1. 图的基本介绍
图是一种数据结构,其中结点可以具有零个或多个相邻元素。两个结点之间的连接称为边。 结点也可以称为顶点。如图:

2. 图的常用概念
1)顶点(vertex)
2)边(edge)
3)无向图(下图):顶点之间的连接没有方向,比如A-B,即可以是 A-> B 也可以 B->A .
4)路径:比如从 D -> C 的路径有
- D->B->C
- D->A->B->C

5)有向图
6)带权图

3. 图的表示方式
图的表示方式有两种:二维数组表示(邻接矩阵);链表表示(邻接表)。
邻接矩阵
邻接矩阵是表示图形中顶点之间相邻关系的矩阵,对于n个顶点的图而言,矩阵是的row和col表示的是1....n个点。

邻接表
1)邻接矩阵需要为每个顶点都分配n个边的空间,其实有很多边都是不存在,会造成空间的一定损失.
2)邻接表的实现只关心存在的边,不关心不存在的边。因此没有空间浪费,邻接表由数组+链表组成

说明:
- 标号为0的结点的相关联的结点为 1 2 3 4
- 标号为1的结点的相关联结点为0 4,
- 标号为2的结点相关联的结点为 0 4 5
- ....
4. 图的快速入门案例
要求: 代码实现如下图结构:

/**
*
* 图
*/
public class Graph {
private ArrayList<String> vertexList; //存储顶点集合
private int[][] edges; //存储图对应的邻结矩阵
private int numOfEdges; //表示边的数目
private boolean[] isVisited; //记录某个结点是否被访问
//构造器
public Graph(int n){
//初始化矩阵和vertexList
edges = new int[n][n];
vertexList = new ArrayList<String>(n);
numOfEdges = 0;
// isVisited = new boolean[n];
}
//得到第一个邻接点的下标w
public int getFirstNeighbor(int index){
for (int j = 0; j < vertexList.size(); j++) {
if(edges[index][j] > 0)
return j;
}
return -1;
}
//根据前一个邻接结点的下标来获取下一个邻接结点
public int getNextNeighbor(int v1, int v2){
for (int j = v2 + 1; j < vertexList.size(); j++) {
if(edges[v1][j] > 0)
return j;
}
return -1;
}
//深度优先遍历算法
private void dfs(boolean[] isVisited, int i){
//首先我们访问该结点,输出
System.out.print(getValueByIndex(i) + "-->");
//将结点设置为已经访问
isVisited[i] = true;
//查找结点i的第一个邻接结点w
int w = getFirstNeighbor(i);
while (w != -1){
if(!isVisited[w])
dfs(isVisited, w);
//如果w结点已经被访问过
w = getNextNeighbor(i, w);
}
}
//对dfs进行重载,遍历所有的结点,并进行dfs
public void dfs(){
isVisited = new boolean[vertexList.size()];
//遍历所有的结点,进行dfs[回溯]
for (int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i])
dfs(isVisited, i);
}
}
//对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited, int i){
int u; //表示队列的头结点对应下标
int w; //邻接结点w
//队列,记录结点访问的顺序
LinkedList queue = new LinkedList();
//访问结点,输出结点信息
System.out.print(getValueByIndex(i) + "-->");
//标记为已访问
isVisited[i] = true;
//将结点加入队列
queue.addLast(i);
while ( !queue.isEmpty()){
//取出队列的头结点下标
u = (Integer)queue.removeFirst();
//得到第一个邻接结点的下标w
w = getFirstNeighbor(u);
while (w != -1){ //找到
//是否访问过
if(!isVisited[w]){
System.out.print(getValueByIndex(w) + "-->");
//标记已经访问
isVisited[w] = true;
//入队
queue.addLast(w);
}
//以u为前驱点,找w后面的下一个邻接点
w = getNextNeighbor(u, w); //体现广度优先
}
}
}
//遍历所有的结点,都进行广度优先
public void bfs(){
isVisited = new boolean[vertexList.size()]; //如果想让深度和广度预先同时运行,把构造器中的初始化放到两个重载的方法中
for (int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i])
bfs(isVisited, i);
}
}
//返回结点的个数
public int getNumOfVertex(){
return vertexList.size();
}
//显示图对应的矩阵
public void showGraph(){
for (int[] link : edges) {
System.out.println(Arrays.toString(link));
}
}
//返回边的个数
public int getNumOfEdges(){
return numOfEdges;
}
//返回返回结点 i(下标)对应的数据 0->"A" 1->"B" 2->"C"
public String getValueByIndex(int i){
return vertexList.get(i);
}
//返回v1和v2的权值
public int getWeight(int v1, int v2){
return edges[v1][v2];
}
//插入结点
public void insertVertex(String vertex){
vertexList.add(vertex);
}
//添加边
/**
* @param v1 表示点的下标即使第几个顶点 "A"-"B" "A"->0 "B"->1
* @param v2 第二个顶点的下标
* @param weight
* */
public void insertEdge(int v1, int v2, int weight){
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges ++;
}
}Test:
public static void main(String[] args) {
int n = 5; //结点的个数
String vertexValue[] = {"A","B","C","D","E"};
//创建图对象
Graph graph = new Graph(n);
//循环添加顶点
for (String value : vertexValue) {
graph.insertVertex(value);
}
//添加边
//A-B A-C B-C B-D B-E
graph.insertEdge(0,1,1); //A-B
graph.insertEdge(0,2,1); //
graph.insertEdge(1,2,1); //
graph.insertEdge(1,3,1); //
graph.insertEdge(1,4,1); //
//显示邻接矩阵
graph.showGraph();
//深度优先遍历
// System.out.println("深度优先");
// graph.dfs();
//广度优先
System.out.println("广度优先");
graph.bfs();
}Output:
[0, 1, 1, 0, 0]
[1, 0, 1, 1, 1]
[1, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
广度优先
A-->B-->C-->D-->E-->5. 图的遍历
5.1 图遍历介绍
所谓图的遍历,即是对结点的访问。一个图有那么多个结点,如何遍历这些结点,需要特定策略,一般有两种访问策略: ①深度优先遍历 ②广度优先遍历
5.2 图的深度优先搜索(Depth First Search)
1)深度优先遍历,从初始访问结点出发,初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点, 可以这样理解:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
2)我们可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。
3)显然,深度优先搜索是一个递归的过程
深度优先遍历算法步骤:
- 1)访问初始结点v,并标记结点v为已访问。
- 2)查找结点v的第一个邻接结点w。
- 3)若w存在,则继续执行4,如果w不存在,则回到第1步,将从v的下一个结点继续。
- 4)若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123)。
- 5)查找结点v的w邻接结点的下一个邻接结点,转到步骤3。
5.3 图的广度优先搜索(Broad First Search)
广度优先搜索(BFS)类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点
广度优先遍历算法步骤
1) 访问初始结点v并标记结点v为已访问。
2) 结点v入队列
3) 当队列非空时,继续执行,否则算法结束。
4) 出队列,取得队头结点u。
5) 查找结点u的第一个邻接结点w。
6) 若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
- 若结点 w 尚未被访问,则访问结点 w 并标记为已访问。
- 结点 w 入队列
- 查找结点 u 的继 w 邻接结点后的下一个邻接结点 w,转到步骤6。
6. 最小生成树(Minimum Cost Spanning Tree,简称MST)
6.1 最小生成树的基本介绍:
1) 给定一个带权的无向连通图,如何选取一棵生成树,使树上所有边上权的总和为最小,这叫最小生成树 。
2) N 个顶点,一定有 N - 1 条边。
3) 包含全部顶点。
4) N - 1 条边都在图中。
5)举例说明(如图:)

求最小生成树的算法主要是普里姆算法和克鲁斯卡尔算法
6.2 普里姆算法(Prim)
6.2.1 普里姆算法介绍
1) 普利姆(Prim)算法求最小生成树,也就是在包含 n 个顶点的连通图中,找出只有 (n-1) 条边包含所有 n 个顶点的连通子图,也就是所谓的极小连通子图。
2) 普利姆的算法:
①设G=(V,E)是连通网,T=(U,D)是最小生成树,V,U是顶点集合,E,D是边的集合 。
②若从顶点u开始构造最小生成树,则从集合V中取出顶点u放入集合U中,标记顶点v的visited[u]=1。
③若集合U中顶点ui与集合V-U中的顶点vj之间存在边,则寻找这些边中权值最小的边,但不能构成回路,将顶点vj加入集合U中,将边(ui,vj)加入集合D中,标记visited[vj]=1。
④重复步骤②,直到U与V相等,即所有顶点都被标记为访问过,此时D中有n-1条边。
(加入第一个顶点时,找与该顶点相连 权值最小的边的顶点,加入集合中;第二次就是找与这两个顶点相连 权值最小的边的顶点加入集合....)
6.2.2 普里姆算法最佳实践 - 修路问题
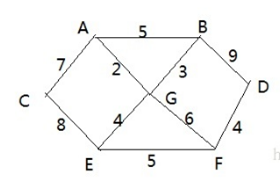
有胜利乡有 7 个村庄(A, B, C, D, E, F, G) ,现在需要修路把7个村庄连通。各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里。问:如何修路保证各个村庄都能连通,并且总的修建公路总里程最短?

/**
*
* 普里姆算法(Prim) - 村庄修路问题
*/
public class PrimAlgorithm {
public static void main(String[] args) {
char[] data = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
int vertex = data.length;
//邻接矩阵的关系使用二维数组表示,10000这个大数,表示两个点不联通
int [][]weight=new int[][]{
{10000,5,7,10000,10000,10000,2},
{5,10000,10000,9,10000,10000,3},
{7,10000,10000,10000,8,10000,10000},
{10000,9,10000,10000,10000,4,10000},
{10000,10000,8,10000,10000,5,4},
{10000,10000,10000,4,5,10000,6},
{2,3,10000,10000,4,6,10000},};
//创建MGraph对象
MGraph graph = new MGraph(vertex);
//创建一个MinTree对象
MinTree minTree = new MinTree();
minTree.createGraph(graph, vertex, data, weight);
//输出
minTree.showGraph(graph);
//测试普利姆算法
minTree.prim(graph, 0);//
}
}
//创建最小生成树 --> 村庄的图
class MinTree{
//创建图的邻接矩阵
/**
* @param graph 图对象
* @param vertex 图对应的顶点个数
* @param data
* @param weight
* */
public void createGraph(MGraph graph, int vertex, char data[], int[][] weight){
int i, j;
for(i = 0; i < vertex; i++){
graph.data[i] = data[i];
for(j = 0; j < vertex; j++)
graph.weight[i][j] = weight[i][j];
}
}
//显示图的邻接矩阵
public void showGraph(MGraph graph){
for(int[] link : graph.weight)
System.out.println(Arrays.toString(link));
}
//编写prim算法,得到最小生成树
/**
*
* @param graph 图
* @param v 表示从图的第几个顶点开始生成'A'->0 'B'->1...
*/
public void prim(MGraph graph, int v) {
//visited[] 标记结点(顶点)是否被访问过
int visited[] = new int[graph.vertex];
//visited[] 默认元素的值都是0, 表示没有访问过
// for(int i =0; i <graph.verxs; i++) {
// visited[i] = 0;
// }
//把当前这个结点标记为已访问
visited[v] = 1;
//h1 和 h2 记录两个顶点的下标
int h1 = -1;
int h2 = -1;
int minWeight = 10000; //将 minWeight 初始成一个大数,后面在遍历过程中,会被替换
for(int k = 1; k < graph.vertex; k++) {//因为有 graph.verxs顶点,普利姆算法结束后,有 graph.verxs-1边
//这个是确定每一次生成的子图 ,和哪个结点的距离最近
for(int i = 0; i < graph.vertex; i++) {// i结点表示被访问过的结点
for(int j = 0; j< graph.vertex;j++) {//j结点表示还没有访问过的结点
if(visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight) {
//替换minWeight(寻找已经访问过的结点和未访问过的结点间的权值最小的边)
minWeight = graph.weight[i][j];
h1 = i;
h2 = j;
}
}
}
//找到一条边是最小
System.out.println("边<" + graph.data[h1] + "," + graph.data[h2] + "> 权值:" + minWeight);
//将当前这个结点标记为已经访问
visited[h2] = 1;
//minWeight 重新设置为最大值 10000
minWeight = 10000;
}
}
}
class MGraph{
int vertex; //表示图的结点个数
char[] data; //存放结点数据
int[][] weight; //存放边,就是邻接矩阵
public MGraph(int vertex){
this.vertex = vertex;
data = new char[vertex];
weight = new int[vertex][vertex];
}
}Output:
[10000, 5, 7, 10000, 10000, 10000, 2]
[5, 10000, 10000, 9, 10000, 10000, 3]
[7, 10000, 10000, 10000, 8, 10000, 10000]
[10000, 9, 10000, 10000, 10000, 4, 10000]
[10000, 10000, 8, 10000, 10000, 5, 4]
[10000, 10000, 10000, 4, 5, 10000, 6]
[2, 3, 10000, 10000, 4, 6, 10000]
边<A,G> 权值:2
边<G,B> 权值:3
边<G,E> 权值:4
边<E,F> 权值:5
边<F,D> 权值:4
边<A,C> 权值:7
6.3 克鲁斯卡尔算法(Kruskal)
6.3.1 克鲁斯卡尔算法介绍
1) 克鲁斯卡尔算法,是用来求加权连通图的最小生成树的算法。
2) 基本思想:按照权值从小到大的顺序选择 n - 1 条边,并保证这 n - 1 条边不构成回路。
3) 具体做法:首先构造一个只含 n 个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
(第一次选择 权值最小的边连起来,第二次选择 权值第二小的边连起来...直到成为一棵树为止。)
6.3.2 克鲁斯卡尔最佳实践 - 公交站问题

有北京有新增 7 个站点(A, B, C, D, E, F, G) ,现在需要修路把 7 个站点连通。各个站点的距离用边线表示(权) ,比如 A – B 距离 12 公里。问:如何修路保证各个站点都能连通,并且总的修建公路总里程最短?
克鲁斯卡尔算法需要解决的两个问题:
问题一 对图的所有边按照权值大小进行排序。
问题二 将边添加到最小生成树中时,怎么样判断是否形成了回路。
问题一很好解决,采用排序算法进行排序即可。
问题二,处理方式是:记录顶点在"最小生成树"中的终点,顶点的终点是"在最小生成树中与它连通的最大顶点"。然后每次需要将一条边添加到最小生存树时,判断该边的两个顶点的终点是否重合,重合的话则会构成回路。
如何判断是否构成回路-举例说明(如图)
在将<E,F> <C,D> <D,E>加入到最小生成树R中之后,这几条边的顶点就都有了终点:
(01) C的终点是F。
(02) D的终点是F。
(03) E的终点是F。
(04) F的终点是F。关于终点的说明:
- 将所有顶点按照从小到大的顺序排列好之后;某个顶点的终点就是"与它连通的最大顶点"。
- 因此,接下来,虽然<C,E>是权值最小的边。但是C和E的终点都是F,即它们的终点相同,因此,将<C,E>加入最小生成树的话,会形成回路。这就是判断回路的方式。也就是说,我们加入的边的两个顶点不能都指向同一个终点,否则将构成回路。

/**
*
* 鲁斯卡尔算法
*/
public class KruskalCase {
public static void main(String[] args) {
char[] vertexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
//克鲁斯卡尔算法的邻接矩阵
int matrix[][] = {
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ { 0, 12, INF, INF, INF, 16, 14},
/*B*/ { 12, 0, 10, INF, INF, 7, INF},
/*C*/ { INF, 10, 0, 3, 5, 6, INF},
/*D*/ { INF, INF, 3, 0, 4, INF, INF},
/*E*/ { INF, INF, 5, 4, 0, 2, 8},
/*F*/ { 16, 7, 6, INF, 2, 0, 9},
/*G*/ { 14, INF, INF, INF, 8, 9, 0}};
//创建KruskalCase 对象实例
KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);
//输出构建的
kruskalCase.print();
kruskalCase.kruskal();
}
private int edgeNum; //边的个数
private char[] vertexs; //顶点数组
private int[][] matrix; //邻接矩阵
//使用 INF 表示两个顶点不能连通
private static final int INF = Integer.MAX_VALUE;
//构造器
public KruskalCase(char[] vertexs, int[][] matrix) {
//初始化顶点数和边的个数
int vlen = vertexs.length;
//初始化顶点, 复制拷贝的方式
this.vertexs = new char[vlen];
for(int i = 0; i < vertexs.length; i++) {
this.vertexs[i] = vertexs[i];
}
//初始化边, 使用的是复制拷贝的方式
this.matrix = new int[vlen][vlen];
for(int i = 0; i < vlen; i++) {
for(int j= 0; j < vlen; j++) {
this.matrix[i][j] = matrix[i][j];
}
}
//统计边的条数
for(int i =0; i < vlen; i++) {
for(int j = i+1; j < vlen; j++) {
if(this.matrix[i][j] != INF) {
edgeNum++;
}
}
}
}
public void kruskal() {
int index = 0; //表示最后结果数组的索引
int[] ends = new int[edgeNum]; //用于保存"已有最小生成树" 中的每个顶点在最小生成树中的终点
//创建结果数组, 保存最后的最小生成树
EData[] rets = new EData[edgeNum];
//获取图中 所有的边的集合 , 一共有12边
EData[] edges = getEdges();
System.out.println("图的边的集合=" + Arrays.toString(edges) + " 共"+ edges.length); //12
//按照边的权值大小进行排序(从小到大)
sortEdges(edges);
//遍历edges 数组,将边添加到最小生成树中时,判断是准备加入的边否形成了回路,如果没有,就加入 rets, 否则不能加入
for(int i=0; i < edgeNum; i++) {
//获取到第i条边的第一个顶点(起点)
int p1 = getPosition(edges[i].start); //p1=4
//获取到第i条边的第2个顶点
int p2 = getPosition(edges[i].end); //p2 = 5
//获取p1这个顶点在已有最小生成树中的终点
int m = getEnd(ends, p1); //m = 4
//获取p2这个顶点在已有最小生成树中的终点
int n = getEnd(ends, p2); // n = 5
//是否构成回路
if(m != n) { //没有构成回路
ends[m] = n; // 设置m 在"已有最小生成树"中的终点 <E,F> [0,0,0,0,5,0,0,0,0,0,0,0]
rets[index++] = edges[i]; //有一条边加入到rets数组
}
}
//<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。
//统计并打印 "最小生成树", 输出 rets
System.out.println("最小生成树为");
for(int i = 0; i < index; i++) {
System.out.println(rets[i]);
}
}
//打印邻接矩阵
public void print() {
System.out.println("邻接矩阵为: \n");
for(int i = 0; i < vertexs.length; i++) {
for(int j=0; j < vertexs.length; j++) {
System.out.printf("%12d", matrix[i][j]);
}
System.out.println();//换行
}
}
/**
* 功能:对边进行排序处理, 冒泡排序
* @param edges 边的集合
*/
private void sortEdges(EData[] edges) {
for(int i = 0; i < edges.length - 1; i++) {
for(int j = 0; j < edges.length - 1 - i; j++) {
if(edges[j].weight > edges[j+1].weight) {//交换
EData tmp = edges[j];
edges[j] = edges[j+1];
edges[j+1] = tmp;
}
}
}
}
/**
*
* @param ch 顶点的值,比如'A','B'
* @return 返回ch顶点对应的下标,如果找不到,返回-1
*/
private int getPosition(char ch) {
for(int i = 0; i < vertexs.length; i++) {
if(vertexs[i] == ch) {//找到
return i;
}
}
//找不到,返回-1
return -1;
}
/**
* 功能: 获取图中边,放到EData[] 数组中,后面我们需要遍历该数组
* 是通过matrix 邻接矩阵来获取
* EData[] 形式 [['A','B', 12], ['B','F',7], .....]
* @return
*/
private EData[] getEdges() {
int index = 0;
EData[] edges = new EData[edgeNum];
for(int i = 0; i < vertexs.length; i++) {
for(int j=i+1; j <vertexs.length; j++) {
if(matrix[i][j] != INF) {
edges[index++] = new EData(vertexs[i], vertexs[j], matrix[i][j]);
}
}
}
return edges;
}
/**
* 功能: 获取下标为i的顶点的终点(), 用于后面判断两个顶点的终点是否相同
* @param ends : 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成
* @param i : 表示传入的顶点对应的下标
* @return 返回的就是 下标为i的这个顶点对应的终点的下标
*/
private int getEnd(int[] ends, int i) { // i = 4 [0,0,0,0,5,0,0,0,0,0,0,0]
while(ends[i] != 0) {
i = ends[i];
}
return i;
}
}
//创建一个类EData ,它的对象实例就表示一条边
class EData {
char start; //边的一个点
char end; //边的另外一个点
int weight; //边的权值
//构造器
public EData(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
//重写toString, 便于输出边信息
@Override
public String toString() {
return "EData [<" + start + ", " + end + ">= " + weight + "]";
}
}邻接矩阵为:
0 12 2147483647 2147483647 2147483647 16 14
12 0 10 2147483647 2147483647 7 2147483647
2147483647 10 0 3 5 6 2147483647
2147483647 2147483647 3 0 4 2147483647 2147483647
2147483647 2147483647 5 4 0 2 8
16 7 6 2147483647 2 0 9
14 2147483647 2147483647 2147483647 8 9 0
图的边的集合=[EData [<A, B>= 12], EData [<A, F>= 16], EData [<A, G>= 14], EData [<B, C>= 10], EData [<B, F>= 7], EData [<C, D>= 3], EData [<C, E>= 5], EData [<C, F>= 6], EData [<D, E>= 4], EData [<E, F>= 2], EData [<E, G>= 8], EData [<F, G>= 9]] 共12
最小生成树为
EData [<E, F>= 2]
EData [<C, D>= 3]
EData [<D, E>= 4]
EData [<B, F>= 7]
EData [<E, G>= 8]
EData [<A, B>= 12]
7. 最短路径
7.1 迪杰斯特拉算法(Dijkstra)
7.1.1 迪杰斯特拉(Dijkstra)算法介绍
迪杰斯特拉算法是典型最短路径算法,用于计算一个结点到其他各个结点的最短路径。 它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。


7.1.2 迪杰斯特拉算法过程
设置出发顶点为v,顶点集合 V{v1,v2,vi...},v 到 V 中各顶点的距离构成距离集合 Dis,Dis{d1,d2,di...},Dis 集合记录着 v 到图中各顶点的距离 (到自身可以看作 0,v 到 vi 距离对应为 di )。
1) 从 Dis 中选择值最小的 di 并移出 Dis 集合,同时移出 V 集合中对应的顶点 vi,此时的 v 到 vi 即为最短路径。
2) 更新 Dis 集合,更新规则为:比较 v 到 V 集合中顶点的距离值,与 v 通过 vi 到 V 集合中顶点的距离值,保留值较小的一个 (同时也应该更新顶点的前驱节点为 vi,表明是通过 vi 到达的)。
3) 重复执行两步骤,直到最短路径顶点为目标顶点即可结束。
7.1.3 迪杰斯特拉(Dijkstra)算法最佳应用 - 最短路径
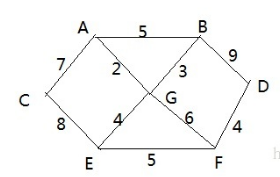
战争时期,胜利乡有7个村庄(A, B, C, D, E, F, G) ,现在有六个邮差,从G点出发,需要分别把邮件分别送到 A, B, C , D, E, F 六个村庄。各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里。问:如何计算出G村庄到其它各个村庄的最短距离? 如果从其它点出发到各个点的最短距离又是多少?
Dijkstra算法图解:


/**
* 迪杰斯特拉算法
*/
public class DijkstraAlgorithm {
public static void main(String[] args) {
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
//邻接矩阵
int[][] matrix = new int[vertex.length][vertex.length];
final int N = 65535; // 表示不可以连接
matrix[0]=new int[]{N,5,7,N,N,N,2};
matrix[1]=new int[]{5,N,N,9,N,N,3};
matrix[2]=new int[]{7,N,N,N,8,N,N};
matrix[3]=new int[]{N,9,N,N,N,4,N};
matrix[4]=new int[]{N,N,8,N,N,5,4};
matrix[5]=new int[]{N,N,N,4,5,N,6};
matrix[6]=new int[]{2,3,N,N,4,6,N};
//创建 Graph对象
Graph graph = new Graph(vertex, matrix);
//测试, 看看图的邻接矩阵是否ok
graph.showGraph();
//测试迪杰斯特拉算法
graph.dsj(2);//C
graph.showDijkstra();
}
}
class Graph {
private char[] vertex; // 顶点数组
private int[][] matrix; // 邻接矩阵
private VisitedVertex vv; //已经访问的顶点的集合
// 构造器
public Graph(char[] vertex, int[][] matrix) {
this.vertex = vertex;
this.matrix = matrix;
}
//显示结果
public void showDijkstra() {
vv.show();
}
// 显示图
public void showGraph() {
for (int[] link : matrix) {
System.out.println(Arrays.toString(link));
}
}
//迪杰斯特拉算法实现
/**
* @param index 表示出发顶点对应的下标
*/
public void dsj(int index) {
vv = new VisitedVertex(vertex.length, index);
update(index);//更新index顶点到周围顶点的距离和前驱顶点
for(int j = 1; j <vertex.length; j++) {
index = vv.updateArr();// 选择并返回新的访问顶点
update(index); // 更新index顶点到周围顶点的距离和前驱顶点
}
}
//更新index下标顶点到周围顶点的距离和周围顶点的前驱顶点,
private void update(int index) {
int len = 0;
//根据遍历我们的邻接矩阵的 matrix[index]行
for(int j = 0; j < matrix[index].length; j++) {
// len 含义是 : 出发顶点到index顶点的距离 + 从index顶点到j顶点的距离的和
len = vv.getDis(index) + matrix[index][j];
// 如果j顶点没有被访问过,并且 len 小于出发顶点到j顶点的距离,就需要更新
if(!vv.in(j) && len < vv.getDis(j)) {
vv.updatePre(j, index); //更新j顶点的前驱为index顶点
vv.updateDis(j, len); //更新出发顶点到j顶点的距离
}
}
}
}
// 已访问顶点集合
class VisitedVertex {
// 记录各个顶点是否访问过 1表示访问过,0未访问,会动态更新
public int[] already_arr;
// 每个下标对应的值为前一个顶点下标, 会动态更新
public int[] pre_visited;
// 记录出发顶点到其他所有顶点的距离,比如G为出发顶点,就会记录G到其它顶点的距离,会动态更新,求的最短距离就会存放到dis
public int[] dis;
//构造器
/**
* @param length :表示顶点的个数
* @param index: 出发顶点对应的下标, 比如G顶点,下标就是6
*/
public VisitedVertex(int length, int index) {
this.already_arr = new int[length];
this.pre_visited = new int[length];
this.dis = new int[length];
//初始化 dis数组
Arrays.fill(dis, 65535);
this.already_arr[index] = 1; //设置出发顶点被访问过
this.dis[index] = 0;//设置出发顶点的访问距离为0
}
/**
* 功能: 判断index顶点是否被访问过
* @param index
* @return 如果访问过,就返回true, 否则访问false
*/
public boolean in(int index) {
return already_arr[index] == 1;
}
/**
* 功能: 更新出发顶点到index顶点的距离
* @param index
* @param len
*/
public void updateDis(int index, int len) {
dis[index] = len;
}
/**
* 功能: 更新pre这个顶点的前驱顶点为index顶点
* @param pre
* @param index
*/
public void updatePre(int pre, int index) {
pre_visited[pre] = index;
}
/**
* 功能:返回出发顶点到index顶点的距离
* @param index
*/
public int getDis(int index) {
return dis[index];
}
/**
* 继续选择并返回新的访问顶点, 比如这里的G 完后,就是 A点作为新的访问顶点(注意不是出发顶点)
* @return
*/
public int updateArr() {
int min = 65535, index = 0;
for(int i = 0; i < already_arr.length; i++) {
if(already_arr[i] == 0 && dis[i] < min ) {
min = dis[i];
index = i;
}
}
//更新 index 顶点被访问过
already_arr[index] = 1;
return index;
}
//显示最后的结果
//即将三个数组的情况输出
public void show() {
System.out.println("---------------------------------------");
//输出already_arr
for(int i : already_arr) {
System.out.print(i + " ");
}
System.out.println();
//输出pre_visited
for(int i : pre_visited) {
System.out.print(i + " ");
}
System.out.println();
//输出dis
for(int i : dis) {
System.out.print(i + " ");
}
System.out.println();
//为了好看最后的最短距离,我们处理
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
int count = 0;
for (int i : dis) {
if (i != 65535) {
System.out.print(vertex[count] + "("+i+") ");
} else {
System.out.println("N ");
}
count++;
}
System.out.println();
}
}7.2 弗洛伊德算法(Floyd)
7.2.1 弗洛伊德(Floyd)算法介绍
1) 和Dijkstra算法一样,弗洛伊德(Floyd)算法也是一种用于寻找给定的加权图中顶点间最短路径的算法。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德命名。
2) 弗洛伊德算法(Floyd)计算图中任意两个顶点之间的最短路径。
3) 迪杰斯特拉算法用于计算图中某一个顶点到其他顶点的最短路径。
4) 弗洛伊德算法 VS 迪杰斯特拉算法:迪杰斯特拉算法通过选定的被访问顶点,求出从出发访问顶点到其他顶点的最短路径;弗洛伊德算法中每一个顶点都是出发访问点,所以需要将每一个顶点看做被访问顶点,求出从每一个顶点到其他顶点的最短路径。
7.2.2 弗洛伊德(Floyd)算法图解分析
1) 设置顶点vi到顶点vk的最短路径已知为Lik,顶点vk到vj的最短路径已知为Lkj,顶点vi到vj的路径为Lij,则vi到vj的最短路径为:min((Lik+Lkj),Lij),vk的取值为图中所有顶点,则可获得vi到vj的最短路径
2) 至于vi到vk的最短路径Lik或者vk到vj的最短路径Lkj,是以同样的方式获得
3) 弗洛伊德(Floyd)算法图解分析-举例说明
7.2.3 弗洛伊德(Floyd)算法最佳应用-最短路径
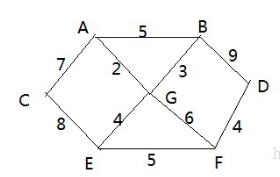
胜利乡有7个村庄(A, B, C, D, E, F, G),各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里。问:如何计算出各村庄到 其它各村庄的最短距离?
图解:

/**
*
* 弗洛伊德算法
*/
public class FloydAlgorithm {
public static void main(String[] args) {
// 测试看看图是否创建成功
char[] vertex = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
//创建邻接矩阵
int[][] matrix = new int[vertex.length][vertex.length];
final int N = 65535;
matrix[0] = new int[]{0, 5, 7, N, N, N, 2};
matrix[1] = new int[]{5, 0, N, 9, N, N, 3};
matrix[2] = new int[]{7, N, 0, N, 8, N, N};
matrix[3] = new int[]{N, 9, N, 0, N, 4, N};
matrix[4] = new int[]{N, N, 8, N, 0, 5, 4};
matrix[5] = new int[]{N, N, N, 4, 5, 0, 6};
matrix[6] = new int[]{2, 3, N, N, 4, 6, 0};
//创建 Graph 对象
Graph graph = new Graph(vertex.length, matrix, vertex);
//调用弗洛伊德算法
graph.floyd();
graph.show();
}
}
// 创建图
class Graph {
private char[] vertex; // 存放顶点的数组
private int[][] dis; // 保存,从各个顶点出发到其它顶点的距离,最后的结果,也是保留在该数组
private int[][] pre;// 保存到达目标顶点的前驱顶点
// 构造器
/**
* @param length 大小
* @param matrix 邻接矩阵
* @param vertex 顶点数组
*/
public Graph(int length, int[][] matrix, char[] vertex) {
this.vertex = vertex;
this.dis = matrix;
this.pre = new int[length][length];
// 对pre数组初始化, 注意存放的是前驱顶点的下标
for (int i = 0; i < length; i++) {
Arrays.fill(pre[i], i);
}
}
// 显示pre数组和dis数组
public void show() {
//为了显示便于阅读,我们优化一下输出
char[] vertex = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
for (int k = 0; k < dis.length; k++) {
// 先将pre数组输出的一行
for (int i = 0; i < dis.length; i++) {
System.out.print(vertex[pre[k][i]] + " ");
}
System.out.println();
// 输出dis数组的一行数据
for (int i = 0; i < dis.length; i++) {
System.out.print("(" + vertex[k] + "到" + vertex[i] + "的最短路径是" + dis[k][i] + ") ");
}
System.out.println();
System.out.println();
}
}
//弗洛伊德算法, 比较容易理解,而且容易实现
public void floyd() {
int len = 0; //变量保存距离
//对中间顶点遍历, k 就是中间顶点的下标 [A, B, C, D, E, F, G]
for (int k = 0; k < dis.length; k++) { //
//从i顶点开始出发 [A, B, C, D, E, F, G]
for (int i = 0; i < dis.length; i++) {
//到达j顶点 // [A, B, C, D, E, F, G]
for (int j = 0; j < dis.length; j++) {
len = dis[i][k] + dis[k][j]; // => 求出从i 顶点出发,经过 k中间顶点,到达 j 顶点距离
if (len < dis[i][j]) { //如果len小于 dis[i][j]
dis[i][j] = len; //更新距离
pre[i][j] = pre[k][j]; //更新前驱顶点
}
}
}
}
}
}Output:
A A A F G G A
(A到A的最短路径是0) (A到B的最短路径是5) (A到C的最短路径是7) (A到D的最短路径是12) (A到E的最短路径是6) (A到F的最短路径是8) (A到G的最短路径是2)
B B A B G G B
(B到A的最短路径是5) (B到B的最短路径是0) (B到C的最短路径是12) (B到D的最短路径是9) (B到E的最短路径是7) (B到F的最短路径是9) (B到G的最短路径是3)
C A C F C E A
(C到A的最短路径是7) (C到B的最短路径是12) (C到C的最短路径是0) (C到D的最短路径是17) (C到E的最短路径是8) (C到F的最短路径是13) (C到G的最短路径是9)
G D E D F D F
(D到A的最短路径是12) (D到B的最短路径是9) (D到C的最短路径是17) (D到D的最短路径是0) (D到E的最短路径是9) (D到F的最短路径是4) (D到G的最短路径是10)
G G E F E E E
(E到A的最短路径是6) (E到B的最短路径是7) (E到C的最短路径是8) (E到D的最短路径是9) (E到E的最短路径是0) (E到F的最短路径是5) (E到G的最短路径是4)
G G E F F F F
(F到A的最短路径是8) (F到B的最短路径是9) (F到C的最短路径是13) (F到D的最短路径是4) (F到E的最短路径是5) (F到F的最短路径是0) (F到G的最短路径是6)
G G A F G G G
(G到A的最短路径是2) (G到B的最短路径是3) (G到C的最短路径是9) (G到D的最短路径是10) (G到E的最短路径是4) (G到F的最短路径是6) (G到G的最短路径是0) 