版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/m0_37324740/article/details/80929163
1 定义
1.1 生成式模型
生成式模型(Generative Model)会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得 p(yi|x),然后选取使得p(yi|x) 最大的 yi,即:
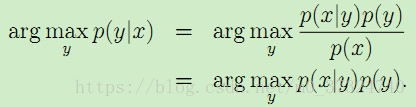
简单说生成式模型就是生成数据分布的模型。将求联合分布的问题转为了求类别先验概率和类别条件概率的问题。
1.2 判别式模型
对条件概率 p(y|x;) 直接建模。
简单说就是判别数据输出量的模型,解决问题的思路为:
条件分布>模型参数后延概率最大>似然函数*参数先验最大>最大似然
生成式模型可以转为判别式模型,反之不行。
AndrewNg在NIPS2001年有一篇专门比较判别模型和产生式模型的文章:
On Discrimitive vs. Generative classifiers: A comparision of logistic regression and naive Bayes
2 模型优劣比较
2.1 生成式模型
常见的生成式模型有:
- 线性判别式分析 (Linear Discriminant Analysis)
- 朴素贝叶斯 (Native Bayesian)
- K近邻 (KNN)
- 混合高斯模型 (GaussianMixture Model)
- 隐马尔科夫模型 (HiddenMarkov Model)
- 贝叶斯网络 (Bayesian Networks)
- 马尔科夫随机场 (Markov Random Fields)
- 深度信念网络 (Deep Belief Networks)
其特点在于(相比于判别式模型):
- 通常收敛速度较快,少量样本就可以收敛
- 能应付隐变量
- 需要对数据分布做出假设(比方朴素贝叶斯假设特征分布符合条件独立的假设)
- 计算量大
- 实践效果(比如分类)稍差
- 容易过拟合
- 更好利用无标签数据(DBN)
- 添加新的类别时,计算新的联合分布即可,不需要全部数据重新训练
- 能检测异常值
2.2 判别式模型
常见的判别式模型有:
- 线性回归 (LinearRegression)
- 逻辑斯蒂回归 (LogisticRegression)
- 神经网络 (NN)
- 支持向量机 (SVM)
- 高斯过程 (GaussianProcess)
- 条件随机场 (CRF)
- CART(Classificationand Regression Tree)
其特点在于(相比于生成式模型):
- 节省计算资源
- 节省样本
- 效果好一些
- 输入数据可以预处理(降维、构造等),简化学习的问题
- 解决凸优化问题
- 添加新的数据时,所有数据要重新训练
- 不能检测异常值
参考:
https://www.cnblogs.com/kemaswill/p/3427422.html
《统计学习方法》