- 爬虫数据解析与提取
- 正则表达式规则
-
普通字符语法
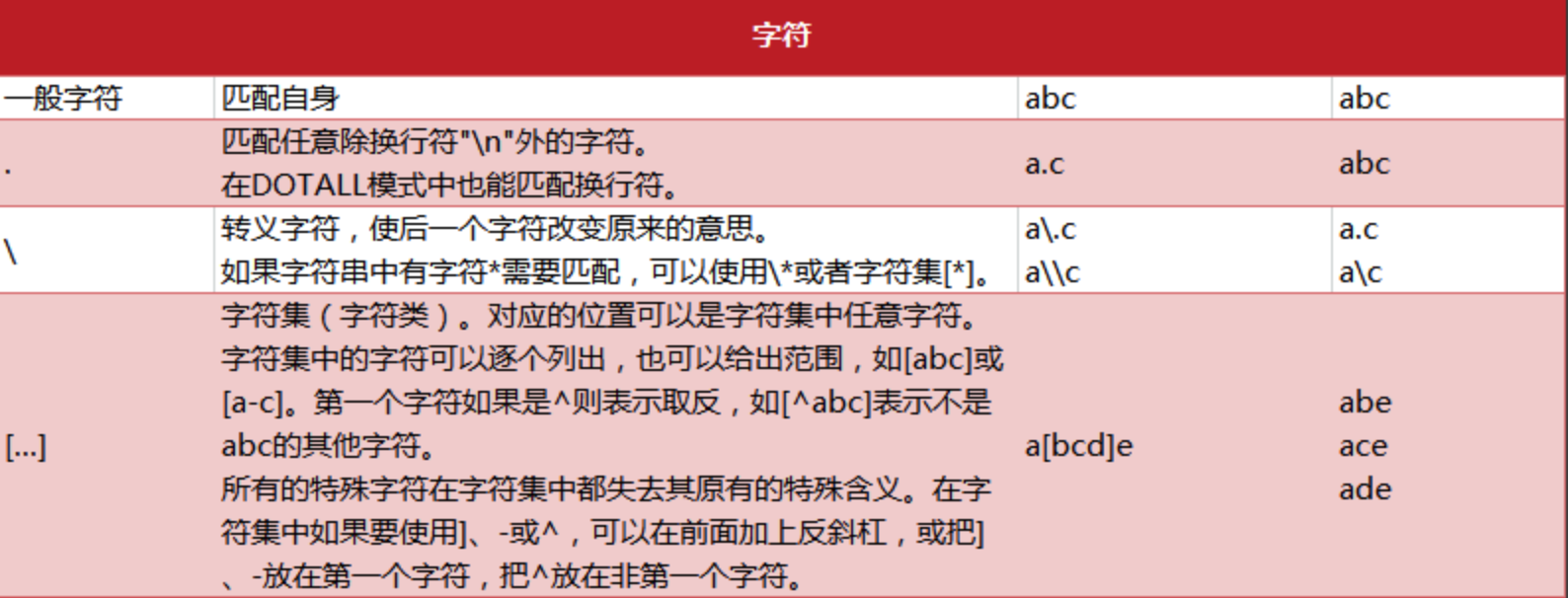
-
预定义字符集语法

-
数量词语法
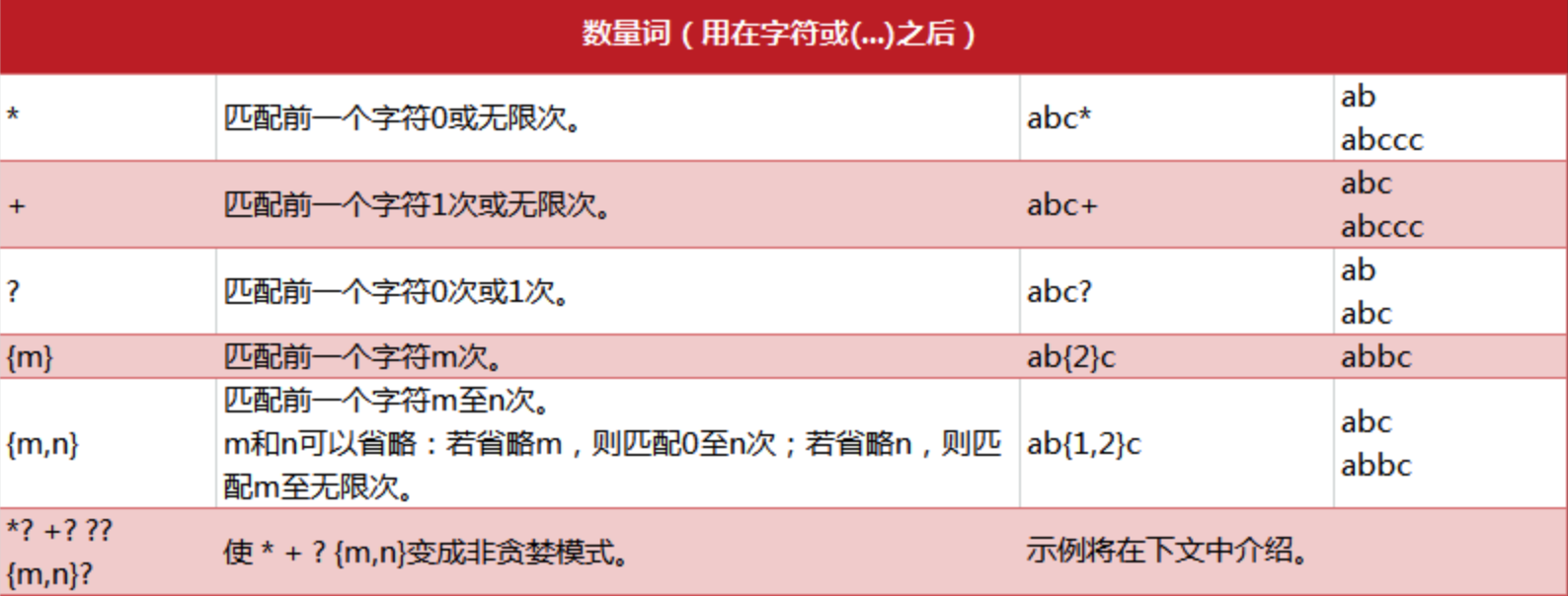
贪婪与非贪婪:
作用:控制数量词的匹配个数
用法:默认是使用贪婪模式;在数量词后加上一个?后,则表示使用非贪婪模式
匹配后贪婪与非贪婪模式的匹配个数:
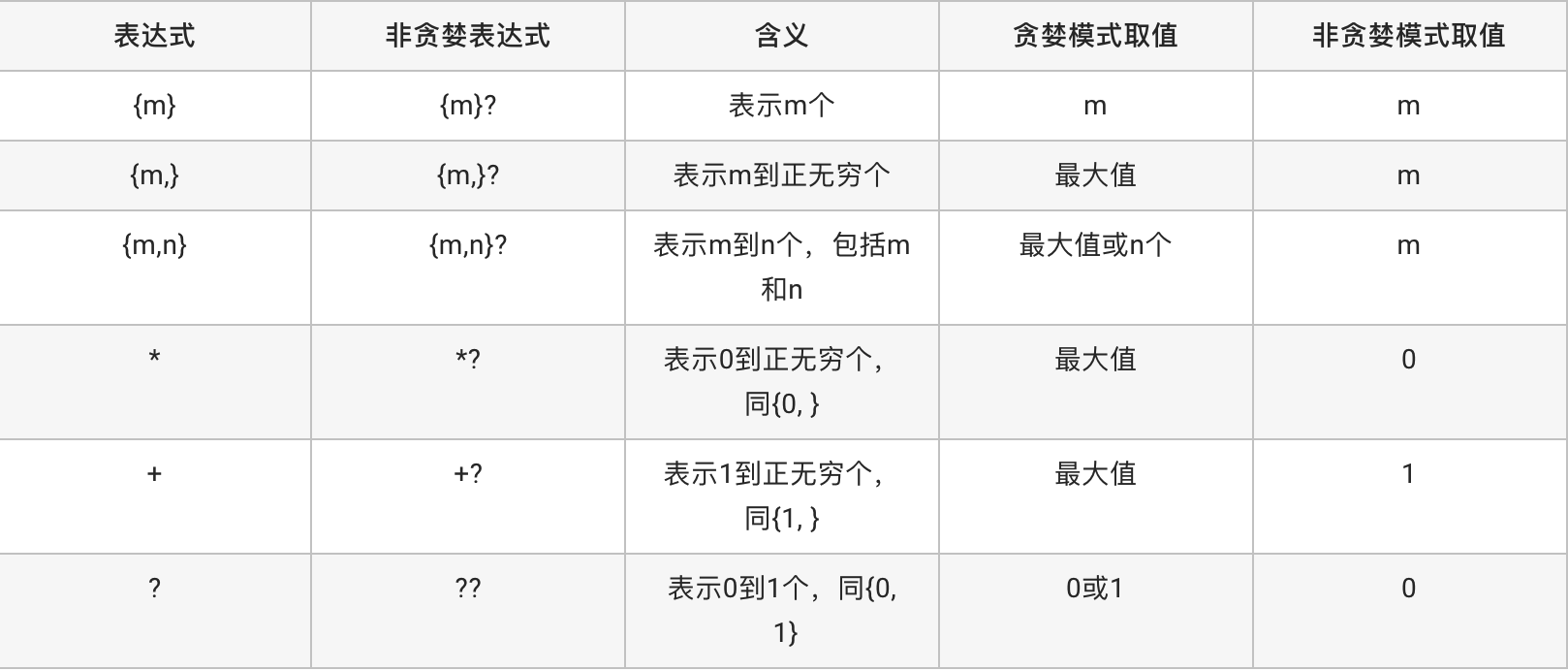
In [35]: re.match("\d+.\d{2,6}", “3.1415926”).group()
Out[35]: ‘3.141592’
In [36]: re.match("\d+.\d{2,6}?", “3.1415926”).group()
Out[36]: ‘3.14’ -
边界匹配语法

\b相当于\w和\W的边界,可以用来匹配出单词;
\B则常用来判断单词的连贯性;
注意:必须使用r,将字符串变为正则模式,因为\b在普通字符串中也是具有含义的。 -
逻辑、分组语法
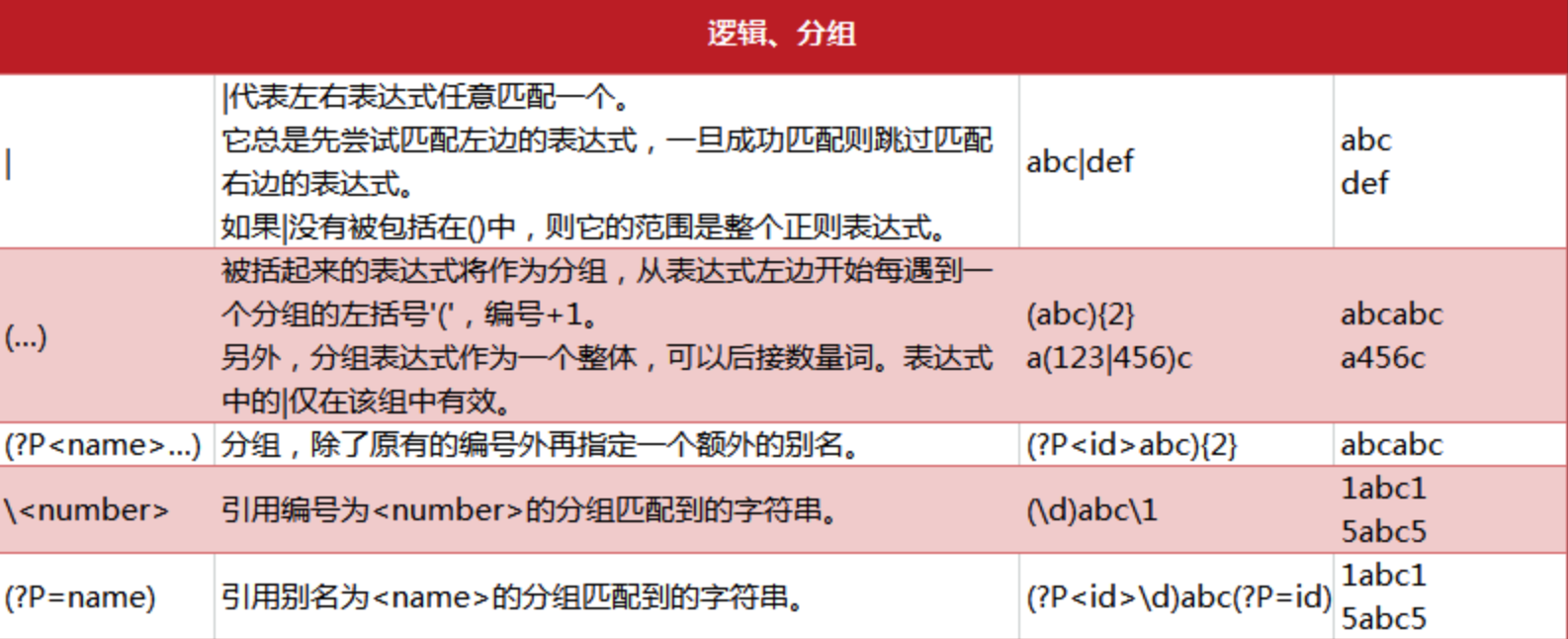
-
特殊构造语法
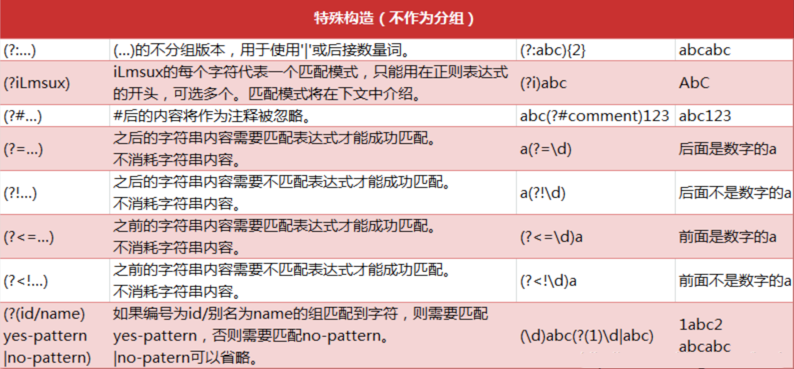
- xpath
-
节点选取基本路径表达式:

-
节点选取通配符

-
Xpath谓语条件
所谓"谓语条件",就是对路径表达式的附加条件,都写在方括号"[]"中,表示对节点进行进一步的筛选
谓语条件语法: -
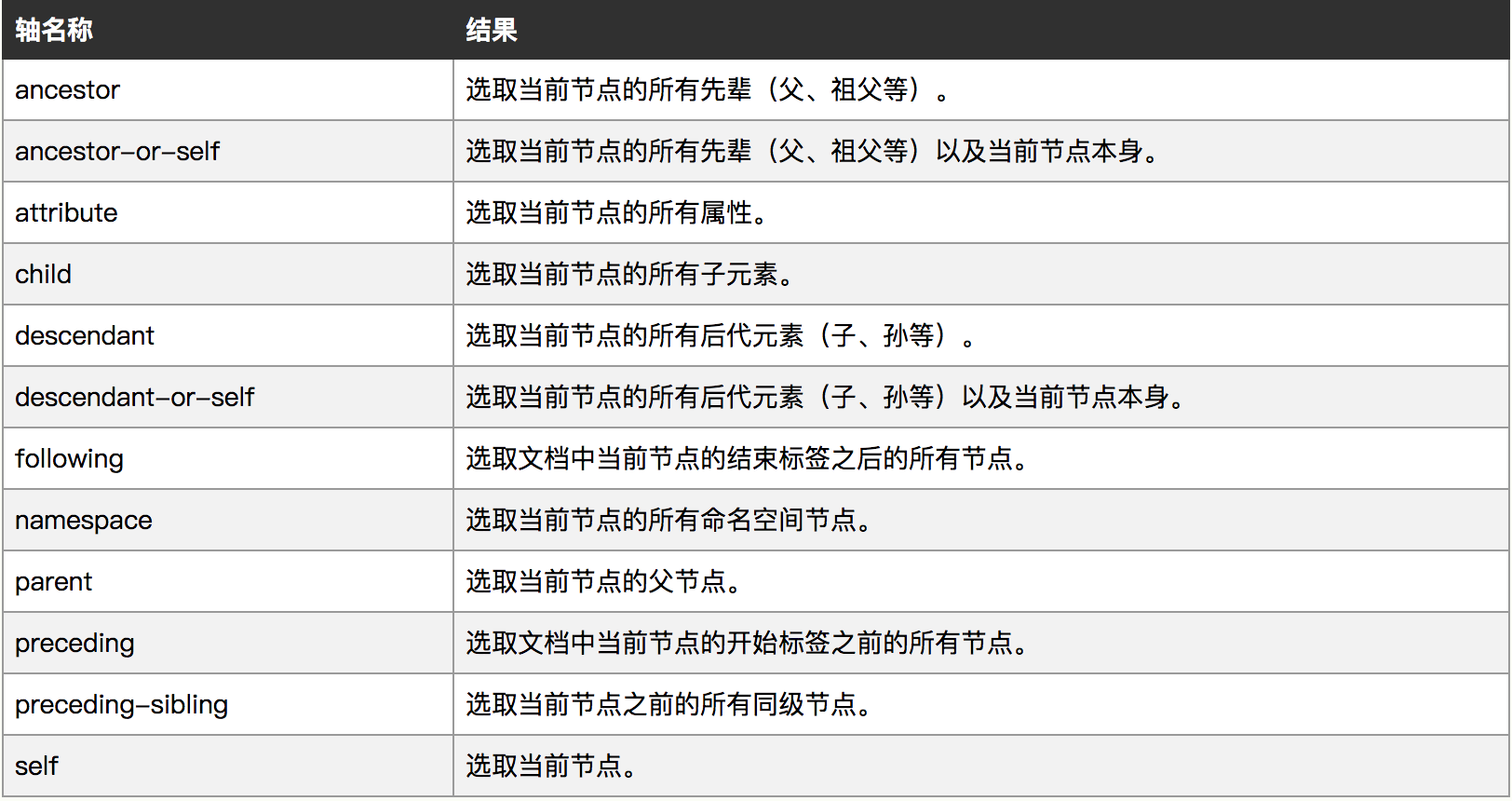
Xpath轴
轴其实就是以当前节点(自己)为中心,来选取其他节点
- lxml模块
lxml模块是一个在Python中用于处理XML和HTML的工具。特点就是快、性能强。
安装:
lxml依赖于两个C语言编写的库libxml2-dev、libxslt-dev,以centos为例:
sudo yum install libxml2-dev libxslt-dev
然后在虚拟环境或其他Python解释器环境安装pip install lxml
爬虫中lxml模块常用方法或对象:lxml模块 API文档- lxml
Element
ElementTree - lxml.etree
HTMLParser
XMLParser
XPath
parse: 对文件或二进制流数据进行解析,返回ElementTree对象
fromstring: 对字符串进行解析,返回Element对象
tostring: 对Element对象进行格式化,返回bytes类型字符串数据
HTML: 相当于fromstring方法指定HTMLParser
XML: 相当于fromstring方法指定XMLParser
- lxml
lxml数据解析:将原始数据进行转换为格式完整的DOM对象
- css选择器
- BeautifulSoup4文档
安装pip install bs4 - bs4内置对象:
- Tag:Tag对象与XML或HTML原生文档中的tag相同,代表标签节点
- BeautifulSoup:BeautifulSoup 对象表示的是一个文档的全部内容
- NavigableString:NavigableString类中包装有tag中的字符串
- Comment:表示文档中的注释部分字符串
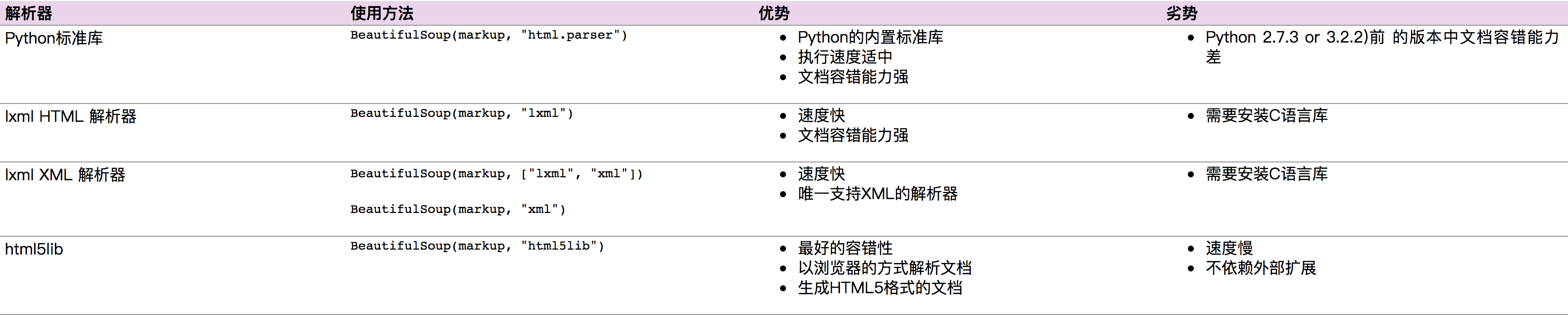
- bs4可以使用的解析器(一般用
lxml)
- bs4数据提取:
方法一:搜索文档树之select方法
方法二:搜索文档树之使用find家族方法
- bs4数据提取:
- pyquery模块:一个类似jquery的python库
pyquery允许在xml、html文档上进行jquery查询
pyquery的API设计与jquery非常类似
pyquery可以使用lxml进行快速的xml和html解析
安装:pip install pyquery
API使用
- JsonPath
jsonpath是一个专门用于快速处理json数据的模块。
jsonpath规则之于json,如xpath规则之于xml/html- json数据特征
json中只有两种结构:对象和数组
对象:在json中是“{}”括起来的内容,数据结构为{“key”:“vlaue1”,“key2”: “value2”…}的键值对结构
数组:在json中是‘[]’括起来的内容,数据结构为[“python”,“jsonpath”,“html”…],与所有的语言一样,使用索引获取值
json的字段的类型可以是数字,字符串、数组、对象。其中字符串必须使用双引号表示。 - 安装:pip install jsonpath
- json数据特征
- jsonpath基础语法
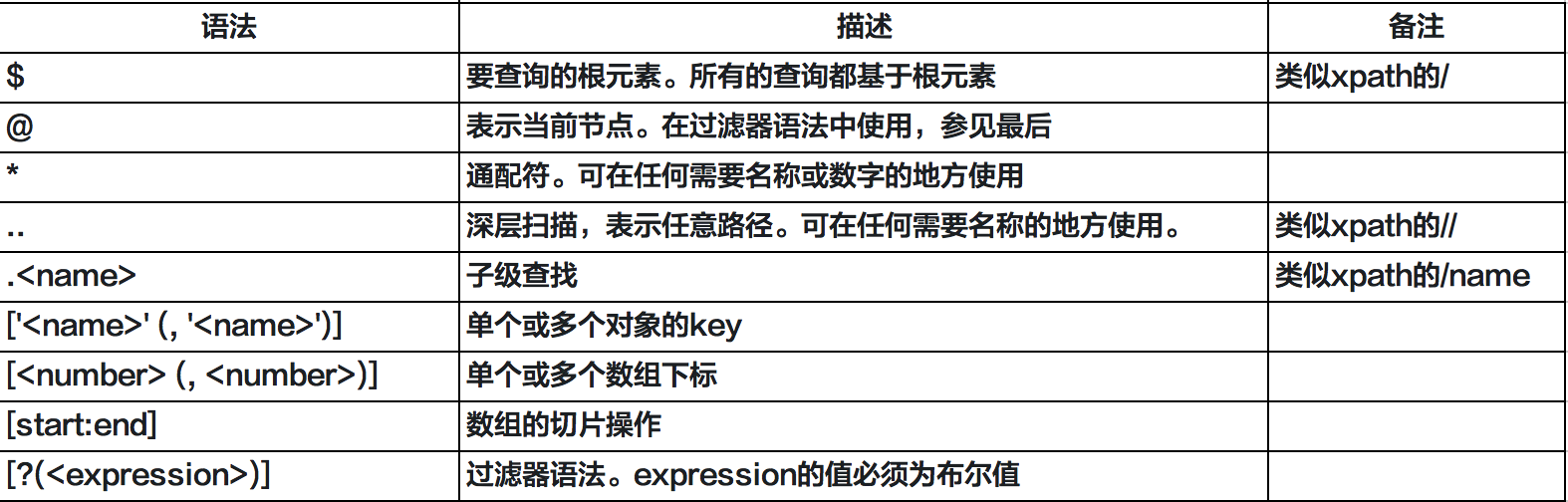
- jsonpath运算符
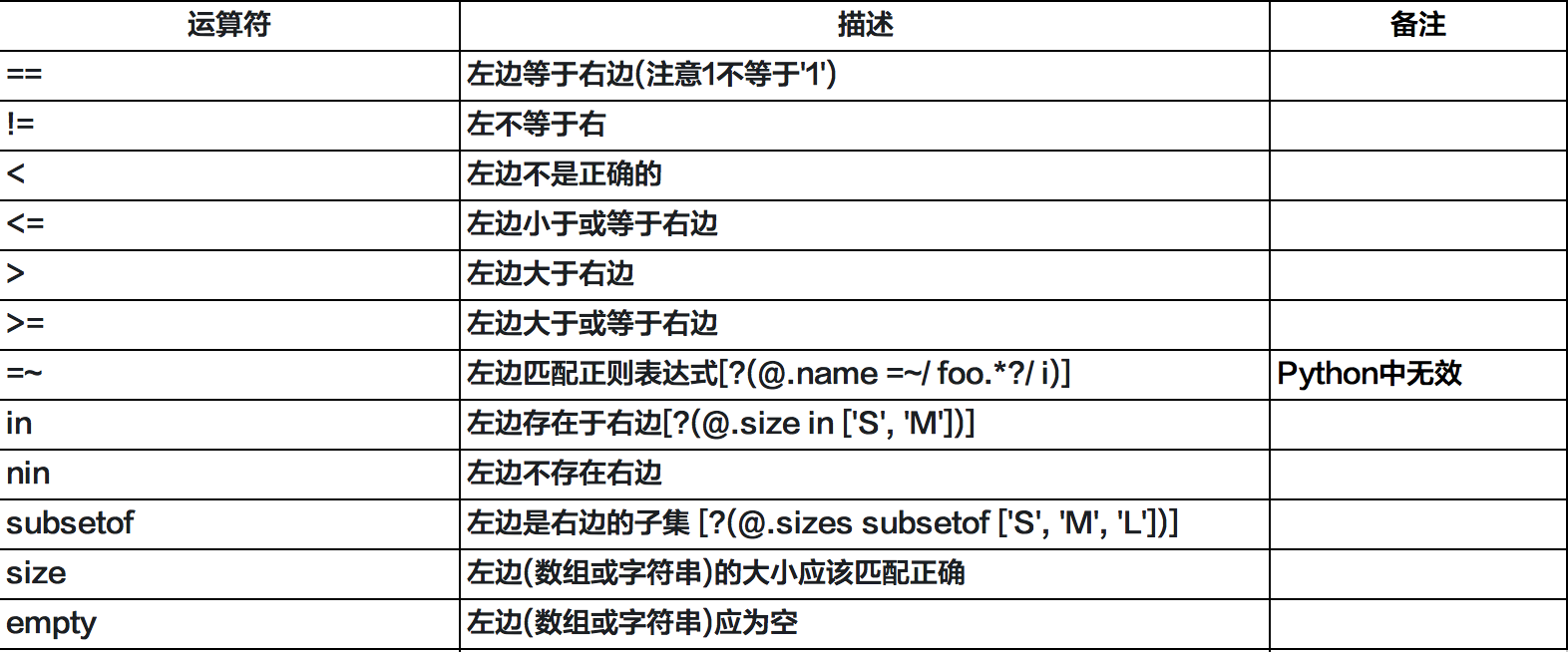
注意: Python中使用jsonpath模块时,必须将json字符串转换为python内置对象,如对象–>字典,数组–>列表。 因为python中需要使用json.loads或load方法将json数据进行简单转换。
-
Python中运行JS
- js2py
js2py是纯的Python实现的库,用于在python中运行js代码。
本质上是将js代码翻译成Python代码。
js2py源码
饭粒:JS代码翻译成python代码import js2py print(js2py.translate_js("console.log('hello world')")) # 将js文件翻译为python脚本 # js2py.translate_file('demo.js', 'demo.py')
注意:由于翻译代码需要一定时间,简单的代码尽量自己翻译,逼不得已再使用js2py模块。
- pyexecjs
pyexecjs同js2py一样,用于在python中执行js代码。
其原理和js2py不同,因为相当于作为python与其他的js运行环境(如pyv8、nodejs等)的桥梁,js代码的运行是直接在对应的js运行环境中,而不是将js代码进行翻译,因此理论上pyexecjs的执行速度是比js2py快的。
然鹅:pyexecjs模块的作者已经不维护该模块了。
推荐使用node环境。因为node可以安装很多第三方模块,帮助解决问题,同时有的网站前端代码本身就借助了node的一些第三方模块。 - 两个模块各有各自的特点,大家应该都应该掌握它们的使用方法,如果必要,互相搭配使用可能效果会更好
- js2py
- 爬虫数据清洗
数据清洗:简单的说,就是对数据进行审查和校验。
数据清洗的目的主要是解决数据质量问题,删除重复信息、纠正存在的错误,从而保证数据一致性。
根据不同的业务场景有不同的需要解决的问题,这里以爬虫主要业务为例,数据清洗大致要解决的问题: - 数据一致性问题
- 数据一致性是指所获取的数据,从多个维度考量数据的取值是否合乎预期要求。如数据的单位是否统一、数据取值标准是否统一、数据分类标准/分类依据是否统一等等
- 数据完整性问题
- 数据完整性是指数据信息不完整。如图书数据中缺少出版社、出版日期等;人类数据中缺少性别、年龄等。
- 数据唯一性问题
- 数据唯一性是指数据的重复性过滤问题,重复数据,只应保留一条。
- 数据准确性问题
- 数据准确性是指根据数据的准确性原则,判断数据是否准确的问题。如数据有误(格式不对、或超过当前时间)、无效数据、冗余数据无关数据过多等等
-
数据存储
- 文件存储
- CSV文本存储
CSV文本存储是一种非常常用的存储方式:- 结构简单:列行数据分别以逗号和换行符来分割
- 使用便捷:可直接被pandas、numpy等数据处理模块或也可直接导入Excel中进行处理
- JSON文本存储
- 媒体文件存储
媒体文件数据(如图片、视频等)存储需注意:
一:媒体文件数据,都是二进制类型数据,因此打开文件式,必须以二进制方式打开;
二:如果文件数据较大的情况下,如视频数据,可能会考虑分批写入,那么此时注意必须使用追加模式写入数据;
三:如果需要考虑维护文件的路径、大小等数据,那么需要考虑将这些数据单独进行存储并维护。
- 数据库存储
- 关系型数据库:
1)MySQL: PyMySQL
PyMySQL的github地址
PyMySQL的文档地址
2)PostgreSQL: psycopg2
psycopg2的github地址
psycopg2的文档地址 - 非关系数据库:
MongoDB: pymongo
pymongo的github地址
pymongo的文档地址
ORM使用mongoengine
github地址
文档地址
