前面介绍了Hadoop核心组件HDFS和MapReduce,Hadoop发展之初在架构设计和应用性能方面仍然存在不足,Hadoop的优化与发展一方面体现在两个核心组件的架构设计改进,一方面体现在Hadoop生态系统其他组件的不断丰富。此文介绍Hadoop2.0中添加的新特性。
一、HDFS 2.0新特性
这对HDFS的改进,HDFS 2.0主要增加了HDFS HA 以及HDFS联邦等新特性。
(一)HDFS HA
HA即High Availability,用于解决HDFS 1.0中的单点故障问题。
HDFS 1.0中,存在一个名称节点,一个第二名称节点,第二名称节点不是名称节点的备份,它的主要功能是解决当数据操作记录较多时,EdlirLog文件过大的问题,并不能提供热备份功能,当名称节点故障时无法提供实时切换,第二名称节点不能立即对外提供服务,需要停机恢复。
一旦唯一的名称节点出现故障,就会导致整个集群不可用,这就是“单点故障问题”。为解决这一问题,HDFS 2.0采用HA架构,集群包含两个名称节点,一个活跃(Active)状态,一个待机(Standby)状态:
Active状态的名称节点负责对外处理客户端请求;
Standby状态的节点负责提供热备份,保存足够的元数据信息,Active节点故障时提供快速恢复能力。
Standby名称节点作为备份节点,需要存储与Active节点一致的元数据信息,那么HA又是如何保证Active名称节点的信息实时同步到Standby名称节点的呢?
两名称节点的状态同步借助于共享存储系统实现,如NFS、QJM或Zookeeper。Active名称节点给将数据写入到共享存储系统,Standby节点监听共享存储系统,若有新写入,则从公共存储系统读取数据并加载到自己的内存,以此保证数据同步。
为了能让Standby节点随时接替Active节点对外提供服务,Standby节点也需要保存集群中各个块的位置信息,HA又是如何处理这个问题的呢?
HA架构下给数据节点配置两个名称节点地址,并把块的位置信息和心跳信息同时发送到两个名称节点。
当集群中存在两个名称节点时,需要保证某一时刻仅一个名称节点处于Active状态,这又是如何实现的呢?
HA使用Zookeeper确保任意时刻只有一个名称节点提供对外服务。
(二)HDFS联邦
HDFS HA解决了单点故障问题,但仍只有一个Active节点,仍存在可扩展性、系统性能、隔离性问题。单个工作名称节点,会造成集群横向扩展困难、单个节点吞吐量限制、一个程序消耗过多资源导致其他程序无法顺利运行等问题。
HDFS 联邦机制解决了上述问题,设计多个相互独立的名称节点,分别进行各自命名空间和块的管理,相互之间属于联邦关系,需不要彼此协调。兼容性方面,HDFS
联邦具有良好的向后兼容性,针对单名称节点的部署配置不需要做任何修改就可以继续工作。
1、HDFS 联邦的架构设计
HDFS联邦的名称节点提供命名空间和块管理功能,所有名称节点共享底层的数据节点存储资源。每个数据节点向集群中所有名称节点注册,周期性地向名称节点发送心跳信息报告自身状态,并处理所有名称节点的指令。
不同于HDFS 1.0中的单个命名空间,联邦提供多个独立的命名空间,每个命名空间管理属于自己的一组块,一个命名空间下的一组块成为一个“块池”,每个数据节点为多个块池提供块的存储。一个块池是一组块的逻辑集合,属于逻辑概念,块池中的各个块实际是存储在各个数据节点中的,数据节点是物理概念。HDFS联邦架构如下图:
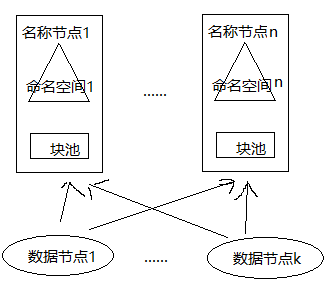
联邦中一个名称节点失效,不会影响与它相关的数据节点为其他名称节点提供服务。
2、HDFS联邦的访问方式
对于联邦中的多个命名空间,可以采用客户端挂载表的方式进行数据共享和访问。把各个命名空间挂载到全局挂载表,实现数据全局共享,客户端通过访问不同的挂载点来访问不同的子命名空间,命名空间挂载到个人的挂载表中就成为应用程序可见的命名空间。
注意,HDFS联邦不能解决单点故障问题,每个联邦内的名称节点都存在单点故障问题,需要为每个名称节点部署备份名称节点。