版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/dream_1996/article/details/78664379
非比较排序
1.计数排序
利用哈希的思想,直接定值法。开辟最大值到最小值范围的数组,把待排序数组里的数据取模后在新数组对应的位置进行标记,新数组里存的值是引用计数,统计重复的个数,下标加上最小值为对应旧数据的大小。
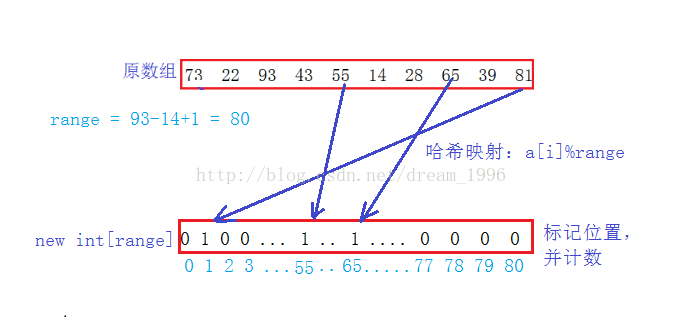
代码实现
void CountSort(int *a, size_t size)
{
int min = a[0];
int max = a[0];
for (int i = 1; i < size; i++)
{
if (min > a[i])
min = a[i];
if (max < a[i])
max = a[i];
}
int range = max - min + 1;
vector<int> tmp;
tmp.resize(range, 0);
for (int i = 0; i < size; i++)
{
int index = a[i] % range;
tmp[index]++;
}
for (size_t i = 0,j = 0; i < range; i++)
{
while (tmp[i]-- != 0)
a[j++] = i+min;
}
}时间复杂度
O(N)
局限性
- 为了避免哈希冲突,因此需要开辟从最小值到最大值范围的空间。所以适合比较集中,范围比较小的数据排序。
- 只适合整形排序。
- 空间复杂度高。
2.基数排序
思想
利用哈希的思想,先对个位排序;个位有序后,在对十位排序;十位有序后再对更高位排序,把最大数的位数排完,整个序列就有序了。
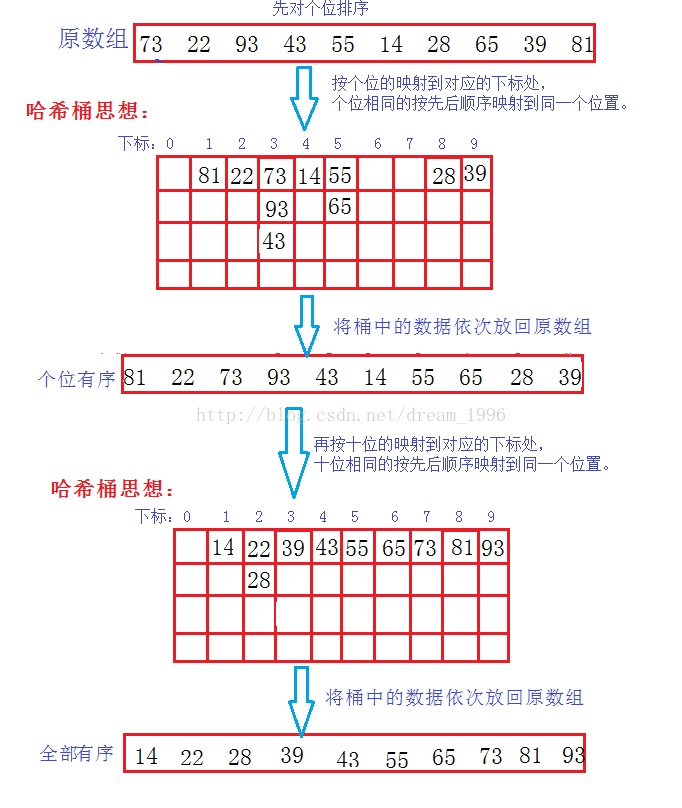
实现方法
如对个位排序
- 首先统计每一个个位的出现的次数。
- 统计出每一个个位的起始位置。第i号桶的首位置为第i-1的次数加上第i-1的首位置。
- 用原数组里的数依次取模求个位,然后去统计首位起始位置的数组里,求出这个个位对应的下标,先依次放入新数组,最后再依次放回原数组。

对每一位统计的方法是一样的, 然后统计基数 ,对每一个基数位用对个位排序的方法进行排序。
代码实现
void RadixSort(int* a, size_t n)
{
int counts[10] = { 0 };//统计同一位上相同的数据出现的次数
int start[10] = { 0 }; //统计同一位上不相同的数据在数组上的第一个起始位置
int Base = 10;
int range = 1;
for (int i = 1; i < n; i++)
{
if (a[i] >= Base)
{
++range;
Base *= 10;
}
}
int* tmp = new int[n];
Base = 1;
for (int j = 0;j<range; j++)
{
for (int i = 0; i < n; i++)
{
counts[a[i]/Base % 10]++;
}
for (int i = 1; i < n; i++)
{
start[i] = start[i - 1] + counts[i - 1];
}
for (int i = 0; i < n; i++)
{
size_t index = start[a[i] / Base % 10]++;
tmp[index] = a[i];
}
for (int i = 0; i < n; i++)
{
a[i] = tmp[i];
counts[i] = 0;
start[i] = 0;
}
Base *= 10;
}
delete[] tmp;
}时间复杂度
O(N*基数)
局限性
只能对正整数排序