前面一篇写了 用gensim 训练word2vec 和glove各自的语料训练方式, 现在给出用word2vec来训练wiki中文语料的code
首先从wiki上下载wiki中文语料 下载地址是https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz
分为以下几个步骤:
1. 下载 下载地址是https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz
2. 下载后使用WikiExtractor.py 来提取标题和正文
3. 利用opencc来将提取的文本进行转换, 将繁体转换成简体
操作完后,会生成存粹简体的语料,其中详细的操作步骤请参考 https://blog.csdn.net/u013421941/article/details/68947622
这样wiki中文简体的语料 我们就处理好了,这时候开始要进行分词等一些列操作了
def jieba_cut(filename, cut_filename):
with open(filename, 'rb') as f:
mycontent = f.read()
jieba_content = jieba.cut(mycontent, cut_all=False)
final_file = ' '.join(jieba_content)
final_file = final_file.encode('utf-8')
with open(cut_filename, 'wb+') as cut_f:
cut_f.write(final_file)
利用jieba_cut函数来对语料做分词处理,这里我没有对特殊字符等做操作!
分词完毕就可以用gensim的word2vec model来进行操作了:
#cut_filename 就是前面经过jieba_cut后的文件
def my_word2vec(cut_filename):
mysetence = word2vec.Text8Corpus(cut_filename)
#model = word2vec.Word2Vec(mysetence, size=300, min_count=1, window=5, hs=5)
model = word2vec.Word2Vec(mysetence, size=100, min_count=1, window=5, hs=5)
model.save('./model/zh_wiki_global.model')
return model
model = my_word2vec(cut_filename)
for key in model.similar_by_word(u'爸爸', topn=10):
print(key)
print('*****************')
for key in model.similar_by_word(u'对不起', topn=10):
print(key)
运行上面的代码后得出:
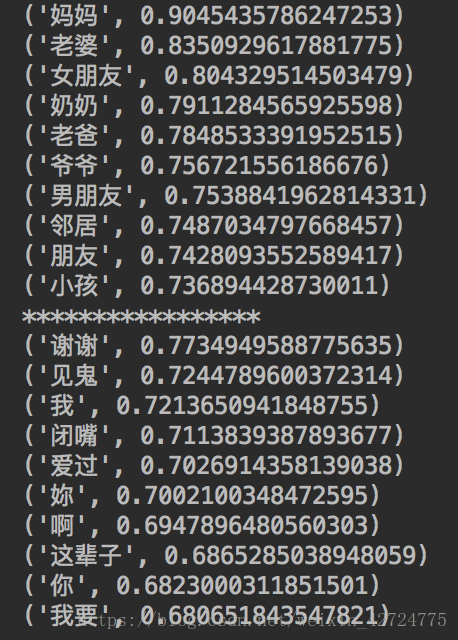
可以看出爸爸 跟妈妈是最匹配的 相似度有0.9! 但是‘我爱你’的匹配就不是很理想了!

我的模型参数是:size=100, min_count=1, window=5, hs=5 大家可以调整一下 结果得到的会不一样! 原本我想size=300的 但是我电脑跑不起来~~~ 其他的都可以改, 具体效果如何我就不贴出来了, 因为电脑一般,跑一次要蛮久的!
详细代码我会上传 github! 如果有哪里错误的地方 请大家指出! 一起讨论才会进步, 一个人埋头进步太慢了!