
机器学习EM算法使用两个步骤交替计算,E步:利用当前估计的参数值来计算对数似然的期望值;M步:寻找能够使E步产生的似然期望最大化的参数值,然后用新得到的参数值重新进行E步计算,直到收敛。
EM算法的理解容易,公式推导较为复杂,本文从简单的实例入手逐步进行深入理解EM算法,对EM的相关知识进行梳理。
抛硬币实验:两枚硬币A和B,随机选择其中一枚硬币之后抛10次,重复5次。需要我们估计各自正面的概率。
下图a所示为知道选择的硬币是A或B,经过实验统计每个步骤的正反情况,最终得到A硬币是正面的概率是0.8,B硬币正面的概率是0.45

下图B所示,是在不清楚每次选择的是哪个硬币进行的实验,在这种情况下需要我们估计A和B硬币正面朝上的概率,就是知道一个样本数据,需要来估计未知参数θA和θB,而且样本过程中存在隐变量Z(不清楚每次选的是A硬币还是B硬币)

EM算法中首先根据需要预估的参数,进行初始化值,就是θA=0.6,θB=0.5。
E-step理解:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:


M-step理解:将似然函数最大化以获得新的参数值θA和θB
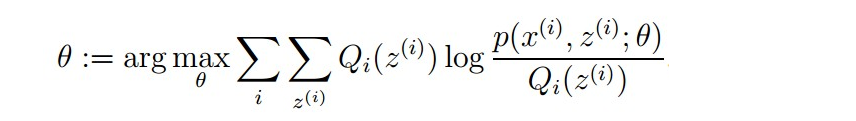
【数学基础】
1、Jensen不等式
凸函数:设f是定义域为实数的函数,如果对于所有的实数x,其二阶导大于等于0,则f是凸函数;当x是向量时,如果其hessian矩阵H是半正定的(H大于等于0),那么f是凸函数。
严格凸函数:如果只大于0,不等于0,则是严格凸函数。
性质一:如果函数f是凸函数,x是随机变量,那么E[f(x)]大于等于f(E(x));
性质二:如果f是严格凸函数,那么E[f(x)]=f(E(x))当且仅当P(x=E(X))=1,也就是说X是一个常量

图中,实线f是凸函数,X是随机变量,图中可以看到E[f(X)]>=f(E[X])成立。
2、期望公式的Lazy Statistician规则

【E步和M步】
EM算法是针对“最大似然函数估计”的一个延伸,运用EM算法的目的很明确:“确定概率模型p(x,z)中的参数θ”,与最大似然函数不同之处是似然函数中多了未知变量Z,EM算法的主体公式见下。

【参考文献】