目录
0 前言
《词向量之Word2Vec数学原理以及源代码详解》很好的讲解了Word2Vec的原理以及一些源码的解读,Word2Vec的词向量有两种方式实现,一种是谷歌大佬们自己写的word2vec,还有一个是gensim库,由于大多数人使用的是python,所以使用gensim库的人很多。本文会详细介绍gensim里的word2vec模型,gensim包含的其他模型不介绍。
1 gensim库
Gensim(http://pypi.python.org/pypi/gensim)是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。 主要用于主题建模和文档相似性处理,它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法。Gensim在诸如获取单词的词向量等任务中非常有用。
1.1 gensim.models.word2vec API概述
首先使用pip install gensim安装gensim库。
然后倒入word2vec模块from gensim.models.word2vec。注意这里倒入的是小写的word2vec这个.py文件,其中大写的Word2Vec模型实现在这个文件中,使用模型时需要使用语句word2vec.Word2Vec()来创建模型。
class Word2Vec(utils.SaveLoad):
def __init__(
self, sentences=None, size=100, alpha=0.025, window=5, min_count=5,
max_vocab_size=None, sample=1e-3, seed=1, workers=3, min_alpha=0.0001,
sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=hash, iter=5, null_word=0,
trim_rule=None, sorted_vocab=1, batch_words=MAX_WORDS_IN_BATCH):
- sentences:可以是一个list,对于大语料集,建议使用LneSentence以及PathLineSentence来构建。创建模型的时候如果没有这个参数,会传入一个None对象,在后续训练时可以再传入训练的语料。
- size:是指词向量的维度,默认为100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。大的size需要更多的训练数据,但是效果会更好. 推荐值为100到300。
- window:窗口大小,即词向量上下文最大距离,即包含中心词的前window个单词和后window个单词,注意在word2vec中是在[1,windows]之间随机取值,并不是固定的window个。window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。个人理解应该是某一个中心词可能与前后多个词相关,也有的词在一句话中可能只与少量词相关(如短文本可能只与其紧邻词相关)。
- min_count: 需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。可以对字典做截断, 词频少于min_count次数的单词会被丢弃掉。
- negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。
- cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的为上下文的词向量之和,为1则为上下文的词向量的平均值。默认值是1,不推荐修改默认值。
- iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值,在下文的语料中,我使用5次,训练的效果不是很好。
- alpha: 是初始的学习速率,在训练过程中会线性地递减到min_alpha。在随机梯度下降法中迭代的初始学习率,默认是0.025。
- min_alpha: 由于算法支持在迭代的过程中逐渐减小学习率,min_alpha给出了最小的学习率。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
- max_vocab_size: 设置词向量构建期间的RAM限制,设置成None则没有限制。
- sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)。
- seed:用于随机数发生器。与初始化词向量有关。
- workers:用于控制训练的并行数。
- sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
- hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
- negative:如果大于零,则会采用negativesampling,用于设置多少个noise words(一般是5-20)。
- hashfxn:hash函数来初始化权重,默认使用python的hash函数。
- batch_words:每一批的传递给线程的单词的数量,默认为10000。
- trim_rule:用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)。
- sorted_vocab: 如果为1(默认),则在分配word index 的时候会先对单词基于频率降序排序。
1.2 gensim训练word2vec词向量步骤
使用Gensim训练Word2vec十分方便,训练步骤如下:
- 1)将语料库预处理:一行一个文档或句子,将文档或句子分词(以空格分割,英文可以不用分词,英文单词之间已经由空格分割,中文预料需要使用分词工具进行分词,常见的分词工具有StandNLP、ICTCLAS、Ansj、FudanNLP、HanLP、结巴分词等);
- 2)将原始的训练语料转化成一个sentence的迭代器,每一次迭代返回的sentence是一个word(utf8格式)的列表。可以使用Gensim中word2vec.py中的LineSentence()方法实现;
- 3)将上面处理的结果输入Gensim内建的word2vec对象进行训练即可。
2 训练搜狗语料
语料:搜狗实验室新闻作为训练语料 搜狗实验室:http://www.sogou.com/labs/resource/ca.php
我下载的是完整版,一共600多M,解压后1个多G,可以在首页看看数据的格式。
注意下载时需要登记信息
解压后的数据是news_sohusite_xml.dat,这是gbk格式的数据,需要将编码转换成utf-8格式,并且只需要content的内容,其他的都不需要,这个时候就需要使用linux命令来解决,由于我的系统是windows10,需要下载一个WSL来运行linux命令。具体的见我的博客:
windows下使用Linux命令
取出 中的内容,在linux下执行如下命令:
cat news_sohusite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>" > corpus.txt
得到了1.71个G的corpus.txt文件,文件太大记事本打不开这个文件。
注意以下所有程序都在jupyter notebook中运行,jupyter notebook下载可以通过Anaconda来实现,见:
Windows 10下的Anaconda安装与使用
2.1 分词
送给word2vec的文件是需要分词的,分词可以采用jieba分词实现,安装jieba 分词
使用pip install jieba对原始文本进行分词:
file_path = './corpus.txt'
file_segment_path = './corpus_segment.txt'
train_file_read = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
train_file_read.append(line)
train_file_read
得到:

print(len(train_file_read))查看一共有多少段话,输出1411996。
import jieba
# jieba分词后保存在列表中
train_file_seg = []
for i in range(len(train_file_read)):
train_file_seg.append([' '.join(list(jieba.cut(train_file_read[i][9:-11], cut_all=False)))])
if i % 100 == 0:
print(i)
train_file_seg
分词会花费一个多小时
# 保存分词结果到文件中
with open(file_segment_path, 'w', encoding='utf-8') as f:
for i in range(len(train_file_seg)):
f.write(train_file_seg[i])
f.write('\n')
# 加载分词
seg_sentences = []
with open(file_segment_path, 'r', encoding='utf-8') as f:
seg_sentences = f.readlines()
seg_sentences

可以看到有空白段
除去空白段

一共还剩1298156段话

2.2 构建词向量
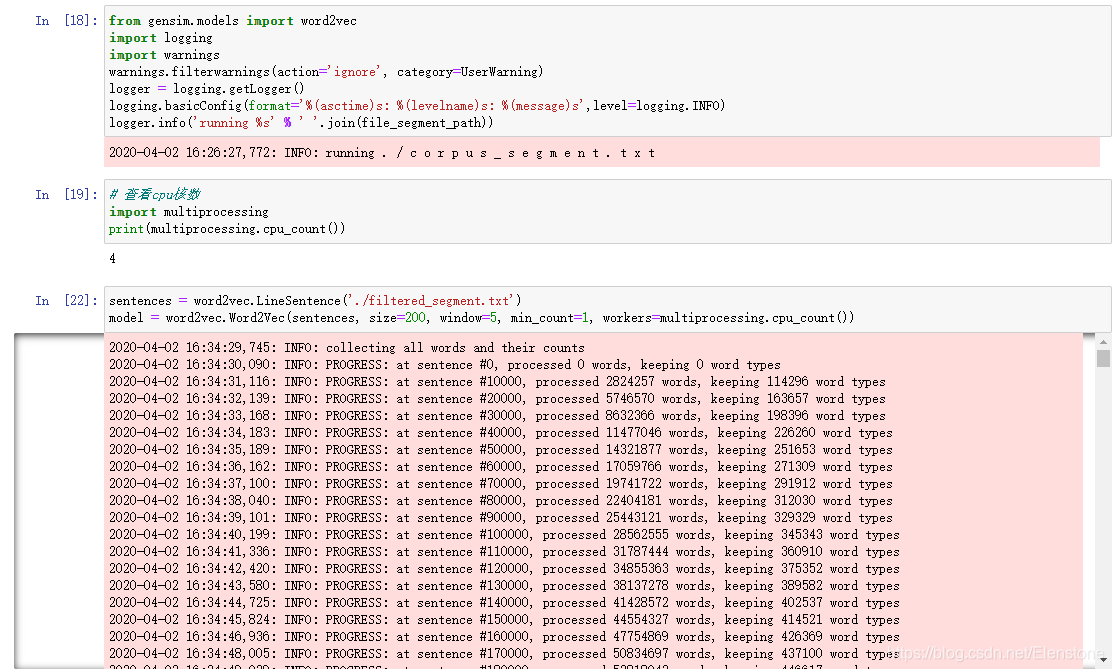
训练会花费一个多小时
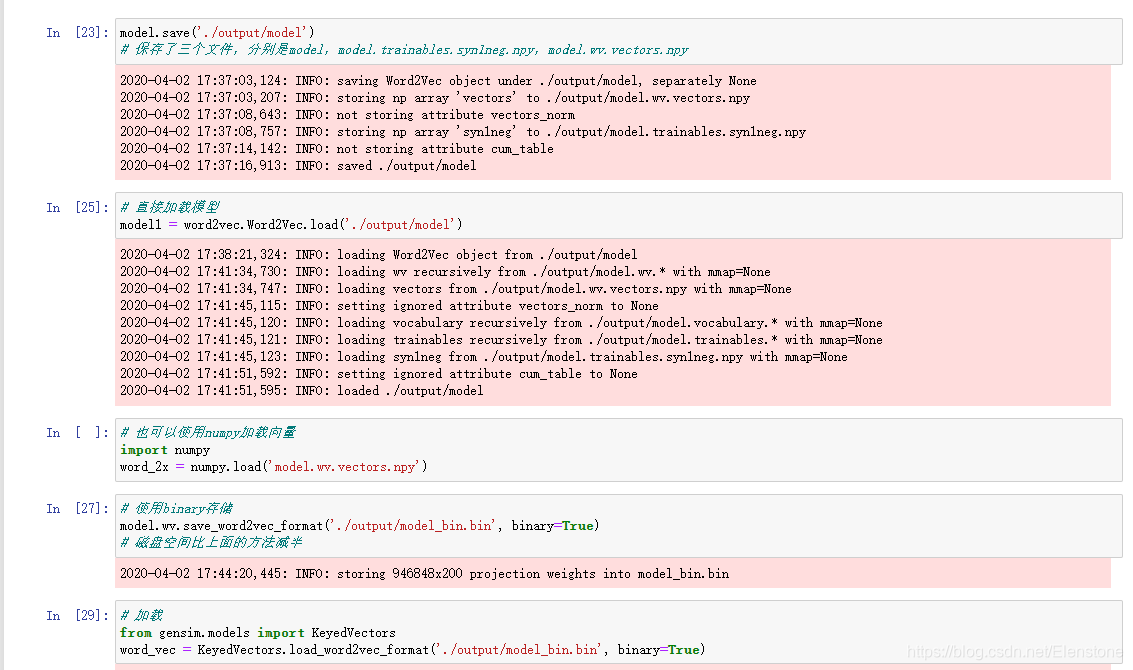
2.3 保存和加载模型
2.4 词向量使用
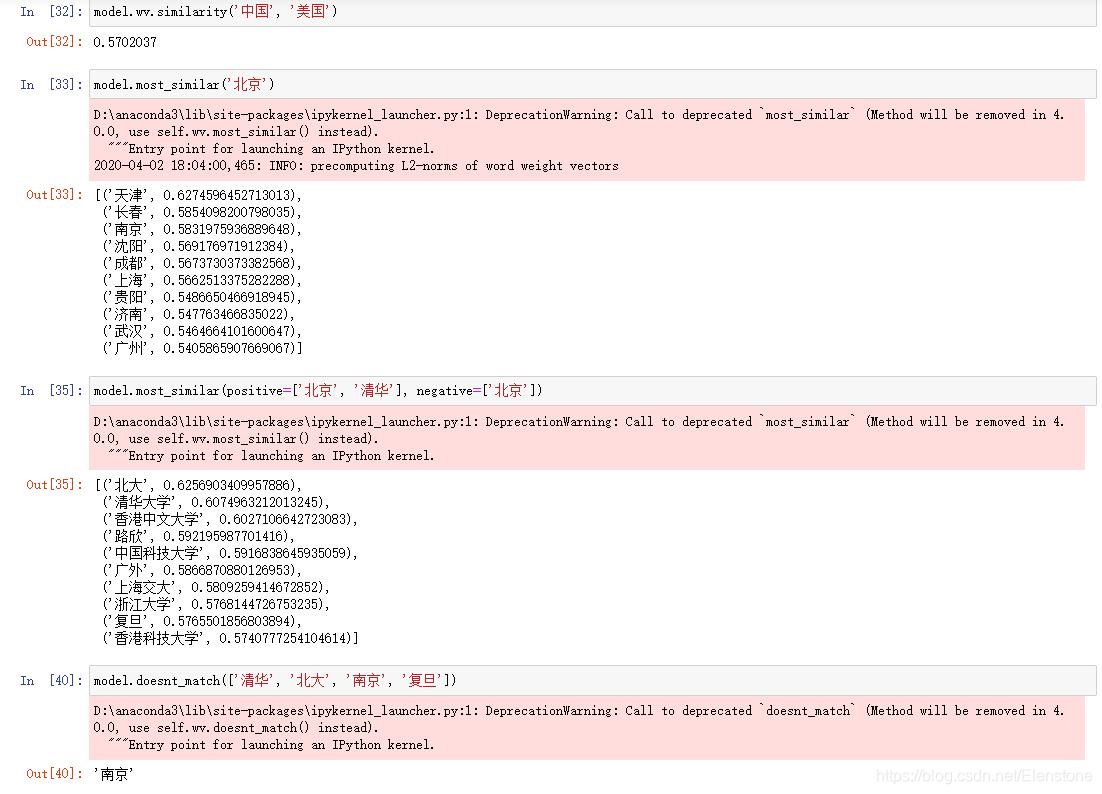
注意model.similarity在以前也是可以使用的,新版本需要model.wv.similarity
3 二维空间显示词向量
见我的github
