版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/redRnt/article/details/82943578
对DFS的过程分析
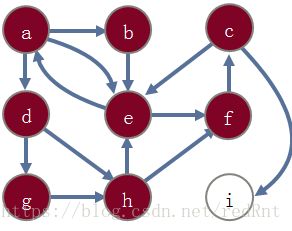
在前面的文章中我们提到了这样的一幅图:
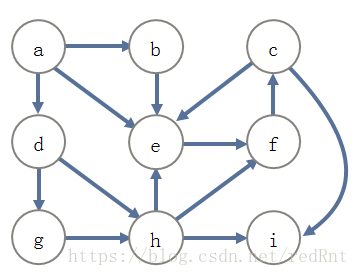
我们知道,在DFS中,我们采用的是递归的方式进行实现的,并且给每一个遍历过的点都做上了标记,目的是为了防止程序进入死循环。(为什么树可以不需要呢?因为树没有环)
利用之前专栏提到的递归模式,我们可以写出下面的伪代码:
dfs from v1 to v2:
base case: if at v2, found! //基础事件,假设v1就是v2
mark v1 as visited. //否则,标记V1
for all edges from v1 to its neighbors: //遍历V1节点的所有邻居
//如果它的邻居未曾被访问,那么对该节点递归调用dfs
if neighbor n is unvisited, recursively call dfs(n, v2)
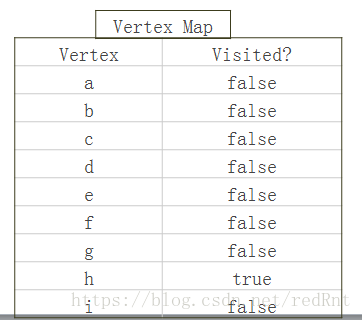
如果我们用true或者false来表示节点是否被访问,那么假设从H出发访问C节点,初始状态应该是这样的:
而调用栈此时应该是这样的:
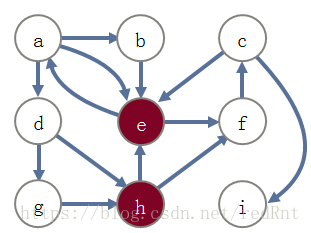
根据按字母表顺序优先访问的规则此时,访问的下一个节点应该是节点E,此时对应的内容为:
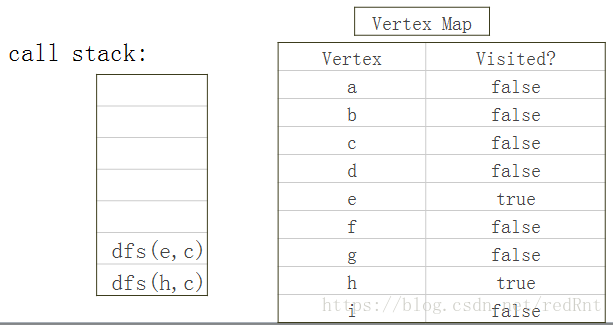
如此继续,直到调用到顶点G的时候,已经没有未标记的路可以走了,此时开始回溯:
回溯的过程就是将函数调用出栈的过程:
回到节点E,继续调用dfs算法:
此时找到H->C的路径。




DFS的栈实现(非递归算法的实现)
伪代码如下
dfs from v1 to v2:
create a stack, s //创建一个空的栈s
s.push(v1) //将起始节点入栈
while s is not empty://当栈不为空时
v = s.pop() //将栈中的元素弹出,并赋值给节点类型的变量V
if v has not been visited://如果v没有被访问
mark v as visited//标记V
//将所有v节点的邻居入栈
push all neighbors of v onto the stack
我们就用上面的步骤继续分析一下DFS的具体数据在栈中的情况(从H到C)
- 一开始我们建立一个空的栈,将节点h入栈,此时栈中只有元素H:
- 此时的栈不为空了, 在while循环中执行赋值语句后,v = h,此时h节点尚未被标记,于是标记点h,并且将h的所有邻居节点入栈,(为什么G节点不是?因为这是有向图);
- 同样这里因为F是栈顶,所以我们先弹出的是节点F,同样执行上述操作,F的邻居是C,所以把C入栈,即如图所示:


4. 在下一次循环中 我们发现
栈中弹出的值恰好就是我们要寻找的值,于是停止搜索。也就是说这样的效率比递归要高:

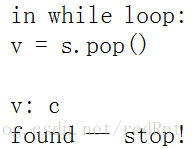
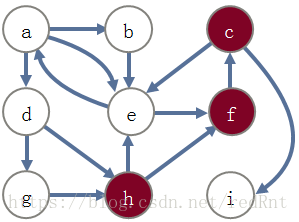
DFS的递归和迭代解决方案都是正确的,但由于递归与使用堆栈的细微差别,它们以不同的顺序遍历节点。
对于h到c的例子,迭代解决方案碰巧更快,但对于不同的图,递归解决方案可能更快。
总结:
在给定节点处调用DFS可以查找从该节点开始所有可到达的节点。(由此判断图是否为连通的)
如果我们有一个邻接列表,在n个节点,m条边的图中执行DFS,需要时间O(m + n),空间O(n)。