数据处理的两种方式
- re正则表达式:通过对数据文本进行匹配,来得到所需的数据
- BeautifulSoup:通过该类创建一个对象,通过对类里面封装的方法进行调用,来提取数据。
bs4
对标签进行查找
- 获取标签的内容
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('hello.html'),'html5lib')
print(soup.title)
print(soup.p) #只能匹配到第一个P标签
print(type(soup.title)) #一个元素标签
结果:

- 获取标签的属性
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('hello.html'),'html5lib')
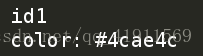
print(soup.p['id'])
print(soup.p['style'])
结果:
- 获取标签的文本内容
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('hello.html'),'html5lib')
print(soup.title.text)
print(soup.title.string)
结果:

- 获取标签的子节点
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('hello.html'),'html5lib')
print(soup.div.children) #返回的是一个可迭代对象
print(soup.head.contents) #返回的是一个列表
for i in soup.div.children:
print(i)
结果:

对对象进行操作
- 查找指定标签的内容
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('hello.html'),'html5lib')
#查找指定标签的内容
res = soup.find_all('p') #返回的是一个列表
print(res)
#配合正则的使用,对正则表达式进行编译可以提高查找的速率
res = soup.find_all(re.compile('di\w')) #find_all方法返回的是一列表
print(res)
结果:

- 详细查找指定标签
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('hello.html'),'html5lib')
print(soup.find_all('p',id='id1'))
print(soup.find_all('p',id=re.compile('id\d')))
#注意:根据类匹配标签时,class后面要加一个_,是为了与关键字class重复
print(soup.find_all('p',class_=re.compile('class\d')))
结果:

- 详细查找多个标签的内容
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('hello.html'),'html5lib')
#注意:向find_all里面添加多个匹配时,一个列表的形式传入
print(soup.find_all([re.compile('p'),re.compile('div')]))
结果:

- css常见的匹配
#css常见的选择器:标签选择器,类选择器,id选择器,属性选择器
#标签选择器
res1 = soup.select('p') #返回的是一个列表
print(res1)
#类锁选择器
res = soup.select('.class1')
print(res)
#id选择器
res = soup.select('#id2')
print(res)
#属性选择器
res = soup.select("p[id='id1']")
print(res)
结果:

bs4的简单引用
爬取多个电影的id和名字
from bs4 import BeautifulSoup
import requests
url = 'https://movie.douban.com/cinema/nowplaying/xian/'
'''
<li id="26425063" class="list-item" data-title="无双"
data-score="8.1" data-star="40" data-release="2018"
data-duration="130分钟" data-region="中国大陆 香港"
data-director="庄文强"
data-actors="周润发 / 郭富城 / 张静初"
data-category="nowplaying" data-enough="True" data-showed="True"
data-votecount="199648" data-subject="26425063">'''
def getPagehtml(url):
return requests.get(url).text
def dealdata(text):
# 利用BeautifulSoup对传入的html文件进行一个解析,并返回一个对象
soup = BeautifulSoup(text,'html5lib')
#查找所有类名为list-item的li标签,把匹配到的内容返回给一个列标
li_list = soup.find_all('li',class_="list-item")
movie_info=[]
for i in li_list:
onn_movie_info = {}
#对匹配到标签内容用标签的属性作为索引去获取
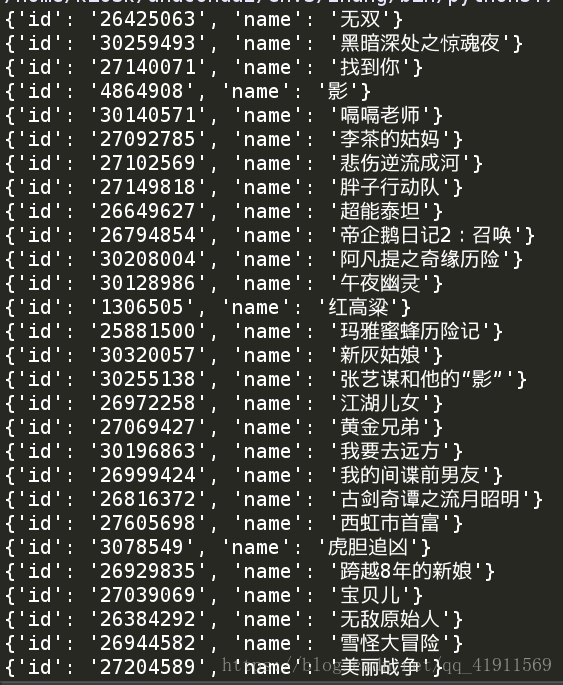
onn_movie_info['id']=i['id']
onn_movie_info['name']=i['data-title']
movie_info.append(onn_movie_info)
[print(i) for i in movie_info]
dealdata(getPagehtml(url))
结果:
获取电影的影评信息绘制为词云
import re
import jieba
import wordcloud
import requests
from bs4 import BeautifulSoup
import numpy
from PIL import Image
def getPagehtml(url):
return requests.get(url).text
def deal_one_text(text):
soup = BeautifulSoup(text,'html5lib')
tag_li = soup.find_all('span',class_='short')
comment_li = []
for tag in tag_li:
comment_li.append(tag.string)
return comment_li
# deal_one_text(getPagehtml(url))
def create_cloud(text):
# 此函数实现一个绘制词云图片的功能,并将图片保存起来
# 对传入的文本进行切割,返回一个列表,里面存有文本的词语
result = jieba.lcut(text)
#生成一个图片对象
imgobj = Image.open('./img1.jpg')
cloud_mask = numpy.array(imgobj)
wc = wordcloud.WordCloud(
mask=cloud_mask,
width=500,
background_color='snow',
max_font_size=200,
min_font_size=10,
font_path='./font/msyh.ttf',
)
wc.generate(','.join(result))
#生成图片
wc.to_file('./cloud1.png')
def main():
all_comments = []
#对十页的内容进行操作
for i in range(10):
start = i*20
#生成每一页的url
url = 'https://movie.douban.com/subject/26425063/comments?start=%d&limit=20&sort=new_score&status=P' %start
text =getPagehtml(url)
comment = deal_one_text(text)
#将每一页的电影的名字和信息都存入到列表
[all_comments.append(i) for i in comment]
comment_str = "".join(all_comments)
comments = re.findall(r'([\u4e00-\u9fa5]+|[a-zA-Z]+)',comment_str)
print(''.join(comments))
create_cloud(''.join(comments))
main()
结果:

词云图形的绘制
# 对传入的文本进行切割,返回一个列表,里面存有文本的词语
imgobj = Image.open('./img1.jpg')
cloud_mask = numpy.array(imgobj)
wc = wordcloud.WordCloud(
mask=cloud_mask,
width=500,
background_color='snow',
max_font_size=200,
min_font_size=10,
font_path='./font/msyh.ttf',
)
wc.generate(','.join(result))
#生成图片
wc.to_file('./cloud1.png')