JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
python 2.7自带了JSON,使用import json 就可以调用了。
官方文档:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/#
一、JSON
json就是javascript的数组和对象,通过这两种结构可以表示各种复杂的结构:
对象:对象在js中表示为{ }括起来的内容,数据结构为 { key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。
数组:数组在js中是中括号[ ]括起来的内容,数据结构为 ["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
1. json.loads()
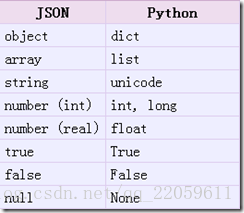
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import json
strList = '[1, 2, 3, 4]'
print json.loads(strList)
# [1, 2, 3, 4]
strDict = '{"city": "北京", "name": "大猫"}'
print json.loads(strDict)
# json数据自动按Unicode存储输出结果:
[1, 2, 3, 4]
{u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}
# 注意:json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
# chardet.detect()返回字典, 其中confidence是检测精确度
print json.dumps(dictStr)
# '{"city": "\\u5317\\u4eac", "name": "\\u5927\\u5218"}'
输出:{"city": "\u5317\u4eac", "name": "\u5927\u732b"}
print chardet.detect(json.dumps(dictStr))
输出:{'confidence': 1.0, 'language': '', 'encoding': 'ascii'}
print json.dumps(dictStr, ensure_ascii=False)
# {"city": "北京", "name": "大刘"}
print chardet.detect(json.dumps(dictStr, ensure_ascii=False))
# {'confidence': 0.99, 'encoding': 'utf-8'}