这次介绍urllib库和BeautifulSoup的一些细节用法
只讲如何用和数据处理,如果有些函数不明白什么作用,或者想知道Exception处理请参照前一篇文章:https://blog.csdn.net/qq_36376711/article/details/86614578
urllib为python3自带库,bs4需要cmd下 pip install bs4.如果没有成功基本是你环境变量设置问题或者pip的问题
request部分:
request访问方法一:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
url可以是字符串或request对象,一般是HTTP/HTTPS链接地址
data一般不用管,目前只有HTTP/HTTPS用到data
timeout指定连接超时时间,只对HTTP,HTTPS,FTP连接生效
可选的cafile和capath参数为HTTPS请求指定一组可信CA证书。
cadefault不用管
context是描述各种SSL选项的ssl.SSLContext实例
from urllib import request
url = "https://docs.python.org/3.7/library/urllib.html"
#urlopen是request库中最简单的访问方法
content = request.urlopen(url)
#显示你访问的url地址
print(content.geturl())
#以email.message_from_string()实例的形式返回页面的元信息,例如标题
#参考:https://docs.python.org/3.7/library/email.parser.html#email.message_from_string
print(content.info())
#html访问成功则返回200
print(content.getcode())
html = content.read().decode("utf-8")
HTTP或HTTPS访问成功会返回一个http.client.HTTPResponse 对象
失败返回exception http.client.HTTPException的一种子类
urllib.request.urlopen() 对应旧版本中的 urllib2.urlopen
request访问方法二:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
这是url request的抽象类
url2 = "https://www.csdn.net/"
#构造头数据,伪装成正常浏览器访问
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
content2 = request.Request(url=url2, headers=headers)
html2 = content2.read().decode("utf-8")
浏览器中按F12或者右键,审查元素,找到network,进行一些操作,以访问谷歌翻译时输入一些需要翻译的文字为例,输入后,发现产生数据交换,随便点击其中一项,找到Request Headers。实际用到哪些headers参数需要你自己去查看你想爬去的网站,具体情况具体分析。有些不必要的参数也可以不用填进去,这个需要耐心的尝试。
如果光看文字看不懂,请看图文说明:
https://blog.csdn.net/qq_36376711/article/details/86679266

urllib文档给的部分例子
with urllib.request.urlopen('http://www.python.org/') as f:
print(f.read(300))
beautifulsoup部分:
bs4:从HTML或XML文件中提取数据的Python库
中文文档:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
和bs4类似的模块有html.parser(python自带的)和lxml
from urllib import request
from bs4 import BeautifulSoup
url = "https://blog.csdn.net/qq_36376711/article/details/86675208"
html = request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(html,'html.parser')
html.parser参数用于指定解析器

#也可以直接通过本地html文档或者传入一个字符串(符合html语法的字段)直接构建bs对象
soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("<html>data</html>")
上述方法会将文档转换成Unicode,并且HTML的实例都被转换成Unicode编码
#获取所有文字部分
print(soup.get_text())
#格式化输出获取到的soup
print(soup.prettify())
#通过标签访问标题,因为标题的字体是h1标签内的内容
#soup.h1包含标签,soup.h1.get_text()不含标签
print(soup.h1.get_text())
#方式不同,但和上一句结果相同
print(soup.h1.string)
找到标题标签:
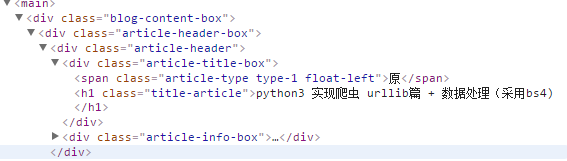
soup.h1:

soup.h1.get_text():

find_all( name , attrs , recursive , text , **kwargs )
find( name , attrs , recursive , text , **kwargs )
name是指标签名称(html,span,div,p,h1等),attr指标签属性值/class(类别),recursive指定是否递归查找,默认为True
#利用soup.h1输出,会发现,h1类标签(不懂的话你就理解成字体最大的)明明不止标题,所以可以看出
#soup.h1找到第一个符合条件的值就会停止搜索,所以我们采用find_all()来找出所有满足条件的
#findAll()与find_all()都可用
text_h1 = soup.find_all("h1")
for text in text_h1:
print(text.get_text())
#通过属性值,如class查找,上面的h1是通过标签查找
#有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性:
print(soup.find_all("title")[0].get_text())
#通过id查找,id=True表示查找所有具有id属性的标签
print(soup.find_all(id="article_content"))
#soup.find_all(“a”)和soup(“a”)等价
#find也是找到第一个满足条件的就会停止
print(soup.find(h1).get_text())
text参数简单说明不方便理解,直接上bs的中文文档

#也可以通过string访问其值
print(soup.h1.string)#前面也提到过
#访问标签名
print(soup.h1.name)
#访问标签的父节点(上级标签)#同理可访问兄弟节点和子节点
print(soup.h1.parrent)
#可以直接修改soup的属性:tag[attribute] = "value",如
h1[class] = "title"
#应用场景:批量修改部分标签属性等
#通过标签加类别
print("文章阅读数:",soup.find_all("span","read-count")[0].get_text())
#找出所有的h1-h6标签
h_list = soup.find_all({"h1","h2","h3","h4","h5","h6"})
#由于find_all返回的是个列表,所以用循环打印输出,不能直接用.get_text()
#或者像获取文章阅读数一样用 [0]去获取
for h in h_list:
print(h.get_text())
下面两句完全等价,class为python保留字,所以用class_
soup.find_all(class_ = "recommend-right")
soup.find_all("",{"class":"recommend-right"})
#利用html节点的contents属性获取数据,当该节点没有子节点时会报错
for content in soup.head.contents:
#content没有string属性和get_text()方法
print(content)
#子节点访问
for child in soup.head.children:
print(child)
True 匹配所有tag,但不会返回字符串节点,用于方便的查看该html页面有哪些字段
for tag in soup.find_all(True):
print(tag.name)
还可以结合re库利用正则表达式匹配查找数据,前一篇文章有所讲解,此处不再赘述。
此外还有其它搜索函数可用,以及根据css搜索
如:
find_parents( name , attrs , recursive , text , **kwargs )
find_parent( name , attrs , recursive , text , **kwargs )
find_all_next( name , attrs , recursive , text , **kwargs )
find_next( name , attrs , recursive , text , **kwargs )
……
文章结果稍微有点混乱,以后重构(滑稽)
本博客为原创,根据作者在《python网络数据采集》一书和官方文档中所学知识综合所写。
你可以随意修改和发布此博文,甚至你可以说是你自己写的。
下一篇文章预定讲解如何大量抓取页面信息及应对简单的反爬虫机制。