一、是什么?
首先,给大家讲一个例子,最近天气变的越来越冷了,那么北京、上海的天气也一样渐渐变冷了。但是我问大家阿根廷的天气怎么样,大家肯定可以根据常识想一下,哎,我们是北半球,天气在变冷,阿根廷是南半球,应该还比我们这边的天气好一点。大家刚刚根据地理常识进行对比思考的过程,也就是我今天要讲的主题:迁移学习。
机器学习解决的是让机器自主地从数据中获取知识,从而应用于我们研究的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
传统机器学习通常有两个基本假设,即训练样本与测试样本满足独立同分布的假设和必须有足够可利用的训练样本假设。

表:传统机器学习与迁移学习的区别
1,概念:
迁移学习是指利用数据、任务、或者模型的相似性,将在旧领域学习到的模型,应用到新的领域的一种学习过程。
通俗的讲就是把已经学习训练好的模型参数迁移到新的模型进行训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率,不用像大多数网络那样从零学习。
迁移学习的核心问题是,找到两个领域的相似性。找到了这个相似性,就可以合理地利用,从而很好地完成迁移学习任务。
2.分类
机器学习主要可以分为有监督、半监督和无监督 机器学习三大类。。同理,迁移学习也可以进行这样的分类。

(1)基于实例(样本)的迁移,简单来说就是通过权重重用,对源域和目标域的样例进行迁移。就是 说直接对不同的样本赋予不同权重,比如说相似的样本,我就给它高权重,这样我就完成了迁移。
(2)基于特征的迁移,就是更进一步对特征进行变换。意思是说,假设源域和目标域的特征 原来不在一个空间,或者说它们在原来那个空间上不相似,那我们就想办法把它们变换到一 个空间里面,那这些特征不就相似了?
(3)基于模型的迁移,就是说构建参数共享的模型。这个主要就是在神经网络里面用的特 别多,因为神经网络的结构可以直接进行迁移。比如说神经网络最经典的 finetune (微调)就是模型参数迁移的很好的体现。
(4)基于关系的迁移,这个方法用的比较少,这个主要就是说挖掘和利用关系进行类比迁 移。比如老师上课、学生听课就可以类比为公司开会的场景。这个就是一种关系的迁移。
以上四种方法会在后面做进一步的介绍。
3.迁移学习的方法:
3.1 样本迁移(Instance based TL)
在源域中找到与目标域相似的数据,把这个数据的权值进行调整,使得新的数据与目标域的数据进行匹配。下图的例子就是找到源域的例子3,然后加重该样本的权值,使得在预测目标域时的比重加大。优点是方法简单,实现容易。缺点在于权重的选择与相似度的度量依赖经验,且源域与目标域的数据分布往往不同。

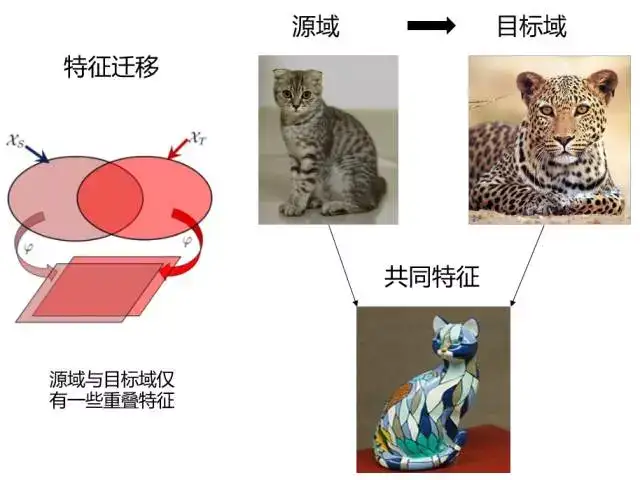
3.2 特征迁移(Feature based TL)
假设源域和目标域含有一些共同的交叉特征,通过特征变换,将源域和目标域的特征变换到相同空间,使得该空间中源域数据与目标域数据具有相同分布的数据分布,然后进行传统的机器学习。优点是对大多数方法适用,效果较好。缺点在于难于求解,容易发生过适配。
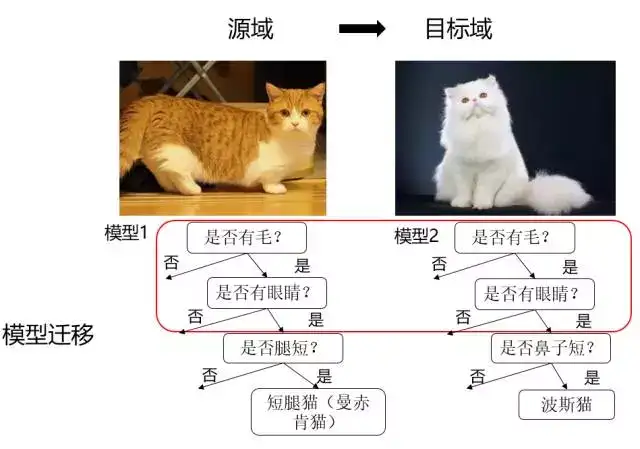
3.3 模型迁移(Parameter based TL) (调参)
假设源域和目标域共享模型参数,是指将之前在源域中通过大量数据训练好的模型应用到目标域上进行预测,比如利用上千万的图象来训练好一个图象识别的系统,当我们遇到一个新的图象领域问题的时候,就不用再去找几千万个图象来训练了,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需几万张图片就够,同样可以得到很高的精度。优点是可以充分利用模型之间存在的相似性。缺点在于模型参数不易收敛。
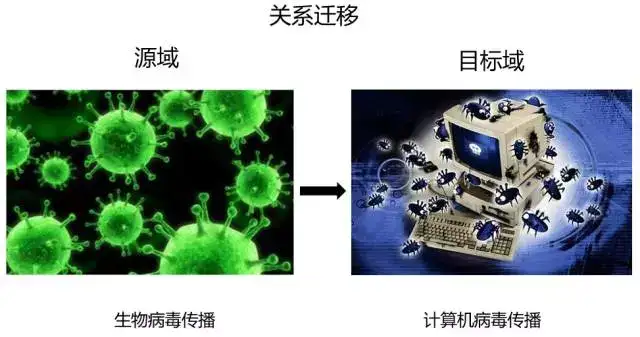
3.4 关系迁移(Relation based TL)
假设两个域是相似的,那么它们之间会共享某种相似关系,将源域中逻辑网络关系应用到目标域上来进行迁移,比方说生物病毒传播到计算机病毒传播的迁移。
二、为什么?
1.引入迁移学习的原因
迁移学习的目的的是什么?或者为什么要用迁移学习呢?主要有四点:
(1),大数据和少标签之间的矛盾。
目前我们正处于大数据时代,每天都可以产生海量的数据,数据的增多,使得机器学习和深度学习可以依赖更加海量的数据持续不断的更新模型,使得模型的性能越来越好,越来越适合特定场景的应用。然而,这些大数据带来了严重的问题:总是缺乏完善的数据标注。
(2). 大数据与弱计算之间的矛盾。
大数据,就需要大设备、强计算能力的设备来进行存储和计算。绝大多数普通用户是不可能具有这些强计算能力的。这就引发了大数据和弱计算之间 的矛盾。
(3) 普适化模型与个性化需求之间的矛盾。
机器学习的目标是构建一个尽可能通用的模型,使得这个模型对于不同用户、不同设 备、不同环境、不同需求,都可以很好地进行满足。我们要尽可能的替考机器学习模型的泛化能力,使之能够适应不同的数据情形。
我们对于每一个通用的任务都构建了一个通用的模型。这个模型可 以解决绝大多数的公共问题。但是具体到每个个体、每个需求,都存在其唯一性和特异性, 一个普适化的通用模型根本无法满足。那么,能否将这个通用的模型加以改造和适配,使其 更好地服务于人们的个性化需求?
(4) 特定应用的需求。
比如推荐系统的冷启动问题。一个新的推荐系统,没有足够 的用户数据,如何进行精准的推荐?
上述存在的几个重要问题,使得传统的机器学习方法疲于应对。迁移学习则可以很好地进行解决:
1. 大数据与少标注:迁移数据标注
利用迁移学习的思想,我们可以寻找一些与目标数据相近的有标注的数据,从而利用这 些数据来构建模型,增加我们目标数据的标注。
2. 大数据与弱计算:模型迁移
利用迁移学习的思想,我们 可以将训练好的模型,迁移到我们的任务中。针对于我们的任务进 行微调,从而我们也可以拥有在大数据上训练好的模型。更进一步,我们可以将这些模型针 对我们的任务进行自适应更新,从而取得更好的效果。
3. 普适化模型与个性化需求:自适应学习
我们利用迁移学习的思想,进行自适应的学习。考虑到不 同用户之间的相似性和差异性,我们对普适化模型进行灵活的调整,以便完成我们的任务。
4. 特定应用的需求:相似领域知识迁移
可以利用上述介绍过的手段,从数据和模型方法上 进行迁移学习。

传统机器学习通常有两个基本假设,即训练样本与测试样本满足独立同分布的假设和必须有足够可利用的训练样本假设。迁移学习用已有的知识来解决目标领域中仅有少量有标签样本数据甚至没有数据的学习问题,从根本上放宽了传统机器学习的基本假设。由于被赋予了人类特有的举一反三的智慧,迁移学习能够将适用于大数据的模型迁移到小数据上,发现问题的共性,从而将通用的模型迁移到个性化的数据上,实现个性化迁移。
那么是不是只要利用迁移学习就都能取得很好的效果呢?那是不可能的。这就引入了迁移学习中的一个负面现象,也就是所 谓的负迁移。
2, 负迁移
如果说成功的迁移学习是“举一反三”、“照猫画虎”,那么 负迁移则是“东施效颦”。
我们之前也介绍了什么是迁移学习,。迁移学习指的是,利用数据和领域之间存 在的相似性关系,把之前学习到的知识,应用于新的未知领域。如果这个相似性找的不合理,也就是说,两个领域之间不存在相似性,或者基本 不相似,那么,就会大大损害迁移学习的效果。拿骑自行车来说,你要拿骑自行车的经 验来学习开汽车,,这显然是不太可能的。因为自行车和汽车之间基本不存在什么相似性。所 以,这个任务基本上完不成。这时候,我们可以说出现了负迁移 (Negative Transfer)。
负迁移指的是,在源域上学习到的知识,对于目标域上的学习产生负面作用。
所以,产生负迁移的原因主要有:
• 数据问题:源域和目标域压根不相似,谈何迁移?
• 方法问题:源域和目标域是相似的,但是,迁移学习方法不够好,没找到可迁移的成 分。
如何克服负迁移呢?
最新的研究成果
随着研究的深入,已经有新的研究成果在逐渐克服负迁移的影响。
(1)、杨强教授团队2015在 数据挖掘领域顶级会议KDD上发表了传递迁移学习文章Transitivetransferlearning[Tan et al., 2015], 提出了传递迁移学习的思想。传统迁移学习就好比是踩着一块石头过河,传递迁移学习就 好比是踩着连续的两块石头。

传递式迁移学习示意图
(2)杨强教授团队在 2017 年人工智能领域顶级会议 AAAI 上发表了远领域迁 移学习的文章 Distant domain transfer learning [Tan et al., 2017],可以用人脸来识别飞机! 这就好比是踩着一连串石头过河。
三、怎么办?
1.应用
迁移学习在很多的领域的都可以发挥很重要的作用。比如计算机视觉、文本分析、行为识别、自然语言处理、室内定位、视频监控、人机交互等方面都发挥着重要的作用。
- 推荐系统
迁移学习也可以用在推荐系统中,在某个领域做好一个推荐系统,然后应用在稀疏的、新的垂直领域。比如已成熟完善的电影推荐系统可以应用在冷启动中的书籍推荐系统中。

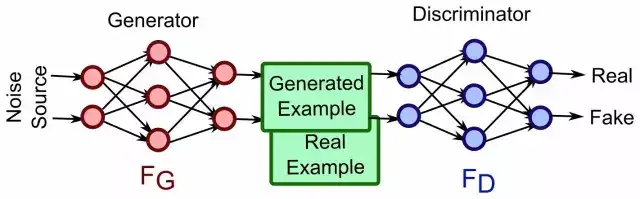
- 数据生成式的迁移学习-GAN
生成式对抗网络(GAN)是一个新的机器学习的思想。GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型G捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声z生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D输出大概率,否则,D输出小概率。GAN的优化是一个极小极大博弈问题,最终的目的是generator的输出给discriminator时很难判断是真实or伪造的。
如果我们有一个很好的生成式模型,在某个数据集上已经训练好了,如果有一些新的数据,和前一个数据集有明显的区别,那么我们可以利用“GAN+边界条件”,把生成式模型迁移到新的数据分布上。比方说,我们写字的时候,每个人签名都是不同的,我们不会用印刷体来签名,因为我们每个人都有自己的写字的特点。那么,如果用大量的印刷体字作为第一部分的训练样本,来训练一个不错的通用模型,而用某个人手写的斜体字做第二部分的训练样本,就可以利用Wasserstein GAN把印刷体的模型迁移到个人的签名。也就是说,这样的签名也就更具个性化特点。
补充:
Wasserstein GAN(下面简称WGAN)成功地做到了以下爆炸性的几点:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
- 基本解决了collapse mode的问题,确保了生成样本的多样性
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高。
- 以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
(补充结束)