版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/majinlei121/article/details/83210778
上篇将wiki中文语料已经下载下来(wiki中文文本语料下载并处理 ubuntu + python2.7),并且转为了txt格式,本篇对txt文件进行分词,分词后才能使用word2vector训练词向量
分词python程序为(使用jieba分词)
# -*- coding: utf-8 -*-
#!/usr/bin/env python
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
from gensim.models import word2vec
import logging, jieba
import os, io
stop_words_file = "stop_words.txt"
stop_words = list()
with io.open(stop_words_file, 'r', encoding="gb18030") as stop_words_file_object:
contents = stop_words_file_object.readlines()
for line in contents:
line = line.strip()
stop_words.append(line)
data_file = 'wiki.txt'
i = 1
with io.open(data_file, 'r', encoding='utf-8') as content:
for line in content:
seg_list = list(jieba.cut(line))
out_str = ''
for word in seg_list:
if word not in stop_words:
if word.strip() != "":
word = ''.join(word)
out_str += word
out_str += ' '
print 'fenci:' + str(i)
i += 1
with io.open('wiki_seg.txt', 'a', encoding='utf-8') as output:
output.write(unicode(out_str))
output.close()
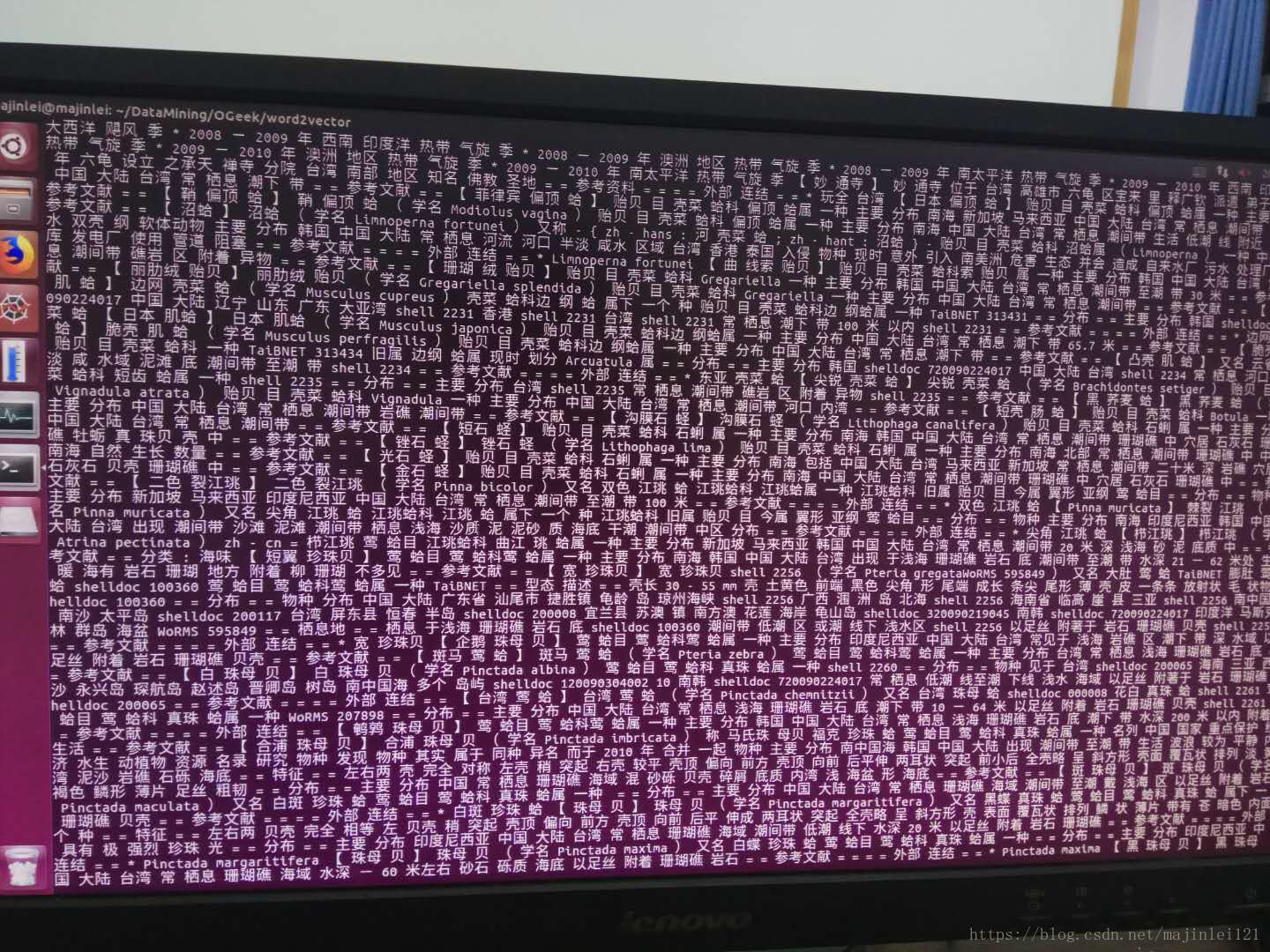
最后会输出一个 wiki_seg.txt
由于文件很大(1.8G),所以程序跑的时间很长,具体时间忘记了
分词后的文件打印出来是这样的
# -*- coding: utf-8 -*-
#!/usr/bin/env python
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_score
from gensim.models import word2vec
import logging, jieba
import os, io
words_file = "wiki_seg.txt"
words = list()
i = 0
with io.open(words_file, 'r', encoding="utf-8") as words_file_object:
contents = words_file_object.readlines()
for line in contents:
print line
i += 1
if i == 200:
break