总的来说,对于输入X,类别为Y的数据,生成模型是估计他们的连个概率密度P(X,Y),判别式模型为估计条件概率P(Y|X)。
生成模型:有数据学习联合概率密度P(X,Y),然后求出条件概率P(Y|X)作为预测模型,如贝叶斯、HMM、主题LDA。
判别模型:由数据直接学习决策函数Y=F(X),如KNN、SVM、LR、boosting。
如何区分?模型如果是直接根据数据X,直接判定Y的类别的话就是判别模型;间接判定Y的类别的话就是生成模型。
引用:
生成模型:以统计学和Bayes作为理论基础
1、朴素贝叶斯:
通过学习先验概率分布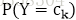
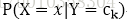
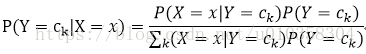
使用极大似然估计(使用样本中的数据分布来拟合数据的实际分布概率)得到先验概率。
判别模型
1、感知机 (线性分类模型)
输入空间为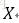
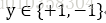
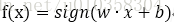
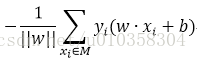
其中M为所有误分类点的集合,||w||可以不考虑。可以使用随机梯度下降得到最后的分类超平面。