版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/majinlei121/article/details/83210890
前两篇文章对wiki中文语料进行下载(wiki中文文本语料下载并处理 ubuntu + python2.7)和分词(python wiki中文语料分词),本篇使用word2vector训练词向量,训练程序为
# -*- coding: utf-8 -*-
#!/usr/bin/env python
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
from gensim.models import word2vec
import logging, jieba
import os, io
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus(u"wiki_seg.txt")
if os.path.exists("./wiki_model"):
model = word2vec.Word2Vec.load('./wiki_model')
else:
#这里迭代次数iter默认为5,我使用的是100,生成size=100维词向量,出现少于min_count=5次的词忽略
model = word2vec.Word2Vec(sentences, min_count=5, size=100, iter=100)
model.save("./wiki_model")
#下面是测试生成的模型
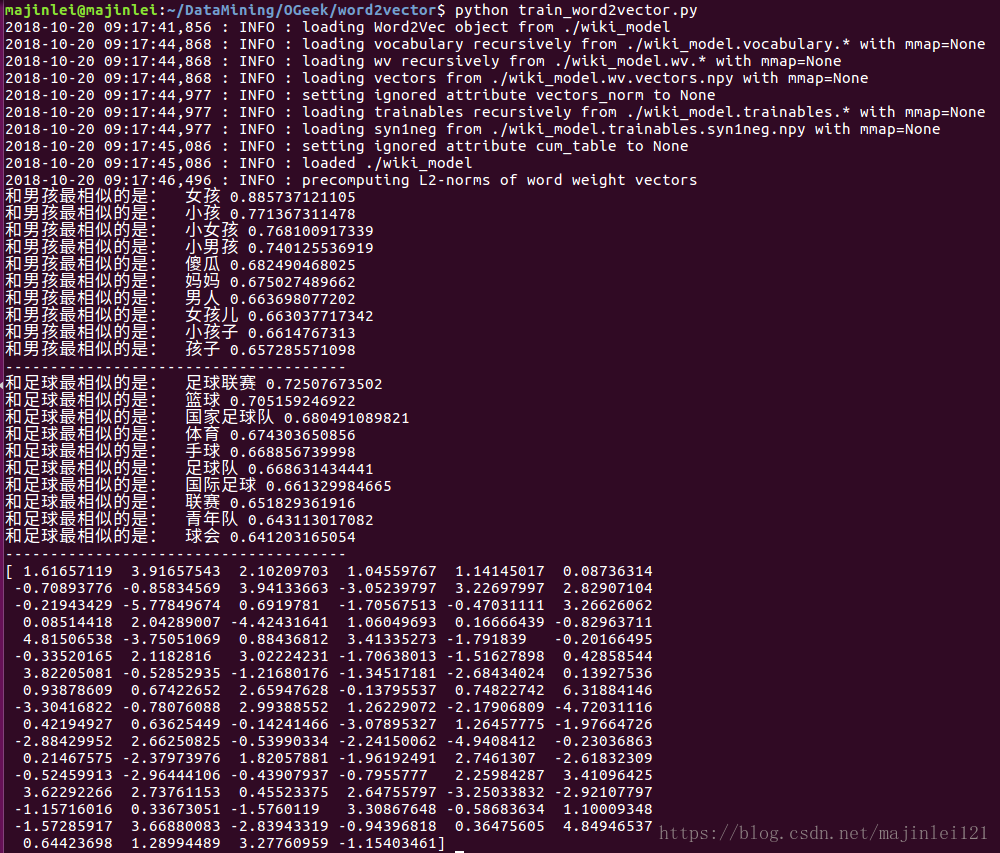
y = model.most_similar(u'男孩', topn = 10)
for item in y:
print '和男孩最相似的是: ', item[0], item[1]
print '--------------------------------------'
y = model.most_similar(u'足球', topn = 10)
for item in y:
print '和足球最相似的是: ', item[0], item[1]
print '--------------------------------------'
print model[u'早餐']
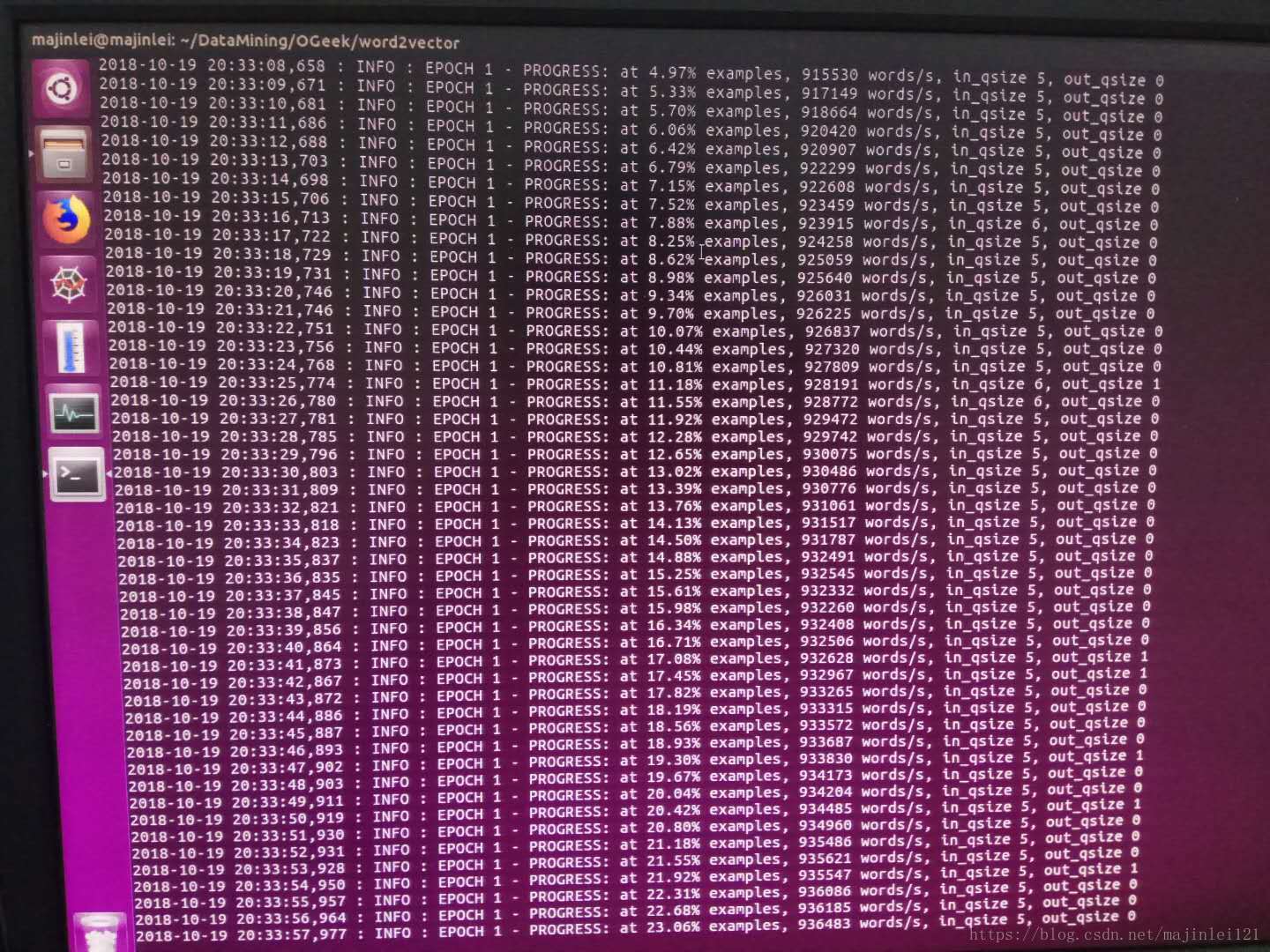
训练100次大约用了6个小时,下面是训练截图
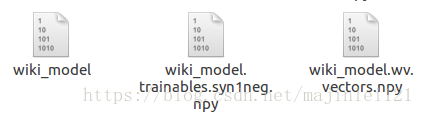
训练完成后会生成三个文件,如下图
测试输出结果为