Hadoop简介:
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
推荐学习地址:http://dblab.xmu.edu.cn/blog/install-hadoop-cluster/
hadoop版本变更:

以Hadoop为核心的各种技术简介:

- Hadoop安装方式
在使用hadoop之前需配置Linux环境,一般选择使用虚拟机即可
单机模式:Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试
伪分布式模式:Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件
分布式模式:使用多个节点构成集群环境来运行Hadoop
Hadoop 2 可以到官网下载,需要下载 hadoop-2.x.y.tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用
如果读者是使用虚拟机方式安装Ubuntu系统的用户,请用虚拟机中的Ubuntu自带firefox浏览器访问本指南,再点击下载地址,才能把hadoop文件下载虚拟机ubuntu中。请不要使用Windows系统下的浏览器下载,文件会被下载到Windows系统中,虚拟机中的Ubuntu无法访问外部Windows系统的文件,造成不必要的麻烦。
如果读者是使用双系统方式安装Ubuntu系统的用户,请进去Ubuntu系统,在Ubuntu系统打开firefox浏览器,再点击下载
选择将 Hadoop 安装至 /usr/local/ 中
$ sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
$cd /usr/local/
$sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
$sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
查看安装信息
$ cd /usr/local/hadoop
$./bin/hadoop version
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。
- 伪分布式配置:
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml
Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现
根据以下步骤进行操作:
修改配置文件:core-site.xml,hdfs-site.xml,mapred-site.xml
初始化文件系统hadoop namenode -format
启动所有进程start-all.sh
访问web界面,查看Hadoop信息
运行实例
修改配置文件 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
name为fs.defaultFS的值,表示hdfs路径的逻辑名称
修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property></configuration>
dfs.datanode.data.dir表示本地磁盘目录,HDFS数据存放block的地方
dfs.namenode.name.dir表示本地磁盘目录,是存储fsimage文件的地方
dfs.replication表示副本的数量,伪分布式要设置为1
- 关于三种Shell命令方式的区别:
- hadoop fs
- hadoop dfs
- hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
- 启动Hadoop
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
运行成功会展示如下信息:
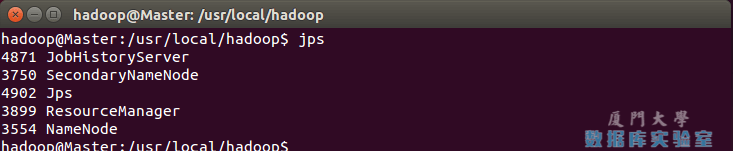
停止Hadoop
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
