1 总览
迁移学习的目标,是利用一些不相关的数据,来提升目标任务。不相关主要包括
- task不相关。比如一个为猫狗分类器,一个为老虎狮子分类器
- data不相关。比如都为猫狗分类器,但一个来自真实的猫和狗照片,另一个为卡通的猫和狗
迁移学习中包括两部分数据
- source data。和目标任务不直接相关,labeled或unlabeled数据一般比较容易获取,数据量很大。可以利用一些公开数据集,比如ImageNet。又比如在机器翻译任务中,中译英数据量很大,可以作为source data
- target data。目标任务直接相关的数据,labeled或者unlabeled数据一般比较少。比如机器翻译任务中,中文翻译葡萄牙语,相对来说要少一些。
根据source data和target data,是否包含labeled data,我们又可以分为四类
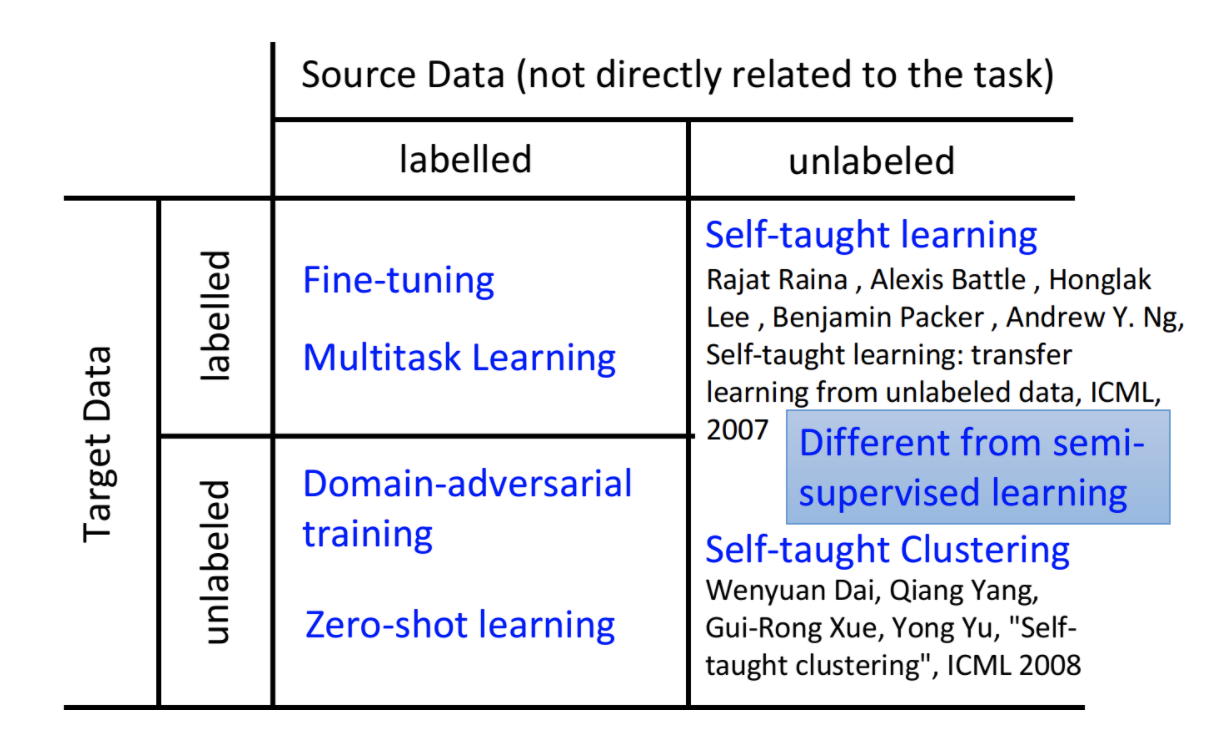
下面就一一介绍这四类case,和他们的处理方法
2 source和target都有标签
此时通常情况是,二者都有标签,但source data数据量比较大,而target data数据量比较少。假如target data数据量本身就比较大,那我们直接利用target data来训练模型就好了,不需要使用source data。此时常用两种方法
- 在source data上pretrain,然后在target data上fine-tune
- source和target两个任务结合起来,做multi-task learning(MTL)
2.1 fine-tune
fine-tune模型微调的思想是,在source data上训练模型,然后在target data上进行微调。从而既可以从source data中学到大量知识,又可以适应target data特定任务。先用source data训练模型,然后利用这个模型参数初始化,然后在target data上继续训练下去。当target data特别少时,需要防止fine-tune 过拟合。
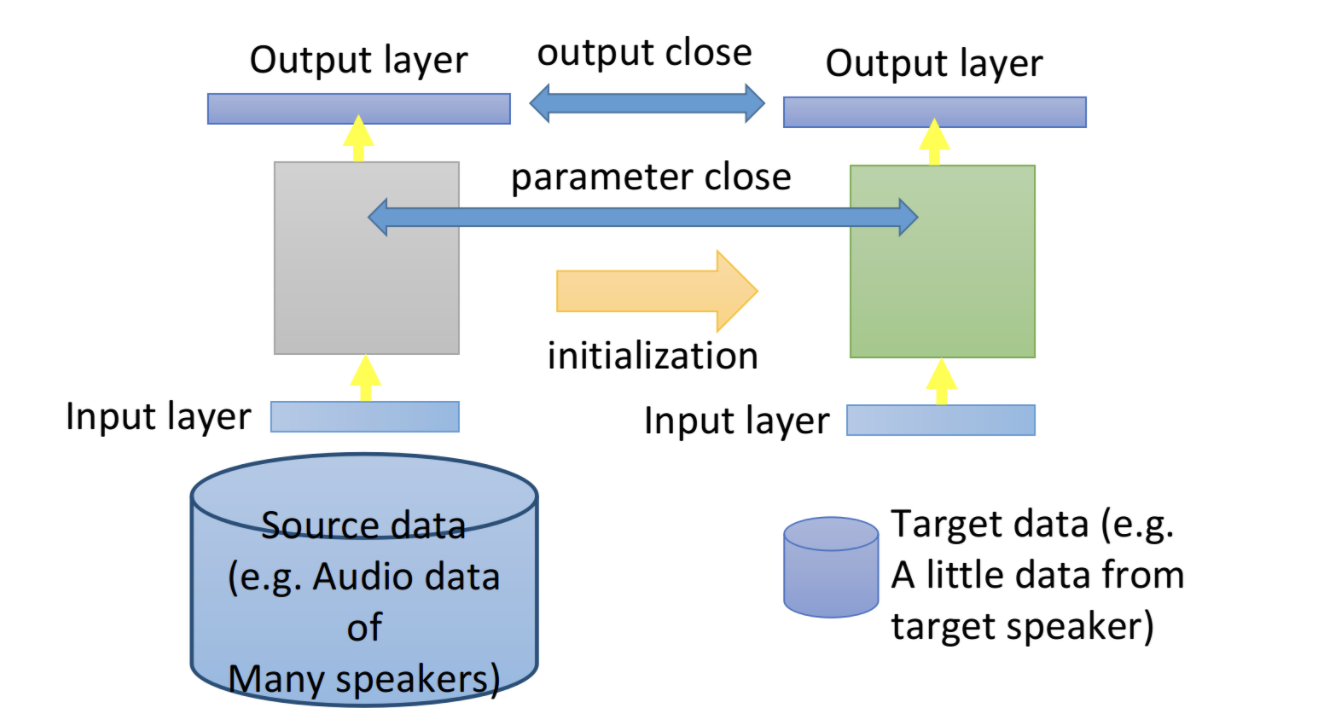
layer transfer
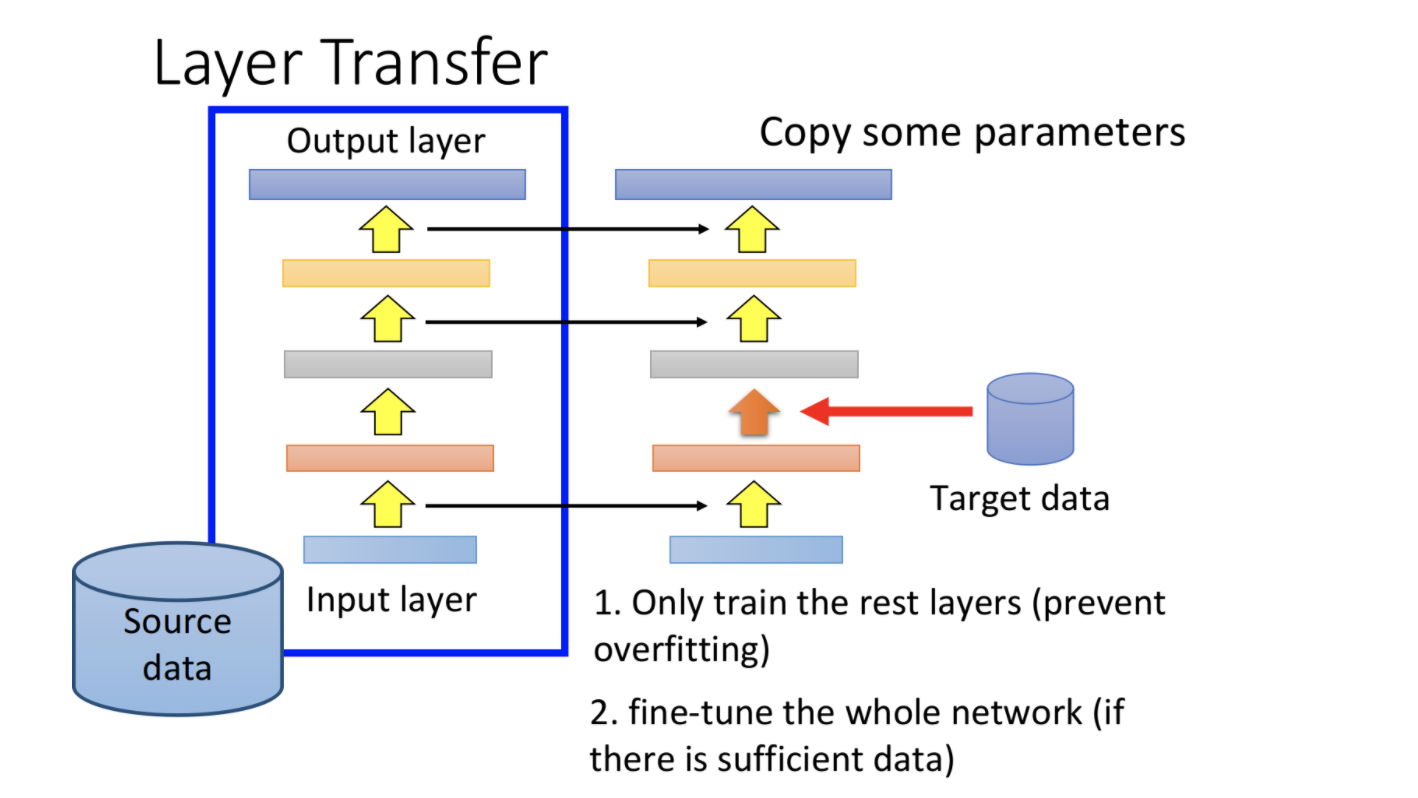
当target data特别少时,fine-tune也有可能过拟合。此时可以使用layer transfer。
- 先利用source data训练一个模型
- 然后将模型的某些layer直接copy到target模型上。
- 再利用target data来训练target模型的剩余layer,之前copy过来的layer可以freeze住
此时只需要训练模型的少数几层,就没那么容易出现过拟合了。
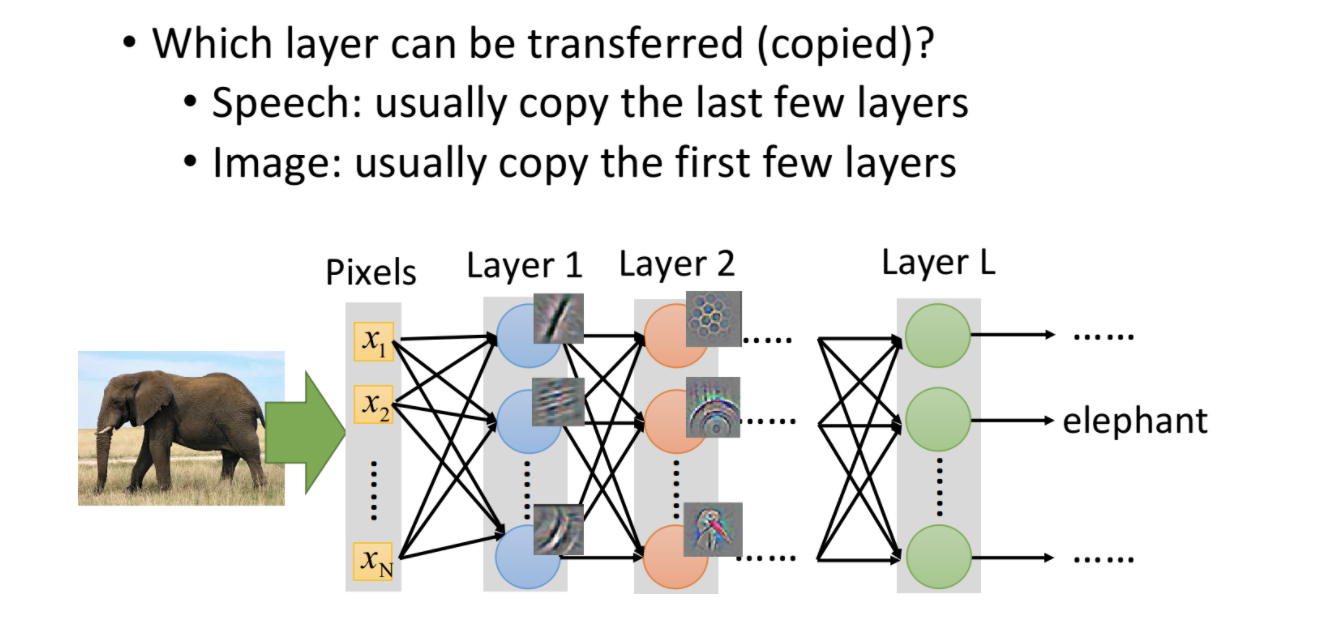
那么现在的问题就是,哪些layer需要被直接copy,而哪些则需要做fine-tune呢。这需要根据不同的任务来
- 语音识别中,一般直接copy最后几层,而fine-tune前面几层。这是因为不同人发音,由于口腔结构不同,低阶特征差别比较大,而语义和语言模型等高阶特征则相差不多。
- 图像任务中,一般直接copy前面几层,而fine-tune后面几层。这是因为图像中的光照、阴影等低阶特征一般差别不大,而高阶特征(比如大象的鼻子)则不同类别差别很大。
2.2 multi-task learning 多任务学习
fine-tune只需要考虑模型在target data上的效果,而多任务学习则需要模型在source和target上表现都要比较好。
- 如果source和target输入特征比较相似,则可以共享前几层layer,后几层再在不同任务上单独处理。
- 如果source和target输入特征不同,则前几层layer和最后几层layer都可以使单独的,而共享中间几层layer。
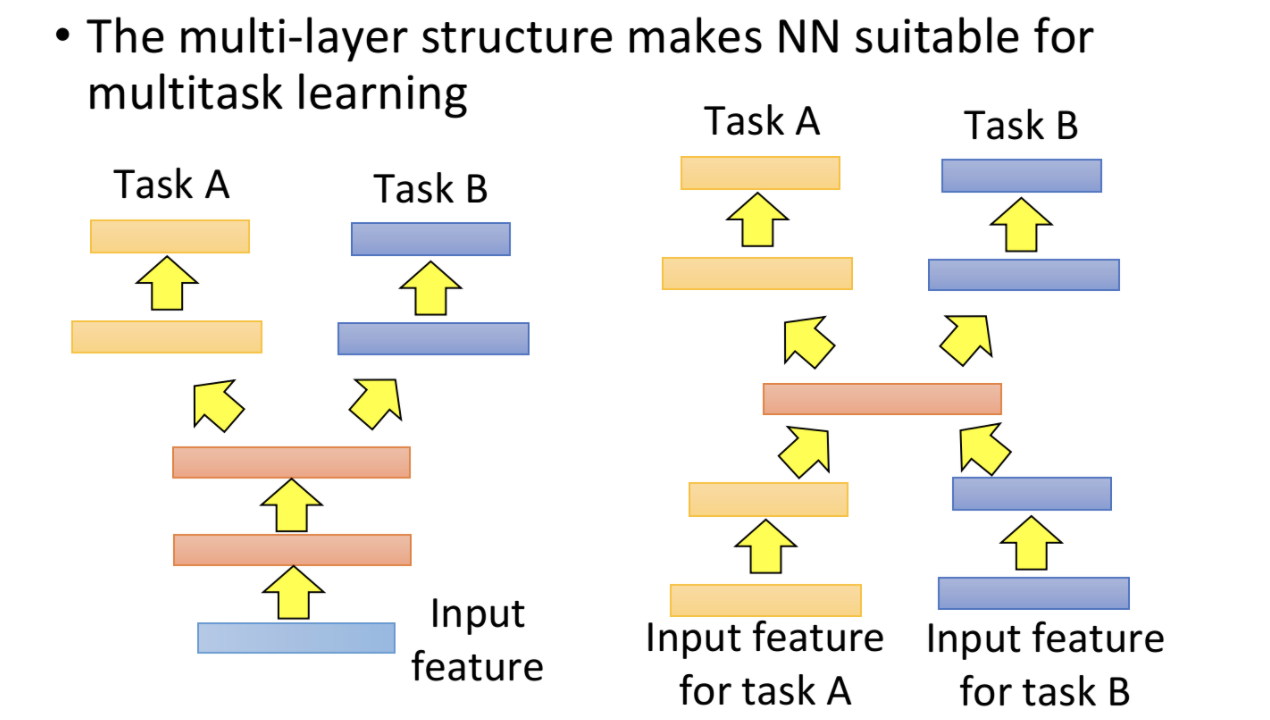
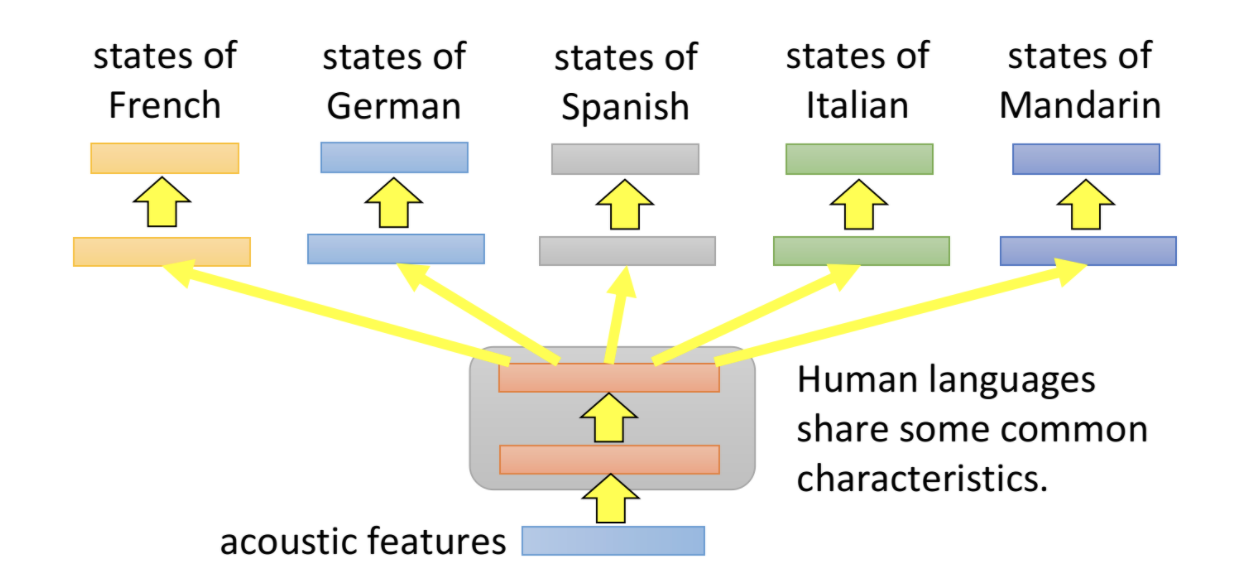
下面是机器翻译上的多任务学习的例子
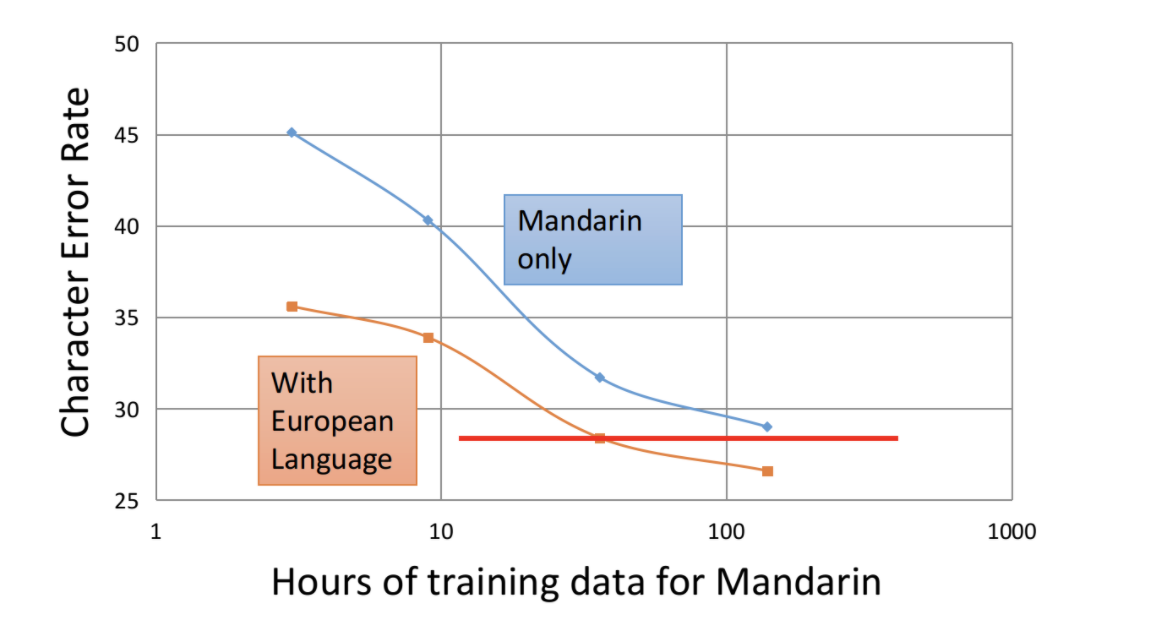
下图则证明了使用多任务学习,可以在相同数据量情况下,大大降低错误率。同时在数据量少一半的情况下,仍然可以达到单任务的效果。大大降低了模型对数据的依赖,同时提升了模型性能。
3 target没有标签,但source有标签
此时可以利用领域对抗迁移,和零样本学习
3.1 Domain-adversarial Training 领域对抗训练
神经网络中的前面几层,一般是做特征抽取的。而后面几层则实现对应的任务,比如分类。我们的目标是特征抽取器对不同domain数据不敏感,将domain特有的信息去除掉,而尽量保留共性信息。
比如黑白背景的手写字识别,和彩色背景的手写字识别。二者domain差别比较大,直接用source模型来predict target数据,效果很差。主要就是受背景色不同影响。我们需要特征抽取器对背景不敏感,能真正抓住数字这个共性信息。

那怎么做领域对抗训练呢,可以借鉴GAN的思想。如下图所示,整个网络包含三个部分
- 特征抽取器 feature extractor。它用来对不同domain数据提取特征
- 预测器 label predictor。它用来predict source data的label
- 领域分类器 domain classifier。它用来区分数据是来自source,还是target。
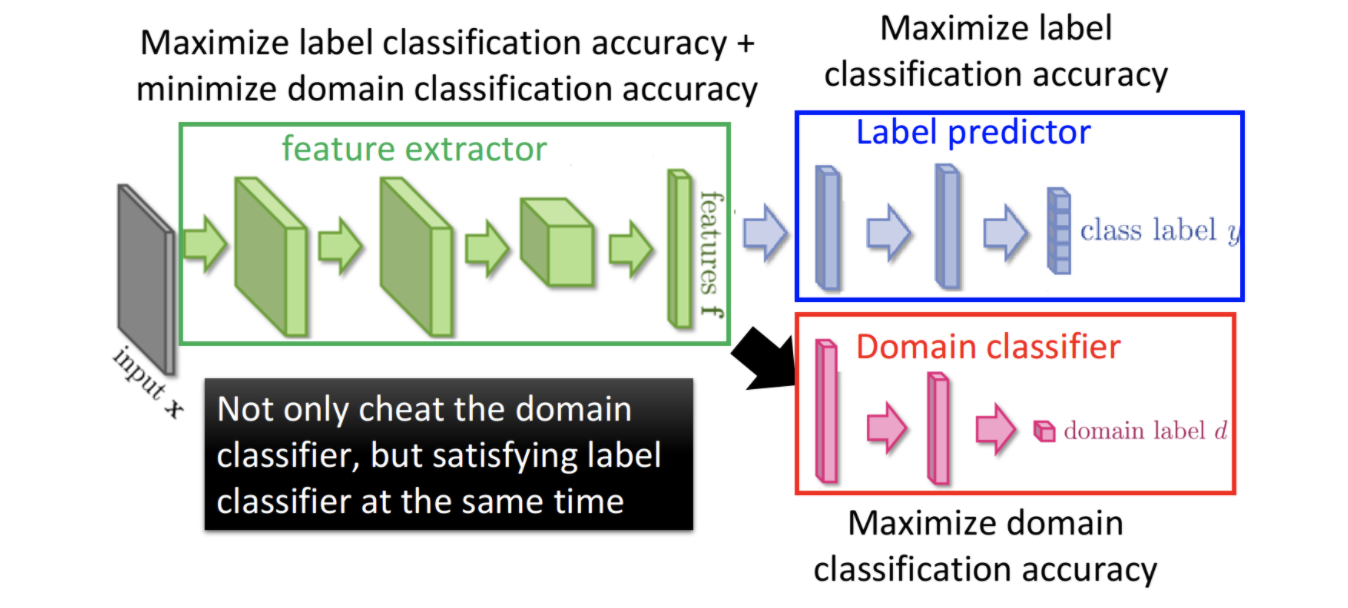
我们的目标有两个
- 最大化label predict的ACC,这样保证模型在实际任务上的效果不会差
- 最小化domain classifier的ACC,使得模型尽量不能区分数据来自哪个domain。从而保证特征抽取器对不同domain不敏感。不提取domain私有的特征,而尽量提取不同domain的共性特征。
3.2 zero-shot learning 零样本学习
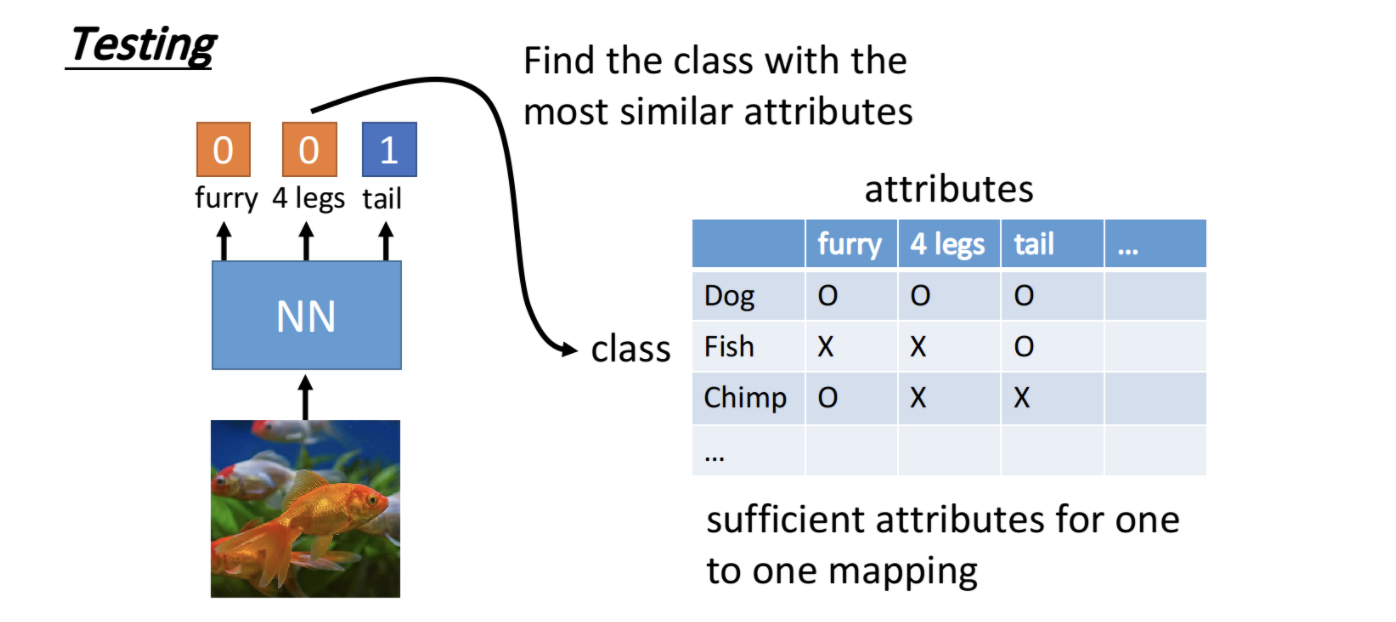
比如source是对猫狗进行分类,而target data中则出现了猴子。直接使用source模型显然是没法用的,因为连猴子这个label都是缺失的。此时我们可以使用zero-shot learning,不直接学习类别,而是类别的属性。比如我们可以创建一个table,属性为腿个数、有没有尾巴、有没有角,有没有毛等,而根据这些属性就可以确定类别为猫、狗、猴子。我们通过source来学习predict这些属性,然后利用属性查表来推测是哪个类别。
4 source没有label,target有label
此时可以参考半监督学习了,但和半监督还是有比较大差别。半监督中的数据,其domain差别不大。我们这儿的source和target,其domain有一定的差别。可以利用source数据量大的特点,构建自监督学习任务,来学习特征表达。典型例子为NLP中的各种预训练模型。利用自监督学习,构建Auto-Encoder,在source上训练pretrain model。然后在target任务上进行fine-tune。详见
机器学习10 -- 半监督学习 Semi-supervised Learning
5 source和target都没有label
此时主要就是聚类的范畴了,一般比较少碰到,就不说了。