爬虫需要你至少知道html标签和css的基本知识,建议先学了再学爬虫
很简单的,只要一天你就能明白html css分别是做什么的了。
不想学就只好边看我说明边自己百度不懂的地方了
完整代码见最后一个代码块,不建议直接拿去用,建议慢慢看懂原理写出你自己独特的代码。
先扔几个参考文档
urllib文档:https://docs.python.org/3.7/library/urllib.html
beautifulsoup中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
re文档:https://docs.python.org/3.7/library/re.html
1.获取文本信息
urllib是python3下载完自带的包
bs4需要下载
配置好环境变量后cmd中输入pip install bs4
from urllib import request
from bs4 import BeautifulSoup
#要抓取的链接
url = "https://blog.csdn.net/qq_36376711/article/details/86614578"
#获取到的内容
content = request.urlopen(url)
#获取网页的源码
encode_html = content.read()
#print(encode_html)#打印出来会发现是编码过的html
#解码,一般是utf-8
html = encode_html.decode("utf-8")
#print(html)#打印发现中文能正常显示了
最简单的访问就完成了(访问只需要urllib库)
下面对获取到的数据进行解析(采用bs4进行解析)
此处以获取该文章阅读数为例
按下F12/或者右键->审查元素。耐心找到该对象的class的值
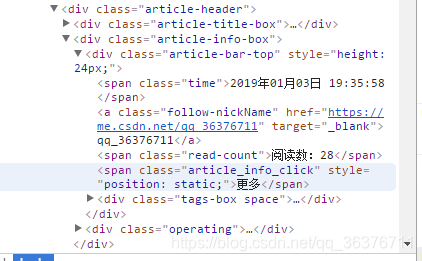
发现阅读数对应的class是 read-count,位于span标签对内
#应用BeautifulSoup对获取到的数据进行格式转换,方便数据处理
soup = BeautifulSoup(html,"html.parser")
#同样方法找到文章标题的字体大小标签,发现是h1(不懂class,h1,标签对是啥的自己先百度html标签看了
#再来)
#一看就知道这个大小的字体只有标题
print("文章:",soup.h1)#直接通过标签属性访问
#找到soup中所有标签名为span,且span对应的class名为read-count的标签对
print("阅读数:",soup.find_all("span","read-count"))#通过标签加类别
打印结果发现
我们不想看到的标签对部分也被打印出来了
于是修改上述部分代码为:
print("文章:",soup.h1.get_text())
#因为count是个列表,所以不能像上面一样直接get_text()
count = soup.find_all("span","read-count")
for c in count:
print("阅读数:",c.get_text())
这种写法在文章被删除,CSDN服务器宕机等情况下都无法正常访问,
单看这个程序你不觉得是个大问题,但是,当你是在多个网址爬取信息,
并汇总处理时,或者通过改变url循环访问不同网址时
我们不希望因为一个网址的问题导致整个程序终止
在高频率访问时,不设置访问间隔,会被反爬虫机制识别出来。
并且这里没有伪装成访问头,那么python访问头就会默认会告诉访问对象自己是python爬虫
有些网站需要验证码,有的网站需要登陆,有的网站需要headers信息才能正常访问。海外链接需要翻墙也可能导致意外中止。
你也需要把获得的数据不仅仅是输出到控制台,你也许想输出到txt或者csv文件中
上述代码还可以写成
soup.find_all(“span”,{“class”:“read-count”})
find_all还可以写成findAll,find_all更符合python语法习惯
获取文字类比上面即可,不再赘述,没学会95%是因为你html知识的问题
大多数人是因为不会分析html页面才不知道自己该怎么取得想要的信息
而不是python知识的问题
2.获取图片
延续上面的代码添加内容
$是正则表达式,可以参见我的另一篇文章,也可以你自行搜索
https://blog.csdn.net/qq_36376711/article/details/86505332
import re#一个字符串处理的包
#获取图片的链接,"img表示选取所有img标签对"".jpg$表示获取标签对中
#所有以.jpg结尾的内容"
links = soup.find_all('img',"",src=re.compile(r'.jpg$'))
#打印出所有链接中src属性的内容
print(links.attsr["src"])
获取图片
import time#时间相关的包
# 设置保存图片的路径,否则会保存到程序当前路径
#要求path必须存在,所以测试时发现bug多半是因为你没有创建该文件夹
#修改path的值或者自己去E盘创建该文件夹,那些不阅读代码光复制粘贴运行的估计会认为是教学有问题
path = r'E:\pystest\images'
#路径前的r是保持字符串原始值的意思,就是说不对其中的符号进行转义
for link in links:
#打印出所有链接中src属性的内容
print("正在下载:",link.attrs['src'])
#保存链接并命名,time.time()返回当前时间戳防止命名冲突
request.urlretrieve(link.attrs['src'],path+'\%s.jpg' % time.time())
#使用request.urlretrieve直接将所有远程链接数据下载到本地
结果:

3.完整代码
完善代码并增加稳定性
from urllib import request
from bs4 import BeautifulSoup
import re
import time
#导入chardet 用于检测编码
import chardet
def get_html_content(url):
try:
'''
urlopen 返回对象可以使用
1.geturl:返回请求对象的url
2.info:对象的meta信息,包含http返回的头信息
3.getcode:返回的http code
例如print("URL:{0}".format(page.getcode()))
'''
xhtml = request.urlopen(url).read()
#将bytes内容解码,转换为字符串
#html源码里面一般有编码格式
#利用chardet检测编码
charset = chardet.detect(xhtml)
except Exception as e:
print(e)
#urlopen可能出现httperror,如404等
return None
try:
#如果找到encoding,返回其值,设置没有找到时默认为utf-8
#使用get取值防止出错
html = xhtml.decode(charset.get("encoding","utf-8"))
except AttributeError as e:
print(e)
return None
soup = BeautifulSoup(html,"html.parser")
return soup
url = "https://blog.csdn.net/qq_36376711/article/details/85712738"
soup = get_html_content(url)
#如果获得的内容为空则直接退出
if soup is None:
exit(0)
print("文章:",soup.h1.get_text())
count = soup.find_all("span","read-count")
for c in count:
print("阅读量:",c.get_text())
links = soup.find_all('img',"",src=re.compile(r'.jpg$'))
path = r'E:\pystest\images'
print("以下图片将存储在:",path)
for link in links:
print("正在下载:",link.attrs['src'])
#建一个空的readme防止路径不存在错误
#直接创建文件夹更好,参考下面文章,为了代码简短所以我没用
#https://www.cnblogs.com/monsteryang/p/6574550.html
with open(r"E:\pystest\images\readme.txt","w") as file:
#pass表什么都不做
pass
request.urlretrieve(link.attrs['src'],path+'\%s.jpg' % time.time())
关于如何通过循环采集不同网页信息和应付反爬,验证码,利用scarpy或requests库爬虫等。以后有空我会另外写文章再在此补充链接,或者找较好教程的链接。
本博客为原创,根据作者在网易云课堂,实验楼和《python网络数据采集》一书中所学知识综合所写。
你可以随意修改和发布此博文,甚至你可以说是你自己写的。
如何查看html页面和http连接信息:https://blog.csdn.net/qq_36376711/article/details/86679266
更详细分析:wireshark抓包工具
后续细节补充部分:https://blog.csdn.net/qq_36376711/article/details/86675208