文章目录
1.模型融合(aggregation models)
假如我们有多个模型,要怎么灵活运用将这些模型的结果呢?可以使用模型融合(aggregation models) 的方式,将n个模型的输出进一步融合成为一个输出,得到我们想要的结果,那么怎么融合多个模型呢?常见的方法有以下几种:
1.1 uniform blending
核心思想:少数服从多数,民主投票
如果知道n个模型的输出,每个模型有一票,则最终的输出:
如果是多分类,则最终输出得票数最多的分类即可。
如果是预测数值型输出,则最终的输出:
可以证明融合之后的模型要比原先的效果好(更稳定):
其中,
代表原始模型的均方误差,
表示融合模型的军方误差,它们之间相差了一个
,因此有
对于uniform blending,每个模型的输出要有所不同,这样融合之后的效果才有可能比单一的模型效果要好,否则平均下来得到的还是一样的结果。
1.2 Linear Bleading
核心思想 :让每个模型投票,但是给不同模型不同的票数,即给予它们不同的权重。最终的输出为:
此时要求解的目标为:
1.3 Stacking (condition blending)
核心思想 :让每个模型投票,但是在不同的条件下给不同模型不同的的权重,采用非线性的方式将模型的输出融合。这种方式比较强大,有过拟合的风险。
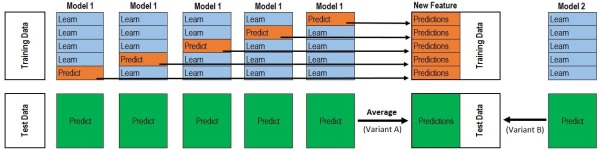
stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型。
通常使用K-fold来实现Stacking,假设我们使用5折交叉验证,有10000行训练集,2500行验证集,对于一个模型来说,5次交叉验证会将10000个训练集分成5份,每份2000个数据,每次以其中一份作为测试集,这样10000个数据都会被测试一次,最终我们可以得到
的矩阵
,同时每次交叉验证的时候都会对验证集进行预测,每次都可以得到一个
的矩阵,共得到5个。对于同一个样本的预测,我们使用平均的方式,最终5个矩阵合并为1个
的矩阵
。由于我们是在融合多个模型,自然不止一个模型。假如我们还有模型
,对于每一个模型重复上述步骤,我们可以得到
。将所有的A,B矩阵按列合并起来,得到
。以上步骤是Stacking第一层所完成的事情。
将得到的
作为第二层的训练集,
作为第二层的测试集,使用Liner Regression来总结所有模型的效果,得到最终的预测效果。
2. Bagging
如果说,我们一开始并没有很多个模型,也就无法运用上面的技巧了。因此我们需要通过学习的方式来得到多个模型,一边决定怎么把它们合起来。其中,Bagging是一种通过Bootstraping学习得到多个模型并利用uniform blending来融合模型的方法。
Bootstraping:从已有的样本中有放回地随机取n份样本。即同一个样本可能被取到多次。假如有10000个样本,可以迭代三千次,每次都取出一份bootstrap sample,每份bootstrap sample可以看做是新的数据,从而我们得到了3000个模型
。这是Bagging套袋法中一个重要的步骤。
Bagging的算法过程如下:
- 从原始样本集中按照Bootstraping方法抽取n个样本,共进行k次,得到k组训练集。
- 使用k组训练集得到k个模型。
- 对于分类问题使用投票的方式得到分类结果,对于回归问题使用均值作为最后的结果。
如果我们的模型对数据的随机性比较敏感的话,采用BAGging的方式得到的融合模型往往很有效果。
3. AdaBoost(Adaptive Boosting)
在Bagging的过程中,每次Boostraping取到的样本都是独立随机的。而在模型融合的算法中,我们认为每个基分类器如果越不一样的,则融合得到的效果是最好的。考虑这样一种情况,在当前一轮取到的样本得到的模型
,如果让他在
的表现变得和抛硬币的情况一样,那么在
的样本就会使得
跟
的差别变大,也就是说两个分类器会得到很不一样的决策边界。
而boostraping的过程其实就是在给样本赋予不同权重的过程,比如说,我们取到了3个样本1,,0个样本2,1个样本3,那么他们的权重就分别是3,0,1。要改变下一个模型的表现,其实只要修改它们的权重即可。令
表示当前模型下分类错误的比例。则我们的权重优化操作为:
- 将正确分类的样本权重乘上
- 将错误分类的样本权重乘上
或者我们进一步定义放缩因子 ,则权重优化操作变为:
- 将正确分类的样本权重除以
- 将错误分类的样本权重乘上
在通常
都要小于
,否则我们的基学习器就比抛硬币的概率还低了。此时
,则上面的式子表现为增大错误分类的权重,缩小正确分类的权重。经过上面的修正,当前模型的表现就会变成五五开的情况。
通常一开始的权重u初始化为
,即每个样本都取一次。
那我们最终要怎么确定每个模型
在最终模型h中占用的权重呢?考虑模型有的可能变现较差,有的表现较好,那么给予不同的权重是一个合理的选择。对于一个表现良好的模型
,它的缩放因子t会更大,因此可以考虑使用
。当t越大时,错误率
越低,得到的权重越大,当t=1时,错误率
为
,
=0,即这样的模型不予考虑,因为他跟抛硬币没什么区别。
最终我们得到Adaptive Boosting的算法流程如下:
- 初始化权重
- 根据当前权重 获得当前错误率 最小的模型
- 计算缩放因子
- 更新 ,即将正确分类样本的权重除以t,将错误分类样本的权重乘以t。
- 计算当前模型在融合模型中的权重
- 重复步骤2-5 T次。
- 得到最终模型 。