目录
1、Prometheus Operator 介绍
我们知道 Prometheus 是一套开源的系统监控、报警、时间序列数据库的组合,而 Prometheus Operator 是 CoreOS 开源的一套用于管理在 Kubernetes 集群上的 Prometheus 控制器,它是为了简化在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群。
Prometheus Operator 架构图如下:

以上架构中的各组成部分以不同的资源方式运行在 Kubernetes 集群中,它们各自有不同的作用:
- Operator: Operator 资源会根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus: Prometheus 资源是声明性地描述 Prometheus 部署的期望状态。
- Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor: ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
- Service: Service 资源主要用来对应 Kubernetes 集群中的 Metrics Server Pod,来提供给 ServiceMonitor 选取让 Prometheus Server 来获取信息。简单的说就是 Prometheus 监控的对象,例如之前了解的 Node Exporter Service、Mysql Exporter Service 等等。
- Alertmanager: Alertmanager 也是一个自定义资源类型,由 Operator 根据资源描述内容来部署 Alertmanager 集群。
2、环境、软件准备
本次演示环境,我是在本机 MAC OS 上操作,以下是安装的软件及版本:
- Docker: 17.09.0-ce
- Oracle VirtualBox: 5.1.20 r114628 (Qt5.6.2)
- Minikube: v0.28.2
- Helm: v2.8.0
- Kubernetes: v1.10.0
- Kubectl:
- Client Version: v1.10.0
- Server Version: v1.10.0
注意:这里 Kubernetes 集群搭建使用 Minikube 来完成,Minikube 启动的单节点 k8s Node 实例是需要运行在本机的 VM 虚拟机里面,所以需要提前安装好 VM,这里我选择 Oracle VirtualBox。k8s 运行底层使用 Docker 容器,所以本机需要安装好 Docker 环境,这里忽略 Docker、VirtualBox 的安装过程,着重介绍下 Minikube、Prometheus Operator 的安装。
3、相关镜像准备
开始之前,我们要先着重说下镜像问题,国内网的问题确实很坑,这也是导致后续一系列操作异常不断的原因,所以,有必要先把相关依赖的镜像下载到 Minikube 内,具体依赖的镜像分两类,一类是 Kubernetes 依赖镜像,一类是 Prometheus Operator 部署依赖镜像。
| Type | REPOSITORY | TAG | Required(*) |
|---|---|---|---|
| prometheus-operator | grafana/grafana | 5.1.1 | * |
| prometheus-operator | prom/prometheus | v2.2.1 | * |
| prometheus-operator | quay.io/prometheus/prometheus | v2.2.1 | * |
| prometheus-operator | quay.io/prometheus/node-exporter | v0.16.0-rc.3 | * |
| prometheus-operator | quay.io/prometheus/alertmanager | v0.15.0-rc.1 | * |
| prometheus-operator | quay.io/coreos/prometheus-operator | v0.19.0 | * |
| prometheus-operator | quay.io/coreos/prometheus-config-reloader | v0.0.4 | * |
| prometheus-operator | quay.io/coreos/grafana-watcher | v0.0.8 | * |
| prometheus-operator | quay.io/coreos/configmap-reload | v0.0.1 | * |
| prometheus-operator | k8s.gcr.io/kube-state-metrics | v1.3.1 | * |
| prometheus-operator | k8s.gcr.io/addon-resizer | 1.7 | * |
| kubernetes | k8s.gcr.io/pause-amd64 | 3.1 | * |
| kubernetes | k8s.gcr.io/kube-proxy-amd64 | v1.10.0 | * |
| kubernetes | k8s.gcr.io/kube-controller-manager-amd64 | v1.10.0 | * |
| kubernetes | k8s.gcr.io/kube-scheduler-amd64 | v1.10.0 | * |
| kubernetes | k8s.gcr.io/kube-apiserver-amd64 | v1.10.0 | * |
| kubernetes | k8s.gcr.io/etcd-amd64 | 3.1.12 | * |
| kubernetes | k8s.gcr.io/kube-addon-manager | v8.6 | * |
| kubernetes | k8s.gcr.io/k8s-dns-dnsmasq-nanny-amd64 | 1.14.8 | * |
| kubernetes | k8s.gcr.io/k8s-dns-sidecar-amd64 | 1.14.8 | * |
| kubernetes | k8s.gcr.io/k8s-dns-kube-dns-amd64 | 1.14.8 | * |
| kubernetes | k8s.gcr.io/kubernetes-dashboard-amd64 | v1.8.1 | |
| kubernetes | k8s.gcr.io/defaultbackend | 1.4 | |
| kubernetes | quay.io/kubernetes-ingress-controller/nginx-ingress-controller | 0.16.2 | |
| kubernetes | gcr.io/kubernetes-helm/tiller | v2.8.0 |
以上所依赖的镜像版本中,Kubernetes 相关镜像对应 Minikube 版本为 v0.28.2,默认安装 Kubernetes 版本为 v1.10.0,prometheus-operator 相关镜像对应版本为 2.0.5。那么如何下载以上各镜像呢?
附个福利吧!以上镜像,我都已经通过 DockerHub 官网中 “Create Automated Build” 功能中的 “Create Auto-build Github”,关联自己的 GitHub 项目,来执行自动构建,将生成的指定 Docker Image 镜像上传到 DockerHub 上,我们只需要在本地 Minikube 中下载以上镜像,修改镜像名称即可。
# 举个栗子,只需获取镜像最后一层和 tag,其他部分修改为 huwanyang168/ 开头即可。
$ docker pull huwanyang168/kube-state-metrics:v1.3.1
$ docker tag huwanyang168/kube-state-metrics:v1.3.1 k8s.gcr.io/kube-state-metrics:v1.3.1
......
$ docker pull huwanyang168/prometheus-operator:v0.19.0
$ docker tag huwanyang168/prometheus-operator:v0.19.0 quay.io/coreos/prometheus-operator:v0.19.04、Minikube 升级并配置
踩个坑先!本地原 Minikube 版本比较老为 v0.22.2, 默认安装 Kubernetes 版本为 v1.7.5,直接执行下边 Prometheus Operator 部署时,发现有些服务死活启动不起来,各种日志分析和源码查看,最终确认是版本不匹配!!!最后在 GitHub Prometheus Operator Doc 文档中看到版本说明,Prometheus Operator 版本 >=0.18.0 需要依赖 Kubernetes 版本 >=1.8.0。好吧,看来在操作前还是得好好看看文档的哈!
既然版本太低了,那就果断升级到最新版吧!当前 Minikube 最新版为 v0.28.2
4.1、Minikube 升级
Mac OS 系统安装之前,先干掉之前老版本 Minikube。
$ minikube stop
$ minikube delete
$ sudo rm -f /usr/local/bin/minikube然后下载最新版二进制文件安装。
$ curl -Lo minikube https://storage.googleapis.com/minikube/releases/v0.28.2/minikube-darwin-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
# 如果网络问题下载不了,可以在 Github 上下载。
$ curl -Lo minikube https://github.com/kubernetes/minikube/releases/download/v0.28.2/minikube-darwin-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/当然,也可以直接 brew cask install minikube 安装。
4.2、Kubectl 升级
因为我们 Minikube 已经是最新版了,默认安装的 Kubernetes 版本为 v1.10.0,那么为了避免兼容性问题,将本地 kubectl 工具也升级到最新版 v1.11.1 吧!我使用 brew 升级,当然也可以下载最新版二进制文件替换。
$ brew upgrade kubectl安装完毕,通过 kubectl version 查看下是否安装成功。
4.3、Kubernetes 集群创建
接下来启动 Minikube 将自动创建 Kubernetes 集群,该版本 Minikube 默认安装 Kubernetes 版本为 v1.10.0,当然也可以指定版本、指定资源大小、指定虚拟机类型等等。
# 使用默认的配置创建 Kubernetes 集群
$ minikube start --vm-driver=virtualbox --registry-mirror=https://registry.docker-cn.com说明一下: --vm-driver 指定虚拟机类型,当然如果本机只有一种类型虚拟机,也可以不指定,它会自动查找,--registry-mirror 这个最好加上,国内网络很蛋疼。当然也可以指定其他参数,例如:minikube start --kubernetes-version=v1.10.0 --memory=4096 --cpu=4 --disk-size=51200MB --extra-config=apiserver.Authorization.Mode=RBAC 这里就指定了 Kubernetes 版本,指定了内存、CPU、磁盘资源,指定额外配置开启 RBAC 认证。这里要说下该版本默认开启了 RBAC 认证,所以,如果我们部署什么资源的时候,也需要额外配置一下 RBAC 信息,下边使用默认 Ingress 时就遇到坑。
稍等一会,下载完所需要的安装包以后,服务就可以启动起来啦!(友情提示:记得提前把需要的 Images 下载到 Minikube 里面哈!)
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-minikube 1/1 Running 0 1d
kube-system kube-addon-manager-minikube 1/1 Running 1 1d
kube-system kube-apiserver-minikube 1/1 Running 0 1d
kube-system kube-controller-manager-minikube 1/1 Running 0 1d
kube-system kube-dns-86f4d74b45-7qz78 3/3 Running 0 1d
kube-system kube-proxy-grft7 1/1 Running 0 1d
kube-system kube-scheduler-minikube 1/1 Running 0 1d5、Prometheus Operator 部署
Kubernetes 集群部署完毕之后,我们就可以开始执行 Prometheus Operator 部署了。 通过 coreos/prometheus-operator 文档说明,可以很方便执行 Prometheus OPerator 部署,不过这里我暂时不使用 Coreos 版本,而是使用 camilb/prometheus-kubernetes 这个项目,该项目也是依赖 CoreOS Prometheus OPerator,并在其基础上做了部分修改,使得我们部署起来非常方便。
首先获取该项目最新版代码:
$ git clone https://github.com/camilb/prometheus-kubernetes.git
$ cd prometheus-kubernetes接着执行提供的 deploy 脚本来部署到 Kubernetes 集群中:
$ ./deploy
Check for uncommitted changes
Creating 'monitoring' namespace.
Error from server (AlreadyExists): namespaces "monitoring" already exists
1) AWS
2) GCP
3) Azure
4) Custom
Please select your cloud provider:4
Deploying on custom providers without persistence
Setting components version
Enter Prometheus Operator version [v0.19.0]:
Enter Prometheus version [v2.2.1]:
Enter Prometheus storage retention period in hours [168h]:
Enter Prometheus storage volume size [40Gi]: 20Gi
Enter Prometheus memory request in Gi or Mi [1Gi]:
Enter Grafana version [5.1.1]:
Enter Alert Manager version [v0.15.0-rc.1]:
Enter Node Exporter version [v0.16.0-rc.3]:
Enter Kube State Metrics version [v1.3.1]:
Enter Prometheus external Url [http://127.0.0.1:9090]:
Enter Alertmanager external Url [http://127.0.0.1:9093]:
Do you want to use NodeSelector to assign monitoring components on dedicated nodes?
Y/N [N]:
Do you want to set up an SMTP relay?
Y/N [N]:
Do you want to set up slack alerts?
Y/N [N]:
Removing all the sed generated files
Deploying Prometheus Operator
serviceaccount/prometheus-operator created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
service/prometheus-operator created
deployment.apps/prometheus-operator created
Waiting for Operator to register custom resource definitions.....done!
Deploying Alertmanager
secret/alertmanager-main created
service/alertmanager-main created
alertmanager.monitoring.coreos.com/main created
Deploying node-exporter
daemonset.extensions/node-exporter created
service/node-exporter created
Deploying Kube State Metrics exporter
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
role.rbac.authorization.k8s.io/kube-state-metrics-resizer created
rolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
service/kube-state-metrics created
Deploying Grafana
Enter Grafana administrator username [admin]: admin
Enter Grafana administrator password: **************
secret/grafana-credentials created
configmap/grafana-dashboards created
deployment.apps/grafana created
service/grafana created
Deploying Prometheus
serviceaccount/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
configmap/prometheus-k8s-rules created
servicemonitor.monitoring.coreos.com/alertmanager created
servicemonitor.monitoring.coreos.com/kube-dns created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kubelet created
servicemonitor.monitoring.coreos.com/node-exporter created
servicemonitor.monitoring.coreos.com/prometheus-operator created
servicemonitor.monitoring.coreos.com/prometheus created
service/prometheus-k8s created
prometheus.monitoring.coreos.com/k8s created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
Self hosted
service/kube-controller-manager-prometheus-discovery created
service/kube-dns-prometheus-discovery created
service/kube-scheduler-prometheus-discovery created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
Removing local changes
Done简单说下,该 deploy 提供了交互性脚本,其中 provider 处可以有 AWS、GCP、Azure、Custom 四种类型可选,因为我们使用本地 Kubernetes 集群,因此选择 Custom 4 类型;镜像选择部分,使用指定版本即可;Grafana administrator 用户名和密码,需要设置一下,这也是后边使用 Grafana 默认管理员密码,其他部分也先一路默认即可。再次强调一下,一定提前下载好所需镜像。
通过日志显示,我们可以看到 Prometheus Operator 部署的几个资源,例如:alertmanager、grafana、kube-state-metrics、node-exporter、prometheus、prometheus-operator等。这里头有上边架构里面提到的自定义资源(Custom Resource Definition / CRDs)
例如 alertmanager-main 指定的资源类型为 Alertmanager
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: main
labels:
alertmanager: main
...... prometheus-k8s 指定的资源类型为 Prometheus
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: k8s
labels:
prometheus: k8s
...... 各服务监控资源类型 ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: kube-dns
labels:
k8s-app: kube-dns
......那么,到底什么是 CRD 呢?在 Kubernetes 中一切都可视为资源,Kubernetes 1.7 之后增加了对 CRD 自定义资源二次开发能力来扩展 Kubernetes API,通过 CRD 我们可以向 Kubernetes API 中增加新资源类型,而不需要修改 Kubernetes 源码或创建自定义的 API server,该功能大大提高了 Kubernetes 的扩展能力。具体如何实现,这里就不在说了,可以参考 Kubernetes 官网文档 Extend the Kubernetes API with CustomResourceDefinitions 以及 Demo sample-controller with CRD 示例。
我们可以查看下 Prometheus Operator 所创建的 CRD 资源都有哪些。
$ kubectl get crd
NAME CREATED AT
alertmanagers.monitoring.coreos.com 2018-08-09T02:55:16Z
prometheuses.monitoring.coreos.com 2018-08-09T02:55:16Z
servicemonitors.monitoring.coreos.com 2018-08-09T02:55:16Z
$ kubectl get ServiceMonitor -n monitoring
NAME CREATED AT
alertmanager 1h
kube-apiserver 1h
kube-controller-manager 1h
kube-dns 1h
kube-scheduler 1h
kube-state-metrics 1h
kubelet 1h
node-exporter 1h
prometheus 1h
prometheus-operator 1h最终,各个服务部署启动完毕之后,通过 Kubectl 命令查看下 monitoring 命名空间下的 Pod 和 Service。
$ kubectl get pods -n monitoring
NAMESPACE NAME READY STATUS RESTARTS AGE
monitoring alertmanager-main-0 2/2 Running 0 52m
monitoring alertmanager-main-1 2/2 Running 0 51m
monitoring alertmanager-main-2 2/2 Running 0 51m
monitoring grafana-568b569696-wxlxz 2/2 Running 0 51m
monitoring kube-state-metrics-9977d88d8-p99wt 2/2 Running 0 45m
monitoring node-exporter-kckr5 1/1 Running 0 52m
monitoring prometheus-k8s-0 2/2 Running 0 51m
monitoring prometheus-k8s-1 2/2 Running 0 51m
monitoring prometheus-operator-f596c68cf-8xblq 1/1 Running 0 52m
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.109.10.5 <none> 9093/TCP 52m
alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 52m
grafana ClusterIP 10.106.93.254 <none> 3000/TCP 52m
kube-state-metrics ClusterIP 10.107.82.174 <none> 8080/TCP 52m
node-exporter ClusterIP None <none> 9100/TCP 52m
prometheus-k8s ClusterIP 10.107.161.100 <none> 9090/TCP 52m
prometheus-operated ClusterIP None <none> 9090/TCP 52m
prometheus-operator ClusterIP 10.106.114.242 <none> 8080/TCP 52m6、使用 Grafana 体验 Kubernetes 集群监控
好了,服务都正常启动起来了,接下来,我们就可以使用 Grafana 来体验一下 Kubernetes 集群监控。有三种方式来使用 Grafana 查看 Kubernetes Metric 信息。
6.1、使用 kubectl port-forward 转发
因为我们 Kubernetes 集群安装在本地 Minikube 里,所以可以通过使用 kubectl port-forward 将本地端口转发到 Pod 上。例如,将本地 3000 端口转发到 Grafana Pod 的 3000 端口上。
$ POD=$(kubectl get pods --namespace=monitoring | grep grafana| cut -d ' ' -f 1)
$ kubectl port-forward $POD --namespace=monitoring 3000:3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000]
Handling connection for 3000
......此时,我们本地浏览器访问 http://127.0.0.1:3000 即可查看 Grafana 对 Kubernetes 集群各个指标的监控信息了,例如:Node、Pod、Deployment、Kubernetes Health等等指标。
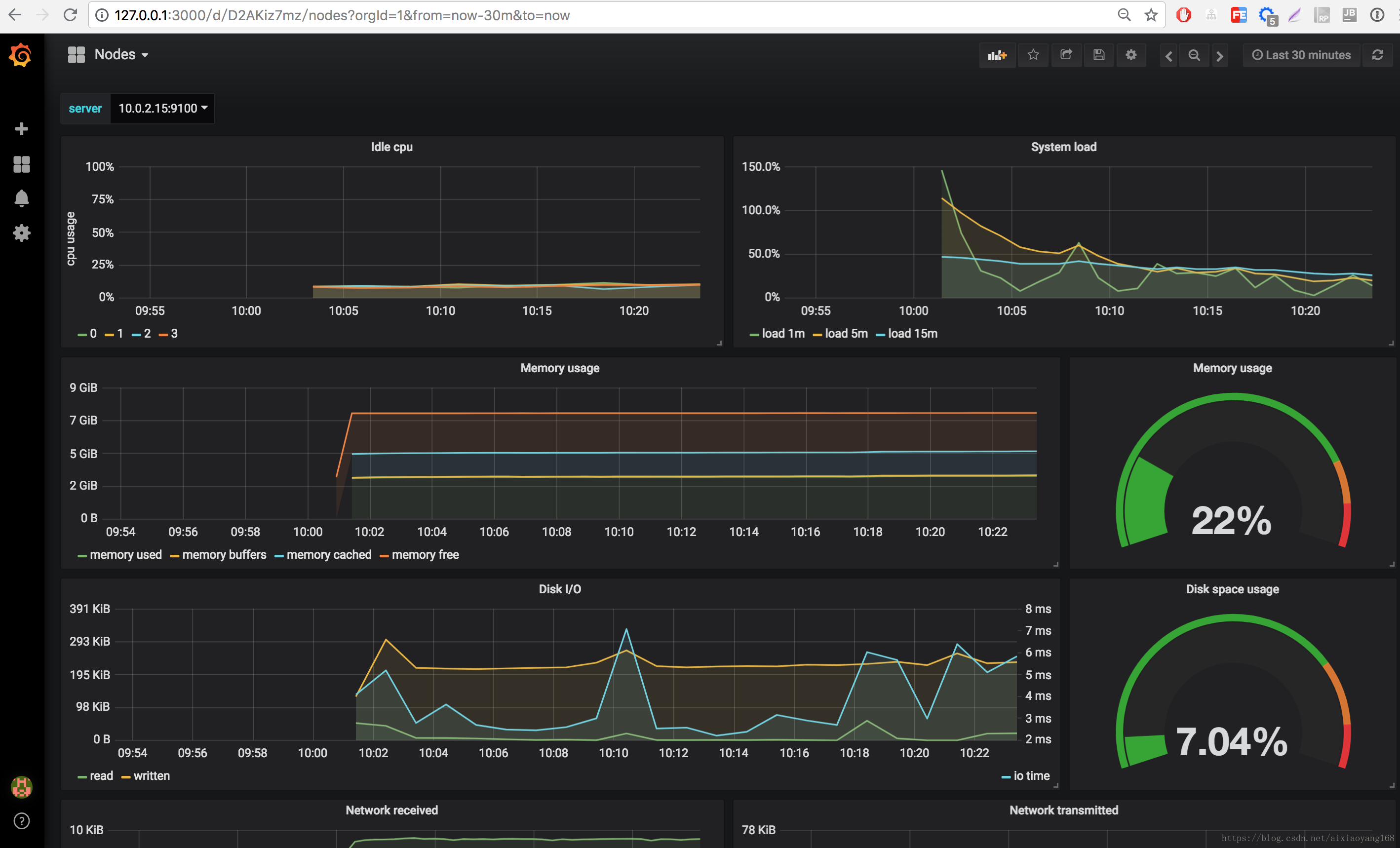
该版本默认配置的监控 Dashboards 如下,当然,我们也可以自己添加各种监控 Dashboards 的哈。
同理,我们也可以将 Prometheus、Alertmanager Pod 也使用本地端口转发,本来浏览器即可访问。
$ POD=$(kubectl get pods --namespace=monitoring | grep prometheus-k8s-0| cut -d ' ' -f 1)
$ kubectl port-forward $POD --namespace=monitoring 9090:9090
Forwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
Handling connection for 9090
......本地浏览器访问 http://127.0.0.1:9090 即可查看 Prometheus 默认 UI 页面,跟上一篇文章 初试 Prometheus + Grafana 监控系统搭建并监控 Mysql 看到的页面是一样一样的,不过,这里的 Prometheus 配置了更多的跟 Kubernetes 相关的 Targets 、Service Discovery 以及 Alerts。
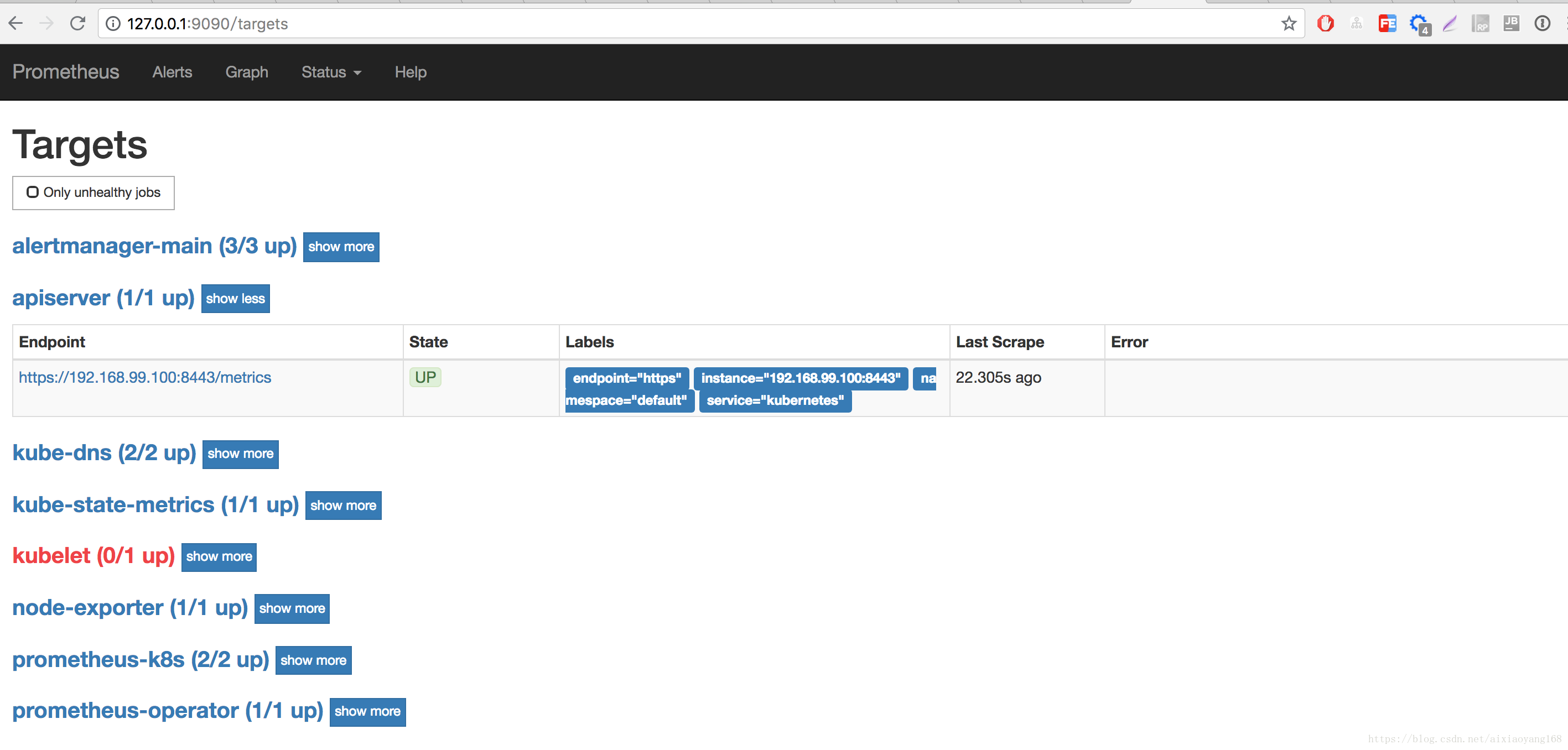
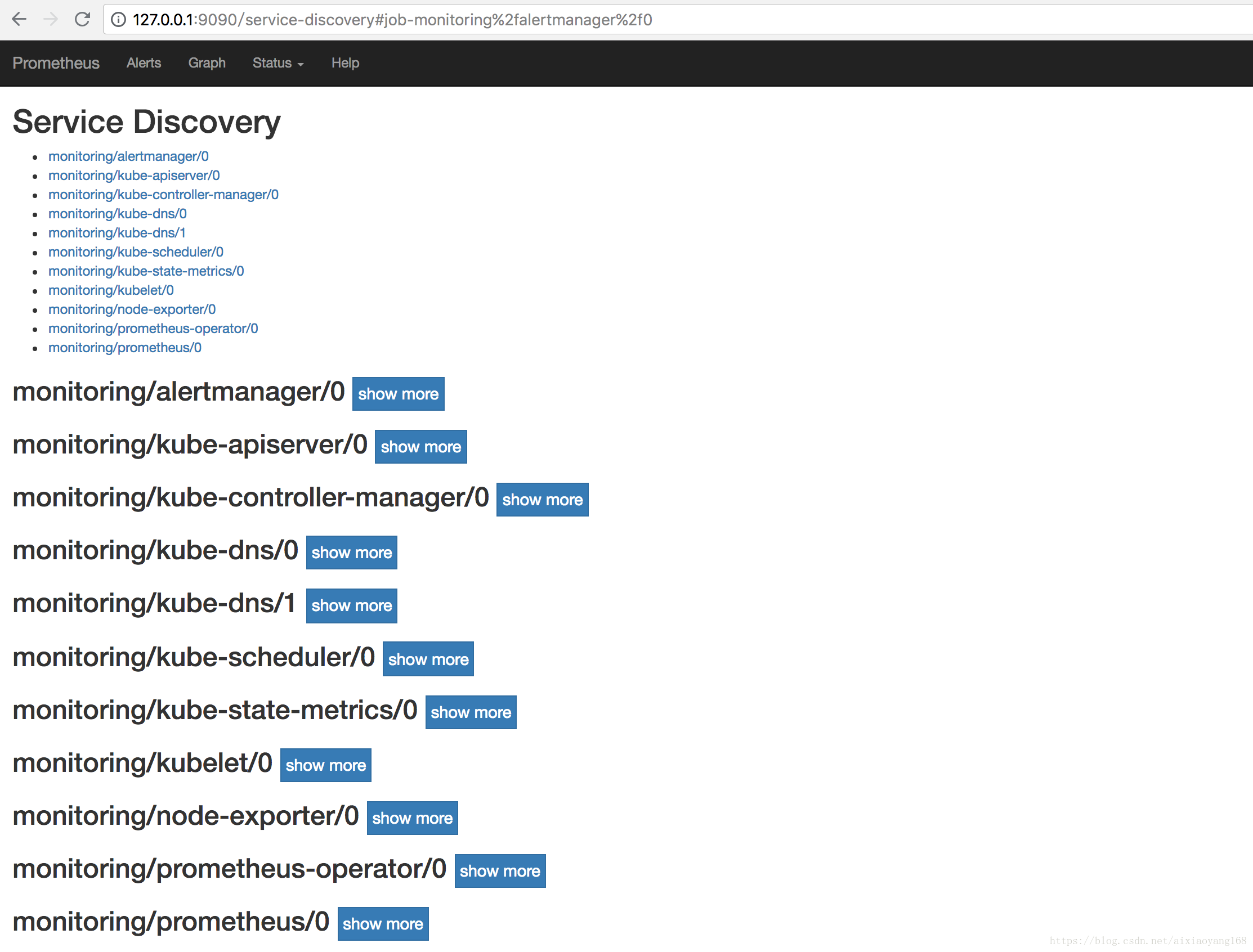
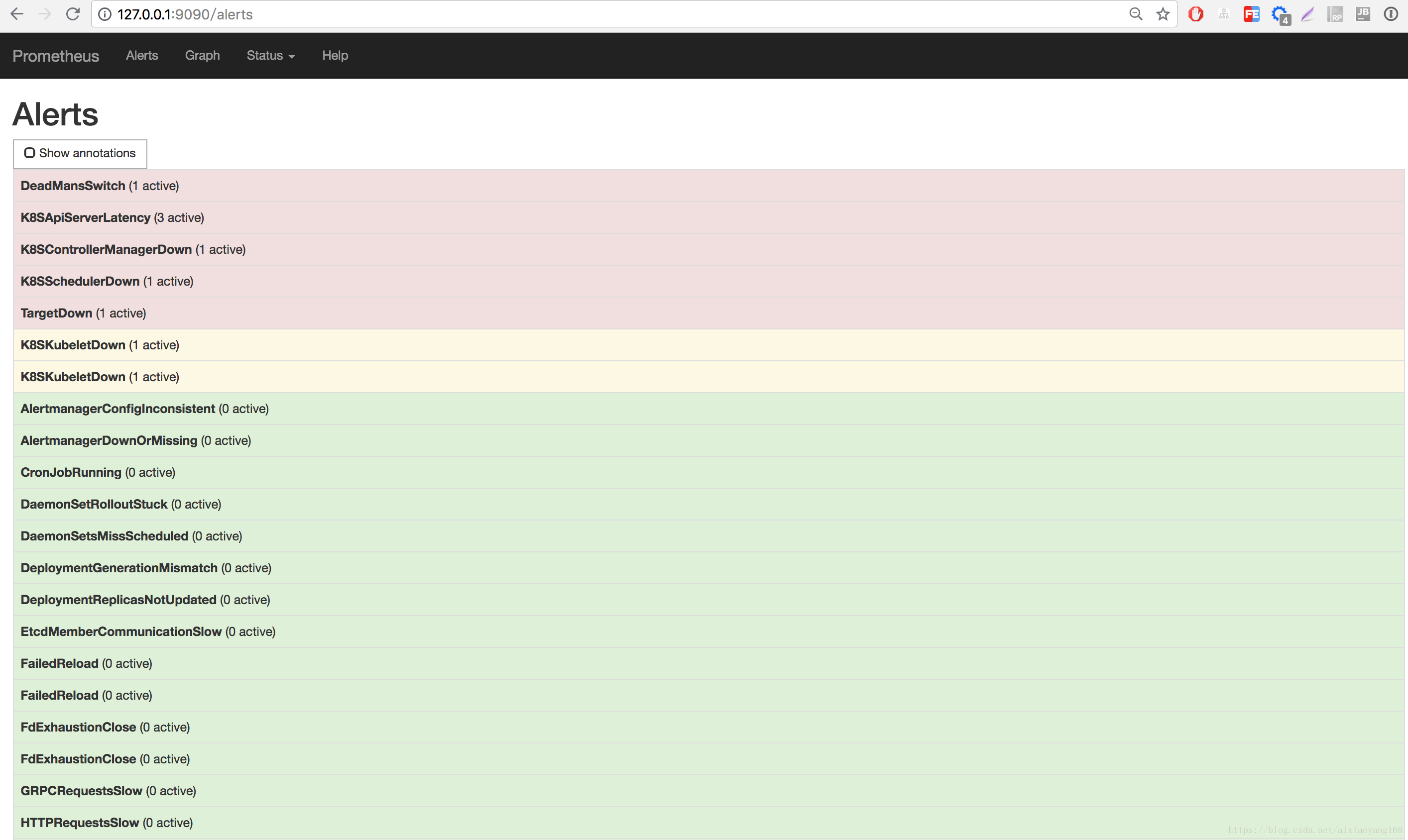
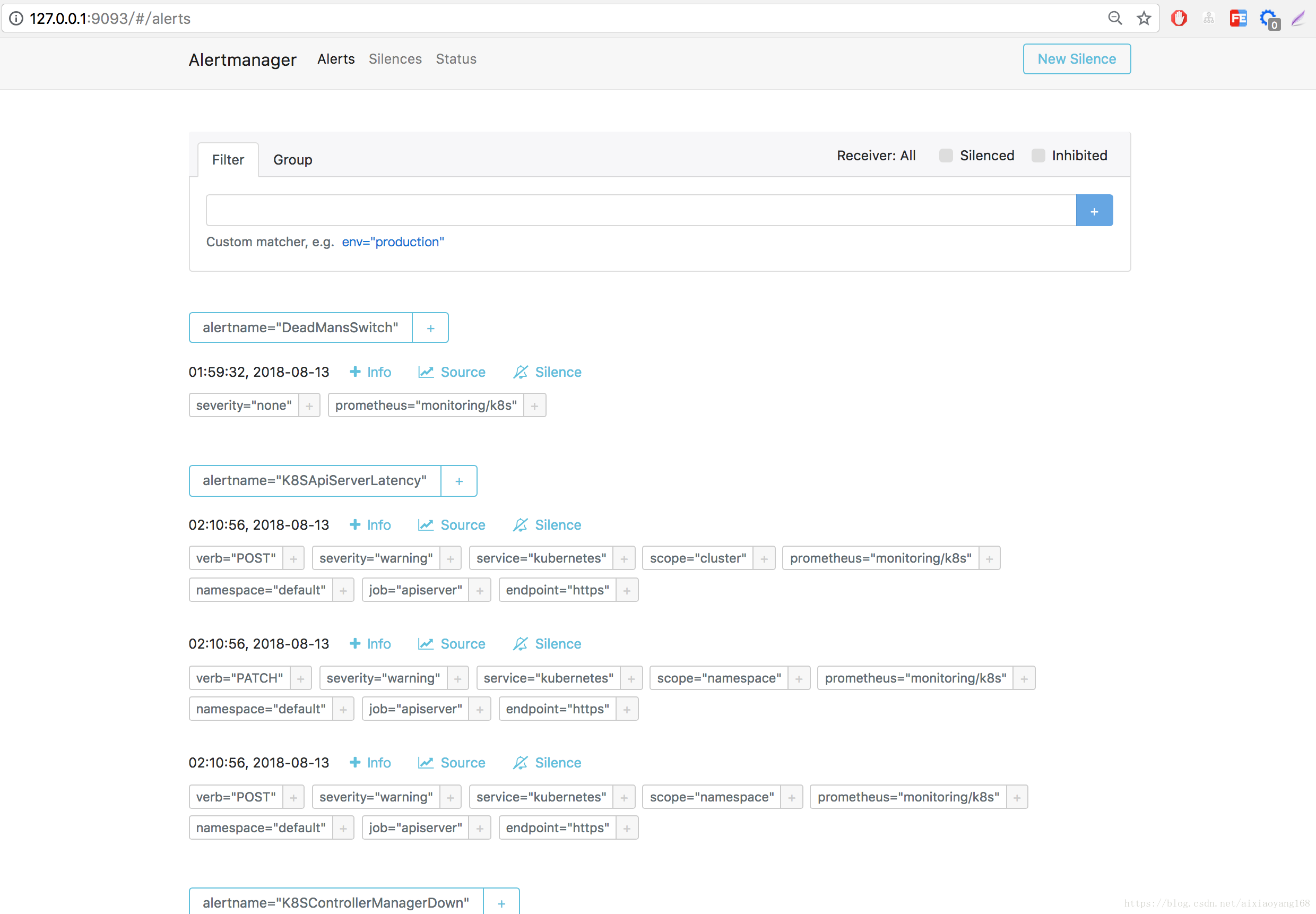
将本地 9093 端口转发到 Alertmanager Pod 9093 端口,然后本地浏览器访问 http://127.0.0.1:9093 查看 Alertmanager 默认 UI 页面。
$ POD=$(kubectl get pods --namespace=monitoring | grep alertmanager-main-0| cut -d ' ' -f 1)
$ kubectl port-forward $POD --namespace=monitoring 9093:9093
Forwarding from 127.0.0.1:9093 -> 9093
Forwarding from [::1]:9093 -> 9093
Handling connection for 9093
......
6.2、修改 Service Type 类型为 NodePort
通过上边 kubectl get svc -n monitoring 输出可以看出,默认服务类型都是 ClusterIP,而该种方式,我们没法再集群外部访问的到。因此,我们可以将其 Service Type 类型修改为 NodePort,那么就可以通过暴漏服务端口,从而本地来访问了。
$ kubectl edit svc grafana -n monitoring
......
spec:
clusterIP: 10.106.93.254
externalTrafficPolicy: Cluster
ports:
- nodePort: 30077
port: 3000
protocol: TCP
targetPort: web
selector:
app: grafana
sessionAffinity: None
type: NodePort # 这里将 ClusterIP 修改为 NodePort
status:
loadBalancer: {}此时,我们浏览器访问 http://192.168.99.100:30077/ 即可 Grafana 默认 UI 页面啦!
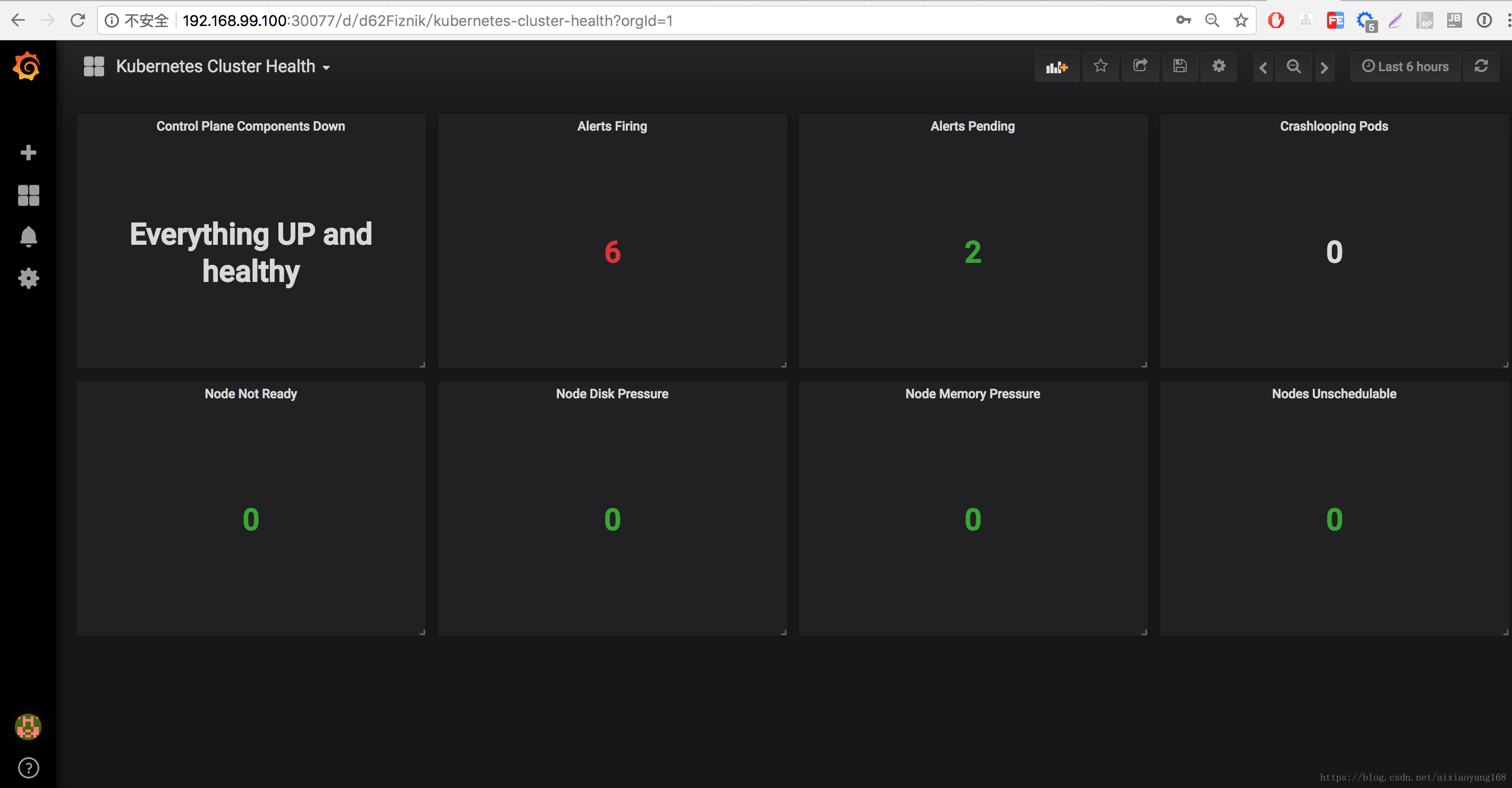
同理,也可以修改 prometheus-k8s、alertmanager-main Service Type,从而实现本地访问,这里就不再演示了。修改完毕,获得 service 信息如下:
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.109.10.5 <none> 9093:31121/TCP 1h
alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 1h
grafana NodePort 10.106.93.254 <none> 3000:30077/TCP 1h
kube-state-metrics ClusterIP 10.107.82.174 <none> 8080/TCP 1h
node-exporter ClusterIP None <none> 9100/TCP 1h
prometheus-k8s NodePort 10.107.161.100 <none> 9090:32550/TCP 1h
prometheus-operated ClusterIP None <none> 9090/TCP 1h
prometheus-operator ClusterIP 10.106.114.242 <none> 8080/TCP 1h6.3、通过 Ingress 来暴漏服务
使用 Ingress 反向代理负载均衡器来实现对外暴漏服务,这种方式是最常用的了,之前我也有介绍 初试 Kubernetes 暴漏服务类型之 Nginx Ingress 以及在 Kubernetes 集群使用 Helm 搭建 GitLab 并配置 Ingress 文章中也有使用。所以,这里我们也可以这么操作。
使用 Minikube addons 开启自带的 Ingress 服务,非常方便,然而这里有个小坑哈。
$ minkube addons enable ingress
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system default-http-backend-59868b7dd6-fqxmm 0/1 ImagePullBackOff 0 3m
kube-system nginx-ingress-controller-5984b97644-2g5nk 0/1 ImagePullBackOff 0 3m镜像下载失败,那还是用老办法处理下,下载依赖的镜像,然后修改名称。
$ docker pull huwanyang168/defaultbackend:1.4
$ docker tag huwanyang168/defaultbackend:1.4 k8s.gcr.io/defaultbackend:1.4
$ docker pull huwanyang168/nginx-ingress-controller:0.16.2
$ docker tag huwanyang168/nginx-ingress-controller:0.16.2 quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.16.2问题来了,镜像下载完了,nginx-ingress-controller Pod 却启动不起来,查下日志分析下原因
$ kubectl logs pod/nginx-ingress-controller-5984b97644-2g5nk -n kube-system
-------------------------------------------------------------------------------
NGINX Ingress controller
Release: 0.16.2
Build: git-26eacf4
Repository: https://github.com/kubernetes/ingress-nginx
-------------------------------------------------------------------------------
nginx version: nginx/1.13.12
W0809 06:49:03.801527 8 client_config.go:533] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I0809 06:49:03.801841 8 main.go:183] Creating API client for https://10.96.0.1:443
I0809 06:49:03.812867 8 main.go:227] Running in Kubernetes cluster version v1.10 (v1.10.0) - git (clean) commit fc32d2f3698e36b93322a3465f63a14e9f0eaead - platform linux/amd64
F0809 06:49:03.814072 8 main.go:96] ✖ The cluster seems to be running with a restrictive Authorization mode and the Ingress controller does not have the required permissions to operate normally.提示 Ingress controller 缺少认证,大概知道原因了,该版本 Minikube 启动 Kubernetes 默认开启了 RBAC 认证的,而自带部署的 Ingress 却没有配置 RBAC 认证。。。找到原因了,解决方案也很简单,去 Github Ingress-nginx 官网 上下载最新版 yaml 文件安装即可。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
namespace/ingress-nginx created
deployment.extensions/default-http-backend created
service/default-http-backend created
configmap/nginx-configuration created
configmap/tcp-services created
configmap/udp-services created
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole created
role.rbac.authorization.k8s.io/nginx-ingress-role created
rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding created
clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding created
deployment.extensions/nginx-ingress-controller created注意:这里是最新版 ingress-nginx 镜像版本有更新,需要提前下载好对应的镜像。部署完毕后,通过 Kubectl 命令确认下是否正常启动。
$ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
default-http-backend-646c87bcbc-tn7gl 1/1 Running 0 38s
nginx-ingress-controller-6c9fcdf8d9-qdc5m 1/1 Running 0 38sIngress 部署完毕,接下来,我们需要创建下 Ingress 规则,分别针对 grafana、prometheus-k8s、alertmanager-main Service 配置一下。
$ vim my-local-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
namespace: monitoring
name: prometheus-ingress
spec:
rules:
- host: grafana.minikube.com
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000
- host: prometheus.minikube.local.com
http:
paths:
- backend:
serviceName: prometheus-k8s
servicePort: 9090
- host: alertmanager.minikube.local.com
http:
paths:
- backend:
serviceName: alertmanager-main
servicePort: 9093创建 Ingress 规则
$ kubectl create -f my-local-ingress.yaml
ingress.extensions/prometheus-ingress created然后本地绑定下 host 即可访问啦!
$ minikube ip
192.168.99.100
$ echo "192.168.99.100 grafana.minikube.com prometheus.minikube.local.com alertmanager.minikube.local.com" >> /etc/hosts参考资料