
// 四个节点都需要设置,我这里起的名字是:nn.hadoop , dn1.hadoop , dn2.hadoop , dn3.hadoop 。为每台机器设置自己的主机名
[root@nn hadoop]# hostnamectl set-hostname nn.hadoop
[root@nn hadoop]# hostname
nn.hadoop
[root@nn hadoop]#
// 修改每台机器的/etc/hosts 文件,加入如下内容:
47.104.8.2 nn.hadoop
39.107.34.31 dn1.hadoop
39.107.2.11 dn2.hadoop
47.95.0.10 dn3.hadoop
步骤二 :防火墙 配置
我直接关闭了防火墙,开发端口等,可以参考我原来的备忘。
步骤三 : 下载 lrzsz 软件
lrzsz是一款在linux里可代替ftp上传和下载的程序。因为我们要上传安装包文件。
安装命令:yum install –y lrzsz
lrzsz使用
上传文件
在xshell窗口中:
上传文件输入命令: rz
下载文件输入命令:sz 你要下载的文件 例如 :
[root@nn hadoop]# sz hadoop-env.sh 步骤四 :配合ssh 秘钥 ,免登录
ssh无密码认证配置
为方便管理集群,在主控节点上统一开启、停止集群中各节点的hadoop进程,而不需每个节点去启动、停止。hadoop采用ssh无密码验证的方式由namenode、resourcemanager节点来统一管理HDFS集群、yarn集群的节点。
要实现统一管理,需要节点上的每台机器上都开启了ssh和rsync服务。
ssh 用来安全登录远程主机,这里是主控节点(NameNode、ResourceManager)要无密码连接到各从节点(DataNode、NodeManager)来控制从节点上的hadoop进程。
rsync 是一个远程同步工具,namenode用它来向个datanode同步文件。
在集群的每台机器上进行安装、配置。
检查是否安装了ssh和rsync服务
命令:
rpm –qa | grep ssh
rpm –qa | grep rsync
安装ssh和rsync
如果没有安装ssh:
yum install ssh 以yum的方式安装ssh
安装好后,启动sshd服务:
service sshd restart
开启开机自启动:
chkconfig sshd on
如果没有安装 rsync:
yum install rsync 以yum的方式来安装rsync
配置无密码连接
配置HDFS、yarn两个集群的无密码连接管理,就是配置主控节点上的运行用户可以无密码连接到从节点,来管理从节点的服务。以HDFS集群为例,我们在NameNode节点以hdfs用户来启动hdfs集群,在NameNode节点上将运行NameNode进程,而需要在DataNode节点上开启DataNode进程,这时就需要无密码登录连接到DataNode节点的hdfs用户,来开启DataNode进程。
下面介绍HDFS集群的上的无密码连接,yarn集群是一样的。
Namenode的配置
1. 以root用户登录linux来操作。
先检查是否可以无密码连接:
2、生成无密码密钥对:
命令:ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa
说明: -t rsa 指定使用rsa算法
-P ‘’ 单引号中没有字符,表示没有密码
-f 指定秘钥文件的名字
3、查看生成的密钥对文件,命令:ls –a ~/.ssh
4、将公钥追加到root用户的授权keys中。
命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
5、修改授权keys文件的权限为600
命令:chmod 600 ~/.ssh/authorized_keys
6、验证root用户是否可以无密码ssh连接了
root用户,ssh连接本机,命令:ssh localhost
如果你的还是不能无密码连接,则进行下面的设置后,再试一下。
7、修改sshd的配置文件,开启RSA认证。
注意:用root用户来修改,操作
修改sshd的配置文件命令:vi /etc/ssh/sshd_config
在文件中作下图所示的修改:
8、重启sshd服务
命令:service sshd restart
Datanode的配置
Datanode的配置是让Namenode能无密码登录连接到Datanode,Namenode是客户端,Datanode是服务端,我们只需把客户端的公钥加入到服务端用户的授权keys文件中,则客户端通过其私钥连接服务端时,服务端能解出密文,就能确认用户,允许连接。
用hdfs用户在各Datanode机器上进行如下操作:
步骤说明:
1、拷贝公钥文件到DataNode上
拷贝Namenode上的公钥文件 /home/hdfs/.ssh/id_rsa.pub到Datanode上。
在datanode上,我们可以用scp命令来进行远程拷贝,命令:
scp hdfs@namenode-ip:~/.ssh/id_rsa.pub ~
说明:
root:远程用户名(连接namenode的用户名)
namenode-ip: namenode机器的ip地址
:~/.ssh/id_rsa.pub >> 号后是要拷贝的文件(目录)
~ 拷贝到本地用户的home目录,也可指定别的目录
2、追加公钥到用户的授权keys文件中。
3、修改授权keys文件的权限为600。
从Namenode无密码连接Datanode试试。
[root@nn hadoop]# ssh dn1.hadoop
Last login: Sun May 6 11:18:31 2018 from 47.04.1.2
Welcome to Alibaba Cloud Elastic Compute Service !
[root@dn1 ~]#
步骤五 :下载hadoop 压缩包
hadoop安装包
从hadoop的官网获取你需要的版本,本教程采用2.8.X版本的安装包。
官网地址:http://hadoop.apache.org/releases.html
注意:当前hadoop官网上已不提供32位的安装包了,所以你获得的都是64位的。这也要求你的Linux系统必须是64位。
我下载的是下面这个 :
JDK 我得是 1.8 版本。
步骤六 :解压缩 并 配置 hadoop 环境变量
tar -zxvf hadoop-2.8.3.tart.gz -C /agui/hadoop/
lv -s hadoop-2.8.3 latest
[root@dn1 hadoop]# ll
total 8
drwx------ 3 root root 4096 May 6 12:17 data
drwxr-xr-x 10 502 dialout 4096 May 6 11:31 hadoop-2.8.3
lrwxrwxrwx 1 root root 12 May 6 10:24 latest -> hadoop-2.8.3
[root@dn1 hadoop]# pwd
/agui/hadoop
[root@dn1 hadoop]#
配置hadoop环境变量 :
为hadoop配置JAVA_HOME :
[root@dn1 hadoop]# cd /agui/hadoop/latest/etc/hadoop
[root@dn1 hadoop]# ls
capacity-scheduler.xml hadoop-policy.xml kms-log4j.properties ssl-client.xml.example
configuration.xsl hdfs-site.xml kms-site.xml ssl-server.xml.example
container-executor.cfg hdfs-site.xml.back log4j.properties yarn-env.cmd
core-site.xml httpfs-env.sh mapred-env.cmd yarn-env.sh
core-site.xml.back httpfs-log4j.properties mapred-env.sh yarn-site.xml
hadoop-env.cmd httpfs-signature.secret mapred-queues.xml.template yarn-site.xml.back
hadoop-env.sh httpfs-site.xml mapred-site.xml
hadoop-metrics2.properties kms-acls.xml mapred-site.xml.template
hadoop-metrics.properties kms-env.sh slaves
[root@dn1 hadoop]#
[root@dn1 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/agui/jdk/jdk1.8.0_151
// 如下标识配置没问题
[root@dn1 hadoop]# hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
credential interact with credential providers
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
步骤七 : hadoop 集群的配置
说明:有些配置文件,在hadoop 解压缩目录下并没有,自己构建即可。
hadoop集群配置文件如下:
链接: https://pan.baidu.com/s/1Y9l2dWrUYe5HrV2uJCSwWw 密码: hrcz
可用lrzsz 的 rz 命令上传到 linux 上。
core-site.xml 核心配置文件
它会被所有的hadoop进程使用。需在该配置文件中配置hadoop集群默认文件系统的访问uri(必需配置),可以指定IO缓冲区的大小等。
// 配置如下
// 坑一 排查 9000 端口是否被占用。
// 坑二 namenode 节点,该处ip配置改为 0.0.0.0, 其他三个datanode 该处配置为namenode 的外网ip 。记得去阿里云安全组开放9000端口
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.11:9000</value>
</property>
</configuration>hdfs-site.xml hdfs集群参数配置文件
在该文件配置hdfs集群的参数,常用的配置参数如下,如果都是使用的默认值,则不需进行配置。
hdfs-site.xml
// 所有节点都要创建,namespace 和 data 文件夹 。具体文件夹路径照应如下配置
<configuration>
<property>
<description>文件的备份数量</description>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<description>NameNode文件系统名称空间存放目录</description>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namespace</value>
</property>
<property>
<description>DataNode上文件数据块的存放目录</description>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data</value>
</property>
</configuration>在NameNode的etc/hadoop/slaves 文件列出所有的DataNode的ip,一个一行。
如 :
[root@dn1 hadoop]# pwd
/agui/hadoop/latest/etc/hadoop
[root@dn1 hadoop]# vim slaves
10.0.2.20
10.0.2.21
10.0.2.22
YARN集群配置 :
etc/hadoop/mapred-site.xml 配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml 配置
<configuration>
<!-- Site specific YARN configuration properties -->
// 坑 <value>192.168.0.13</value> 该处,在namenode 节点配置 0.0.0.0 ,其他datanode 节点配置 namenode 的外网ip 即可。
// 坑二,该处默认使用端口为 8031 。所以你需要去namenode 所在的机器,设置 阿里云安全组开放这个端口。
// 该配置文件可以配置zk 的集群,实现高可用。所有datanode 节点都需要配置。
<property>
<description>resourceManager节点的主机地址</description>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.13</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>至此,所有配置完毕。
启动集群:
启动hdfs集群
阿里云安全组,namenode 所在的机器,开放 50070 8088 两个端口
1、格式化文件系统
$ hdfs namenode -format
2、在NameNode上启动hdfs集群
$ start-dfs.sh
hadoop进程的日志将输出在目录 $HADOOP_HOME/logs下
3、通过浏览器浏览NameNode的web界面,默认的浏览地址为:
http://namenode-ip:50070
如 http://192.168.0.111:50070
可用jps命令查看各个节点上运行的java进程
4、在NameNode上关闭hdfs集群
$ stop-dfs.sh
启动yarn集群
1、启动:在ResourceManager上启动yarn集群
$ start-yarn.sh
2、通过浏览器浏览ResourceManager的web界面,默认的浏览地址为:
http:// ResourceManager-ip:8088
如 http://192.168.0.111:8088
3、关闭:在ResourceManager上关闭yarn集群
$ stop-yarn.sh
启动jobHistoryServer
mr-jobhistory-daemon.sh start historyserver
试用一下 : 有坑
文件分片同步到 datanode 还需要 在三个datanade 节点 开放阿里云安全组,端口为 :50010 。要么 文件没法 分片到datanode 。
所有的hadoop日志,都在 hadoop-2.8.3/logs 下。
1、在HDFS上创建执行MapReduce作业所需的目录
hdfs dfs -mkdir /agui
hdfs dfs -mkdir /agui/hadoop
2、将输入文件拷贝到分布式文件系统上:
hdfs dfs -mkdir input
hdfs dfs -put etc/hadoop/*.xml input
3、运行MapReduce示例作业:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar grep input output ‘dfs[a-z.]+’
4、查看输出结果文件:
方式一:将分布式文件系统的输出文件拷贝到本地文件系统上,再查看:
hdfs dfs -get output output
cat output/*
方式二:直接在分布式文件系统上查看输出文件:
hdfs dfs -cat output/*
样例截图 :