奇异值分解,就是把矩阵分成多个“分力”。奇异值的大小,就是各个“分力”的大小。
之前在介绍矩阵特征值与特征向量的时候,也是以运动作为类比。
一、通俗理解奇异值
1、翻绳
对于翻绳的这个花型而言,是由四只手完成的:
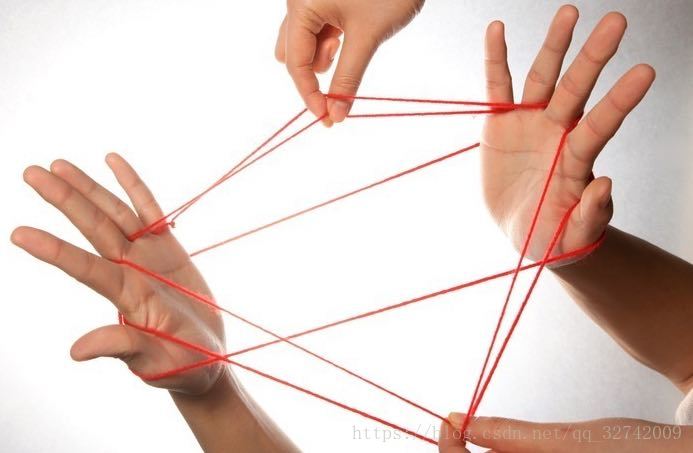
我们可以认为这个花型是由两个方向的力合成的:

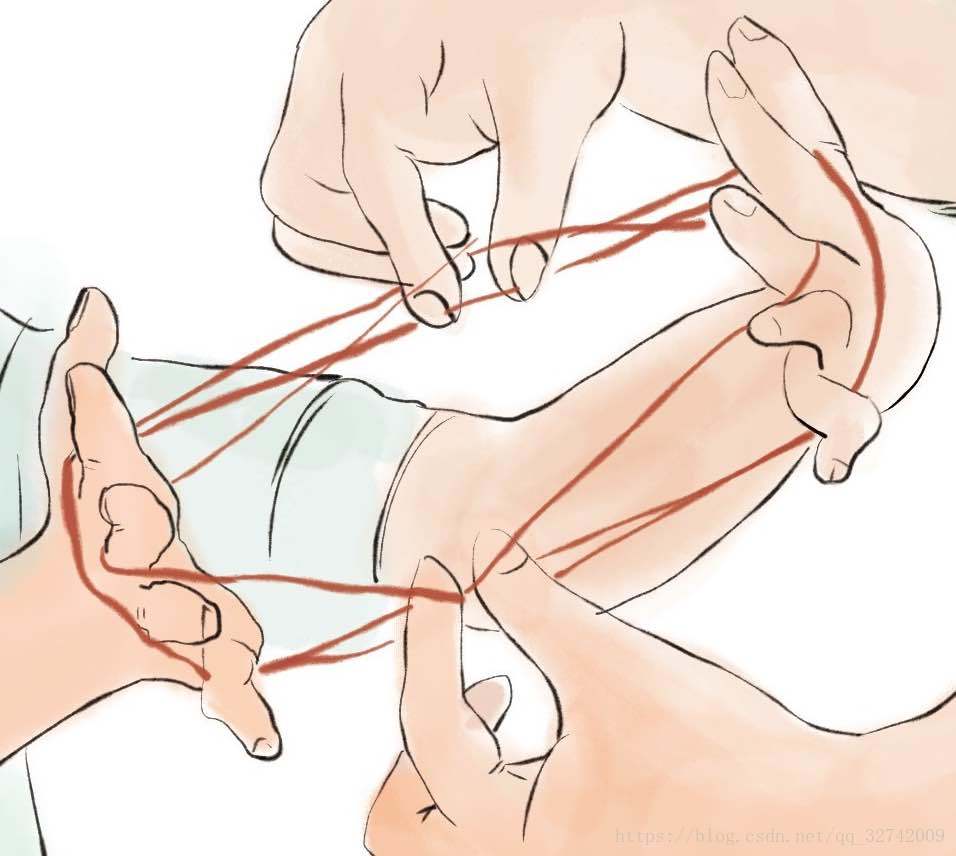
容易想象,如果其中一个力(相比另外一个力而言)比较小的话,那么绳子的形状基本上由大的那个力来决定:
2、奇异值分解与奇异值
类比于翻绳,我们可以认为:
-
奇异值分解,就是把矩阵分成多个“分力”。
-
奇异值的大小,就是各个“分力”的大小。
2.1 奇异值分解几何解释
下面通过一个具体的矩阵例子来解释下,比如:
根据之前的类比,矩阵是“力”,“力”怎么画出来呢?
翻绳游戏中的“力”要通过绳子的形状来观察。很显然要观察矩阵也需要一个载体。
我们通过单位圆来观察矩阵:
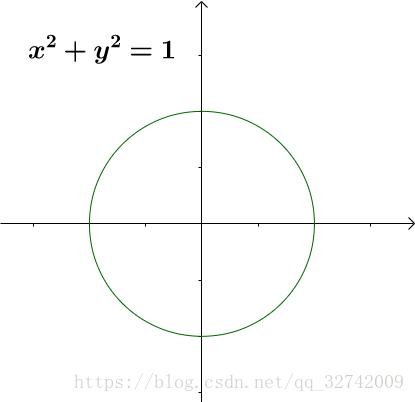
把这个单位圆的每一点都通过 进行变换,得到一个椭圆(我把单位圆保留下来了,作为一个比较):
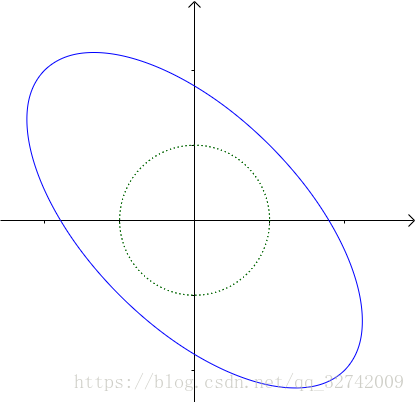
对 进行奇异值分解:
实际上,将 分为了两个“分力”:
我们来看看第一个“分力”:
作用在单位圆这个“橡皮筋”上的效果:
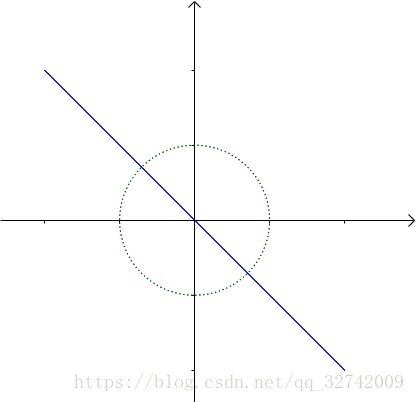
可怜的“橡皮筋”被拉成了一根线段。
我们来看看第二个“分力”:
作用在单位圆这个“橡皮筋”上的效果:
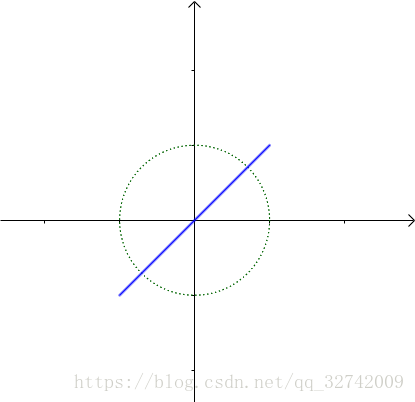
可怜的“橡皮筋”被拉成了另外一根线段。
这两个“分力”一起作用的时候,可以想象(画面自行脑补),单位圆这个“橡皮筋”被拉成了椭圆:
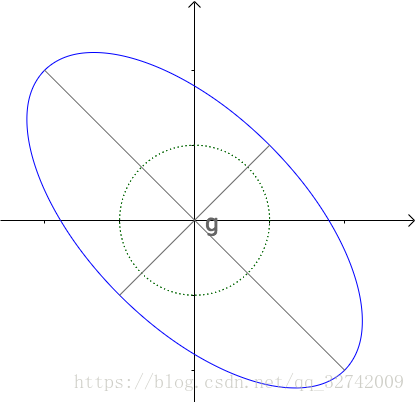
这里再用一幅图来概括:
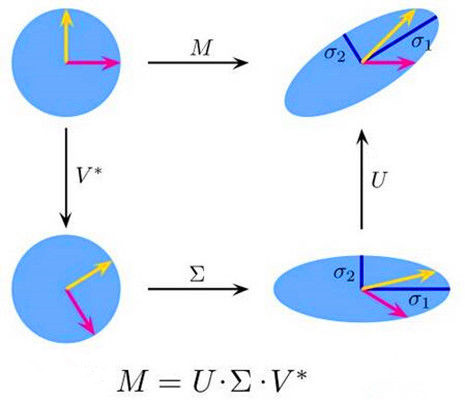
上面的几何解释其实已经比较清晰了,但正交这一点并没有很好的被体现出来。
以下继续重复解释一下,以加深印象。
以的矩阵为例,因为二阶矩阵可以使用平面在直角坐标系来表示。SVD在
矩阵上的作用的几何意义主要是可以将二维空间下两个互相正交(也就是垂直)的向量,通过矩阵分解,变换为另一个二维空间下互相正交的两个向量。具体的过程如下图所示。
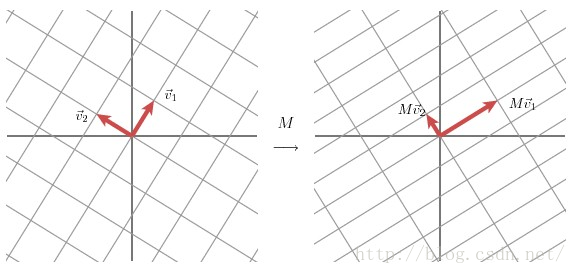
上图的含义是,我们在左图首先选定了两个单位正交基向量和
。那么此时,通过矩阵
的作用下,左图中的一个二维空间(左图正方形格子)下的正交向量
和
。就变换成为了另一个二维空间(右图长方形格子)下的正交向量
和
。然后我们在
和
的方向上分别选择两个单位向量
和
,同时设
和
的模长度为
和
,那么就有下式成立:
因此,对于上面左图中二维空间(正方形格子)的任意一个向量来说,就有:(“·”表示向量内积)
(3)式左右同时乘以矩阵:
(4)式结合(1)和(2):
将内积操作通过用转置表示出来:
两边同时消去X:
通常,我们将(7)式的形式写为:
从(8)式我们可以看到,矩阵是一个原始空间的正交矩阵,它的每一个列向量都是原始空间的规范正交基;而
矩阵则是变换之后的域的正交矩阵,它的每一个列向量都是变换空间的规范正交基。而式子中的奇异值对角矩阵
的值则对应了从原始空间(
)到变换空间(
)的对应关系,具体来说就是两个空间的基向量的拉伸程度。
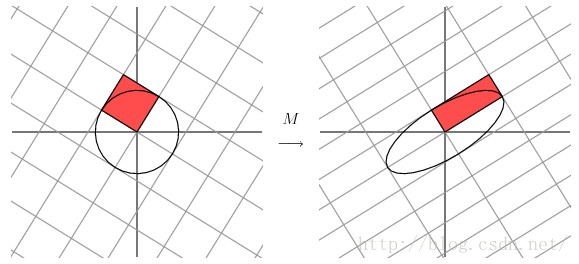
同时,还有另一种几何解释,与最开始讲的相同,也就是把SVD分解的过程看做是将单位圆的半径通过变换伸缩为椭圆的两个半轴。
如下图:
2.2 物理解释
个人理解,从信号的角度来讲,SVD过程的物理意义是将矩阵的能量集中到奇异值矩阵的左上角的过程。
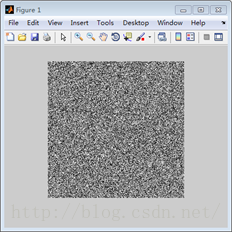
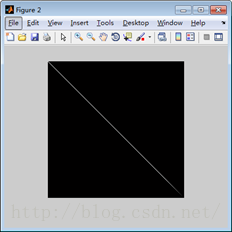
例如,上图中的左图为随机生成的一幅256x256的图像,值都是在0-255之间。右图为左图SVD分解之后的奇异值矩阵,颜色越亮,代表了值越大,也就是能量越大。因此SVD的过程就是通过变换,将原空间的能量重新聚集分配,在新的空间集中的过程,这就是SVD的物理意义。通过这个物理意义,我们可以做许多的应用,例如数据的压缩,图像的滤波,以及推荐算法等,这些会在后文说到。
2.3 奇异值的大小
刚才举的矩阵的两个“分力”大小,只相差一倍,如果相差很大会怎么样?
换一个矩阵 ,对它进行奇异值分解:
这两个“分力”的奇异值相差就很大,大概相差了40倍。
单位圆被 映射成了短轴和长轴相差太大的椭圆,看起来和直线差不多:
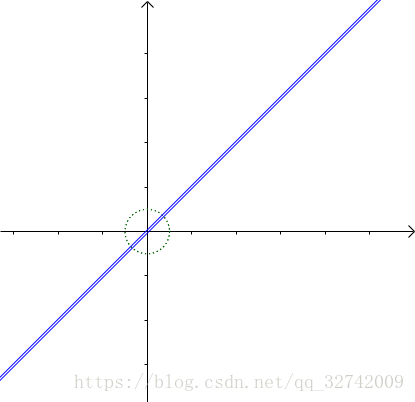
我们试试,把小的那个奇异值去掉会怎么样:
把单位圆变为了一根直线:
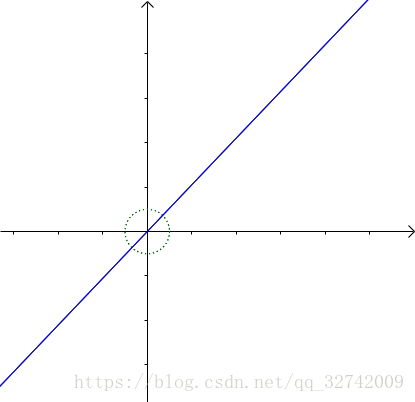
这个直线和之前的椭圆看上去差不多。
回到之前的比喻,两个相差很大的分力作用在“橡皮筋”上,“橡皮筋”的形状可以说完全取决于大的那个分力。
奇异值分解实际上把矩阵的变换分为了三部分:
-
旋转
-
拉伸
-
投影(当有奇异值为0时以及非方阵)
拿刚才的:
举例子(方阵没有投影,不过不影响这里思考):
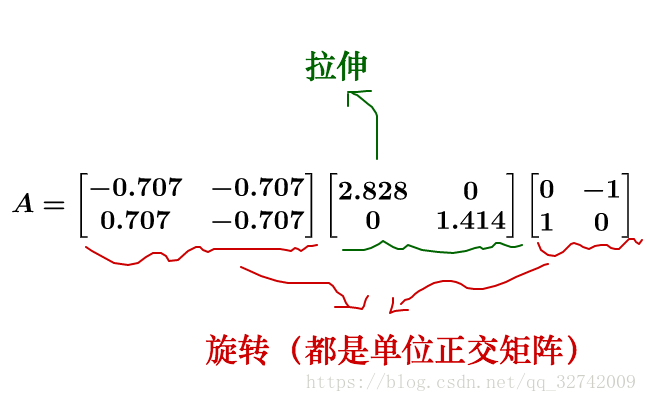
单位圆先被旋转,是没有形变的:

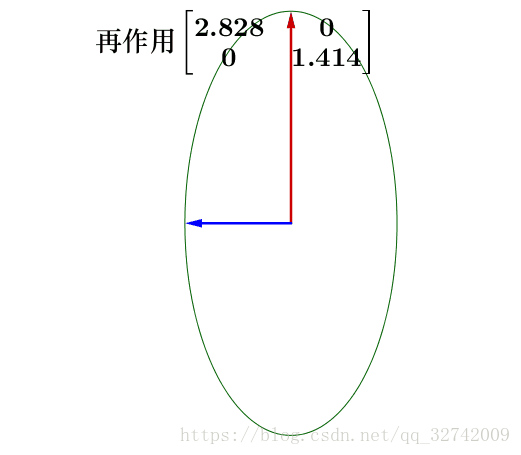
再进行拉伸,这里决定了单位圆的形状,奇异值分别是椭圆的长轴和短轴(奇异值如果为0,则相当于投影到某一个基向量上去):
最后,被旋转到最终的位置,这一过程也没有发生形变:
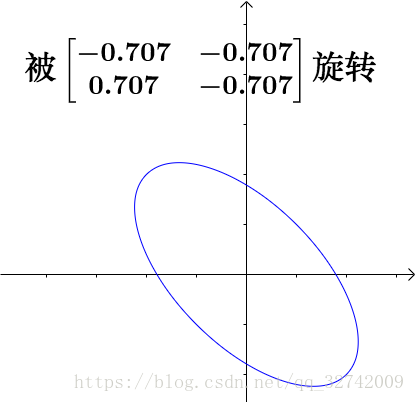
所以,奇异值决定了形变,大小决定在形变中的重要性。
二、奇异值与特征值、特征向量的联系与区别
前一小节介绍了奇异值在矩阵变换中发挥的作用,会发现这和我们讲方阵的特征值与特征向量时特别相似。那两者到底有什么区别呢?接下来就细细介绍一下。
1 奇异值
之前没有详细讲奇异值分解,这里先来谈谈奇异值分解在数学上的定义。
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有个学生,每个学生有
科成绩,这样形成的一个
的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
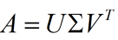
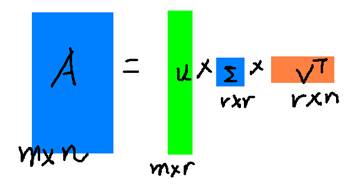
假设 是一个
的矩阵,那么得到的
是一个
的方阵(
中的向量是正交的,
里面的向量称为左奇异向量),
是一个
的矩阵(除了对角线之外的元素都是0,对角线上的元素称为奇异值),
(
的转置)是一个
的矩阵,里面的向量也是正交的,
里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片:
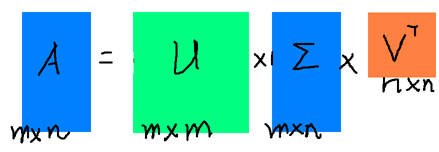
那么奇异值和特征值是怎么对应起来的呢?首先,我们计算得到,将会得到一个方阵,我们用这个方阵求特征值可以得到:
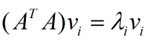
这里得到的,就是我们上面的右奇异向量。此外我们还可以得到:
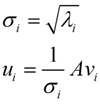
这里的就是上面说的奇异值,
就是上面说的左奇异向量。奇异值
跟特征值类似,在矩阵
中也是从大到小排列,而且
的减少特别的快,在很多情况下,前10%甚至1%奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前
大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:

是一个远小于
、
的数,这样矩阵的乘法看起来像是下面的样子:
右边的三个矩阵相乘的结果将会是一个接近于 的矩阵,在这儿,
越接近于
,则相乘的结果越接近于
。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵
,我们如果想要压缩空间来表示原矩阵
,我们存下这里的三个矩阵:
、
、
就好了。
2 奇异值与特征值有什么相似之处与区别之处
其实从之前奇异值的几何解释以及奇异值的数学定义都可以看出奇异值和特征值是两个相当接近的概念。奇异值的优点在于其不受限于原始矩阵是否是方阵这个约束。
矩阵可以认为是一种线性变换,如果将这种线性变换放在几何意义上,则它的作用效果和基的选择有关。(基是理解很多知识点的重中之重)。
以 为例,
是
维向量,
是
维向量,
可以相等也可以不相等,表示矩阵可以将一个向量线性变换到另一个向量,这样一个线性变换的作用可以包含旋转、缩放和投影三种类型的效应。
比如说:
其几何意义为在水平方向上拉伸3倍,
方向保持不变的线性变换,这就是缩放;而如果前面乘的矩阵不是对称矩阵,那么则对应几何意义上的缩放加旋转。 如果矩阵
不满秩,则在线性变换中即包含了投影。
奇异值分解正是对线性变换这三种效应的一个析构。,
和
中的列向量都是互相正交的单位向量,
是对角矩阵,对角值
为奇异值,它表示我们找到了
和
这样两组基,
矩阵的作用是将一个向量从
这组正交基向量的空间旋转(可能会有升维降维的空间映射,投影)到
这组正交基向量空间,然后对每个方向进行了一定的缩放(乘个缩放因子),缩放因子就是各个奇异值(注:之前有讲过在不同的基下同一个线性变换矩阵实际上的变换效用是不同的。但由于这里的两个变换矩阵都是标准正交矩阵,故实际上可以理解为都是对同一组标准正交基
进行旋转(升维降维))。如果
维度比
大,则表示还进行了投影。可以说奇异值分解将一个矩阵原本混合在一起的三种作用效果,分解出来了。
而特征值分解其实是对旋转缩放两种效应的归并。有投影效应的矩阵不是方阵或者是奇异方阵,必有特征值为0。特征向量由得到,它表示如果一个向量
处于
的特征向量方向,那么
对
的线性变换作用只是一个缩放。也就是说,求特征向量和特征值的过程,我们找到了这样一组基,在这组基下,矩阵的作用效果仅仅是纯粹的缩放。对于实对称矩阵,特征向量正交,我们可以将特征向量式子写成
,这样就和奇异值分解类似了,就是
矩阵将一个向量从
这组基的空间旋转到
这组基的空间,并在每个方向进行了缩放。实际上可以理解为在标准正交基
上做了
变换再做缩放再做
变换,同时
与
的变换效用为旋转相同的角度但旋转方向相反,就是没有旋转或者理解为旋转了0度。
总而言之,特征值分解和奇异值分解都是给一个矩阵(线性变换)找一组特殊的基,特征值分解找到了特征向量这组基,在这组基下该线性变换只有缩放效果。而奇异值分解则是找到另一组基,这组基下线性变换的旋转、缩放、投影三种功能独立地展示出来了。
又因为有投影效应的矩阵不是方阵或者是奇异方阵,没有特征值或特征值为0,所以奇异值分解可以适用于所有矩阵,但特征值分解就仅仅适用于可逆方阵了。
另一方面,将矩阵变换析构出来方便于直观地理解矩阵变换的各个部分。特征值分解出来的矩阵有时并不直观,多个旋转变换冗杂在一起以及特征值会出现复数等情况。
三、SVD分解的应用
SVD在实际中应用非常广泛,每个应用场景再单写一篇文章都没有问题。这里我们先不做过多的展开,先举两个最重要的方面。
通过上面的式子很容易看出,原来矩阵的特征有维。而经过SVD分解之后,完全可以用前个非零奇异值对应的奇异向量表示矩阵的主要特征。这样,就天然起到了降维的作用。
还是看上面的式子,再结合第三部分的图,也很容易看出,经过SVD分解以后,要表示原来的大矩阵,我们只需要存三个较小的矩阵的即可。而这三个较小矩阵的规模,加起来也远远小于原有矩阵。这样,就天然起到了压缩的作用。
四、奇异值的计算:
奇异值的计算是一个难题,是一个O(N^3)的算法。在单机的情况下当然是没问题的,matlab在一秒钟内就可以算出1000 * 1000的矩阵的所有奇异值,但是当矩阵的规模增长的时候,计算的复杂度呈3次方增长,就需要并行计算参与了。Google的吴军老师在数学之美系列谈到SVD的时候,说起Google实现了SVD的并行化算法,说这是对人类的一个贡献,但是也没有给出具体的计算规模,也没有给出太多有价值的信息。
其实SVD还是可以用并行的方式去实现的,在解大规模的矩阵的时候,一般使用迭代的方法,当矩阵的规模很大(比如说上亿)的时候,迭代的次数也可能会上亿次,如果使用Map-Reduce框架去解,则每次Map-Reduce完成的时候,都会涉及到写文件、读文件的操作。个人猜测Google云计算体系中除了Map-Reduce以外应该还有类似于MPI的计算模型,也就是节点之间是保持通信,数据是常驻在内存中的,这种计算模型比Map-Reduce在解决迭代次数非常多的时候,要快了很多倍。
Lanczos迭代就是一种解对称方阵部分特征值的方法(之前谈到了,解得到的对称方阵的特征向量就是解
的右奇异向量),是将一个对称的方程化为一个三对角矩阵再进行求解。按网上的一些文献来看,Google应该是用这种方法去做的奇异值分解的。请见Wikipedia上面的一些引用的论文,如果理解了那些论文,也“几乎”可以做出一个SVD了。
由于奇异值的计算是一个很枯燥,纯数学的过程,而且前人的研究成果(论文中)几乎已经把整个程序的流程图给出来了。更多的关于奇异值计算的部分,将在后面的参考文献中给出,这里不再深入,我还是focus在奇异值的应用中去。
五、SVD与广义逆矩阵
在认识矩阵的广义逆之前,先来回顾一下方阵的逆。
对于一个 的方阵
的方阵 ,如果存在一个矩阵
,如果存在一个矩阵 ,使得
,使得 ,那么方阵
,那么方阵 的逆为
的逆为 。
。
那么对于非方阵来说情况又是怎样的? 比如对于 的矩阵
的矩阵 ,它的逆是怎样计算的?这就是我将要讨论的广义逆矩阵。
,它的逆是怎样计算的?这就是我将要讨论的广义逆矩阵。
矩阵的广义逆由Moore在1920年提出,后来在1955年经过Penrose发展得到如下定义:
对任意 复数矩阵
复数矩阵 ,如果存在
,如果存在 的矩阵
的矩阵 ,满足
,满足

则称 为
为 的一个Moore-Penrose逆,简称广义逆,记为
的一个Moore-Penrose逆,简称广义逆,记为 。并把上面四个方程叫做Moore-Penrose方程,简称M-P方程。
。并把上面四个方程叫做Moore-Penrose方程,简称M-P方程。
由于M-P的四个方程都各有一定的解释,并且应用起来各有方便之处,所以出于不同的目的,常常考虑满足部分方程的 ,叫做
,叫做
弱逆,弱逆不唯一。为了引用方便,下面给出广义逆矩阵的定义:
对于 的矩阵
的矩阵 ,若存在
,若存在 的矩阵
的矩阵 ,满足M-P方程中的全部或者其中的一部分,则称
,满足M-P方程中的全部或者其中的一部分,则称 为
为 的广义逆矩阵。
的广义逆矩阵。
实际上有结论:如果 满足M-P方程中的全部四个条件,那么得到的矩阵
满足M-P方程中的全部四个条件,那么得到的矩阵 是唯一的,如果只满足部分条件,那么得到的矩阵
是唯一的,如果只满足部分条件,那么得到的矩阵
不唯一。也就是说一个矩阵 的Moore-Penrose逆
的Moore-Penrose逆 是唯一的。而广义逆
是唯一的。而广义逆 的计算可以利用
的计算可以利用 的SVD分解得到,假设矩阵
的SVD分解得到,假设矩阵
 的SVD分解为:
的SVD分解为:

那么,不难验证

有了广义逆矩阵 ,那么就可以用来求解线性方程组
,那么就可以用来求解线性方程组 ,假设现在已经知道了矩阵
,假设现在已经知道了矩阵 的广义逆
的广义逆 ,如果矩阵
,如果矩阵 的
的
秩是 ,则其唯一解是
,则其唯一解是 ,如果秩小于
,如果秩小于 ,则有无穷多组解,其中最小范数解仍然是
,则有无穷多组解,其中最小范数解仍然是 ,通常我们关心
,通常我们关心
的也就是这个解。
六、SVD与最小二乘法
最常见的最小二乘问题是线性最小二乘问题。比如在三维空间有如下四个点

现在用一个方程 来拟合这四个点,这就是典型的线性最小二乘问题。接下来可以列出超定方程组,如下:
来拟合这四个点,这就是典型的线性最小二乘问题。接下来可以列出超定方程组,如下:

那么,进一步得到:

接下来用一个定理求最小二乘解,定理内容如下:
如上述超定系数方程组,一般情况下它是没有解的,但是我们可以让 尽可能地小。解下面的方程可以求得方程的最小二乘解。
尽可能地小。解下面的方程可以求得方程的最小二乘解。

这样最小二乘解又变成了解线性方程组问题,可以先用SVD来求出广义逆矩阵,然后解出 。最终求得解为
。最终求得解为

注:其实很容易发现这就是之前介绍的Normal Equation方法,这里主要介绍了广义逆可以通过SVD分解来求解得到。
参考文章:
机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用
奇异值矩阵分解(Singular Value Decomposition)的一些感想这篇文章没有引到,但看起来还不错,值得一看。
最近又看到一篇写的不错的文章,下次将会继续补充。