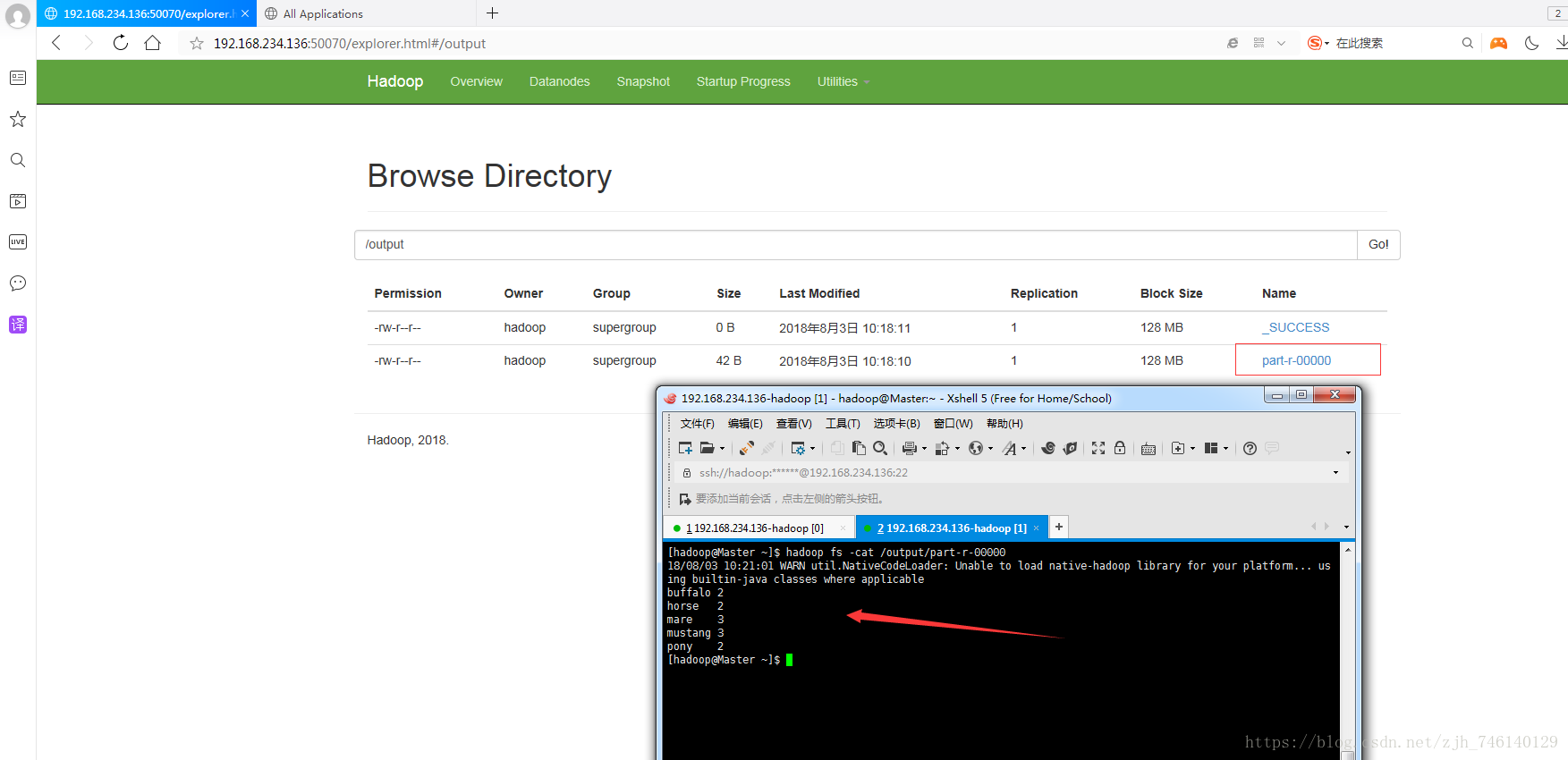
本篇文章主要介绍在idea下使用java API操作mapreduce完成wordcount案例,机器使用的是伪分布式,运行案例时需要启动hadoop
mapreduce流程
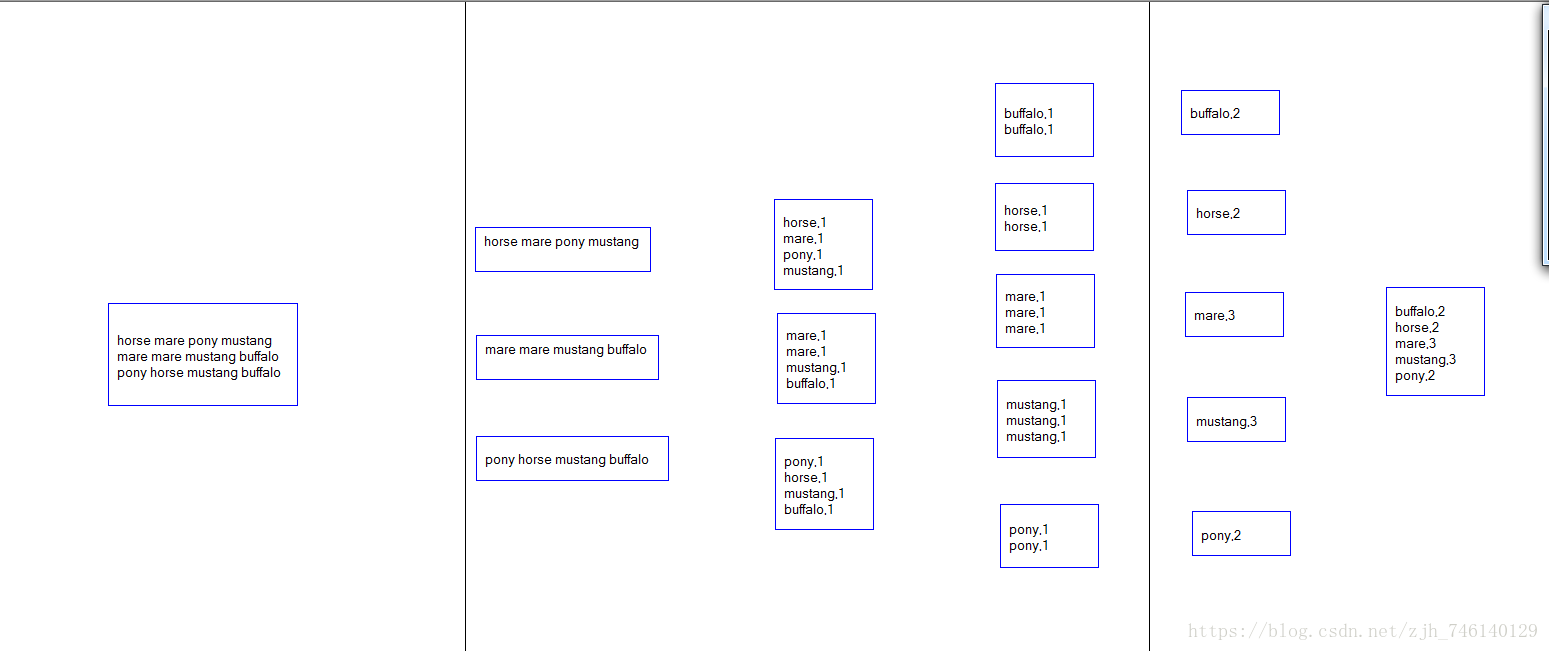
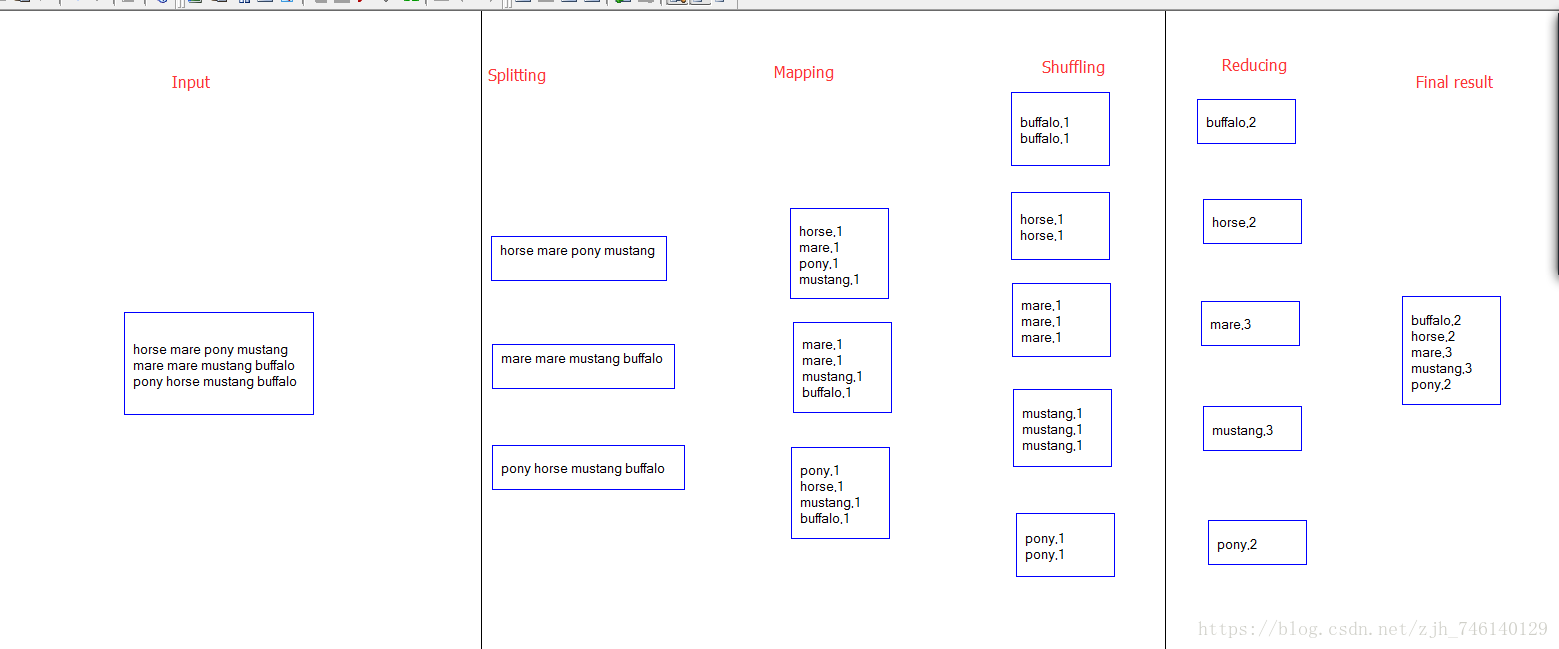
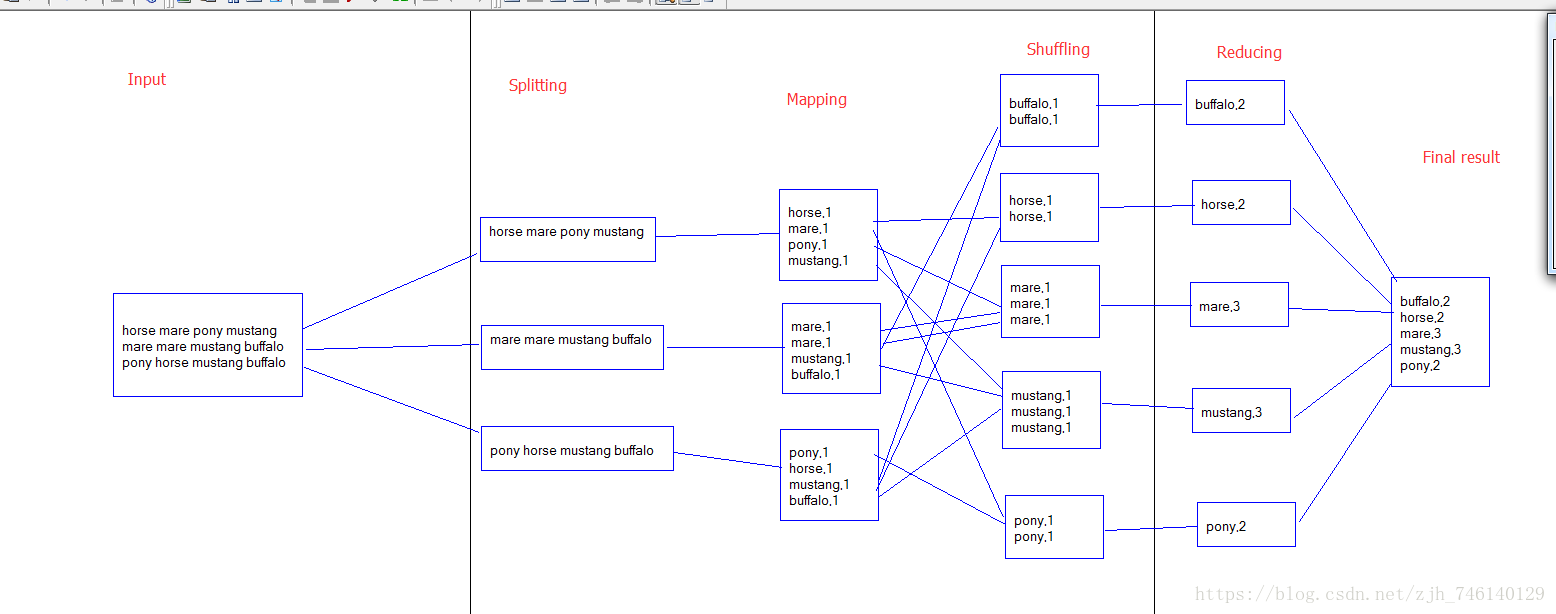
详细步骤
一、准备数据
horse mare pony mustang
mare mare mustang buffalo
pony horse mustang buffalo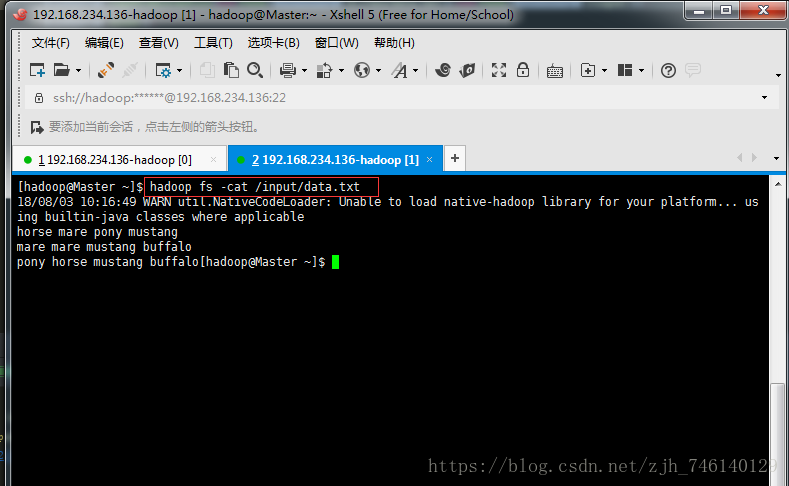
二、代码
package com.mapreduce.two;
/**
* Created by zhoujh on 2018/8/2.
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* 如何设计mapreduce
* 1.使用Hadoop提供的工具类和接口来改善Hadoop任务的设计和提交
* 2.通过集成实现mapper reducer完成wordcount统计业务
* 3.使用maven打包项目并配置作用提交
*/
public class WordCount extends Configured implements Tool {
/**
* map操作 输入的key value
* 输出key value
*/
public static class MyMapper extends Mapper<Object,Text,Text,LongWritable>{
/**
*
* @param key 是一个long类型的整数表示偏移量
* @param value 是数据中的一行
* @param context hadoop上下文对象用这个对象输出数据,key --> value
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" "); //将一行数据按空格分割成每个单词
for (String word :
words) {
context.write(new Text(word),new LongWritable(1)); //利用上下文对象将单词和次数作为key->value输出
}
}
}
/**
* 汇总操作 输出
* 输入是map输出后根据key进行洗牌后的结果
* key表示map输出的key value表示map输出后根据相同可以洗到一期的数据是一个可迭代的对象数据
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value :
values) {
sum +=value.get(); //循环迭代values 并累加
}
context.write(key,new LongWritable(sum)); //输出 key 和 value(累加结果)
}
}
public int run(String[] args) throws Exception {
Configuration cfg = getConf();
Job job = Job.getInstance(cfg); // 根据Hadoop配置信息创建job
job.setJarByClass(WordCount.class); //设置job的主类 main method
job.setMapperClass(MyMapper.class); //设置map task
job.setReducerClass(MyReducer.class);//设置reduce task
job.setOutputKeyClass(Text.class); //key输出类型
job.setOutputValueClass(LongWritable.class);//value的输出类型
FileInputFormat.addInputPath(job,new Path(args[0]));//设置要处理的数据源 路径
FileOutputFormat.setOutputPath(job,new Path(args[1])); //设置结果存放的路基 如果存在报错
// FileInputFormat.addInputPath(job,new Path("/input/data.txt"));//设置要处理的数据源 路径
// FileOutputFormat.setOutputPath(job,new Path("/output")); //设置结果存放的路基 如果存在报错
return job.waitForCompletion(true)?0:1; //启动job并等待完成
}
public static void main(String[] args) throws Exception {
//System.setProperty("hadoop.home.dir", "E:\\Linux\\hadoop-2.7.6");
int n =ToolRunner.run(new WordCount(),args); //利用Hadoop工具类方便任务提交
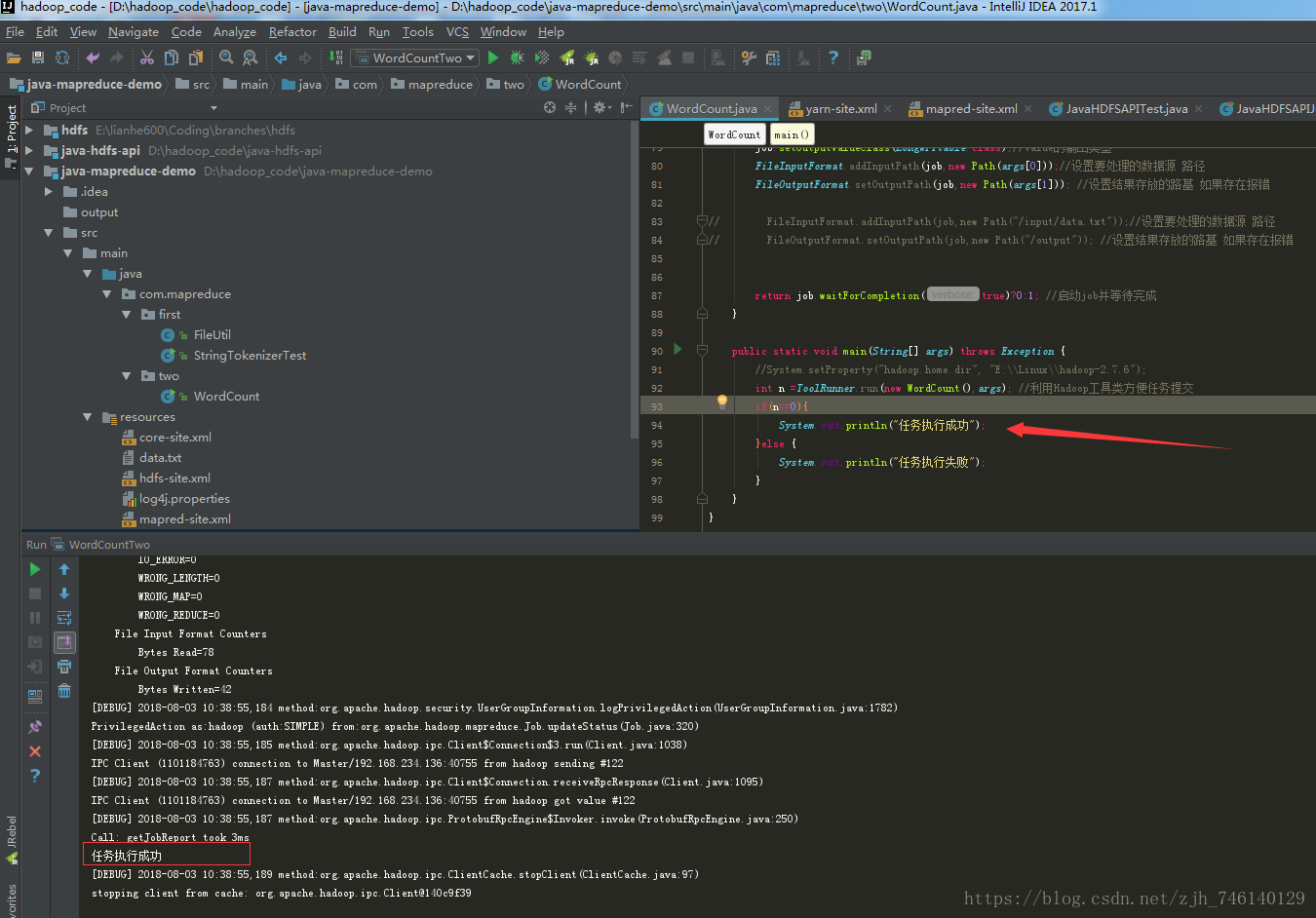
if(n==0){
System.out.println("任务执行成功");
}else {
System.out.println("任务执行失败");
}
}
}
三、package打包项目
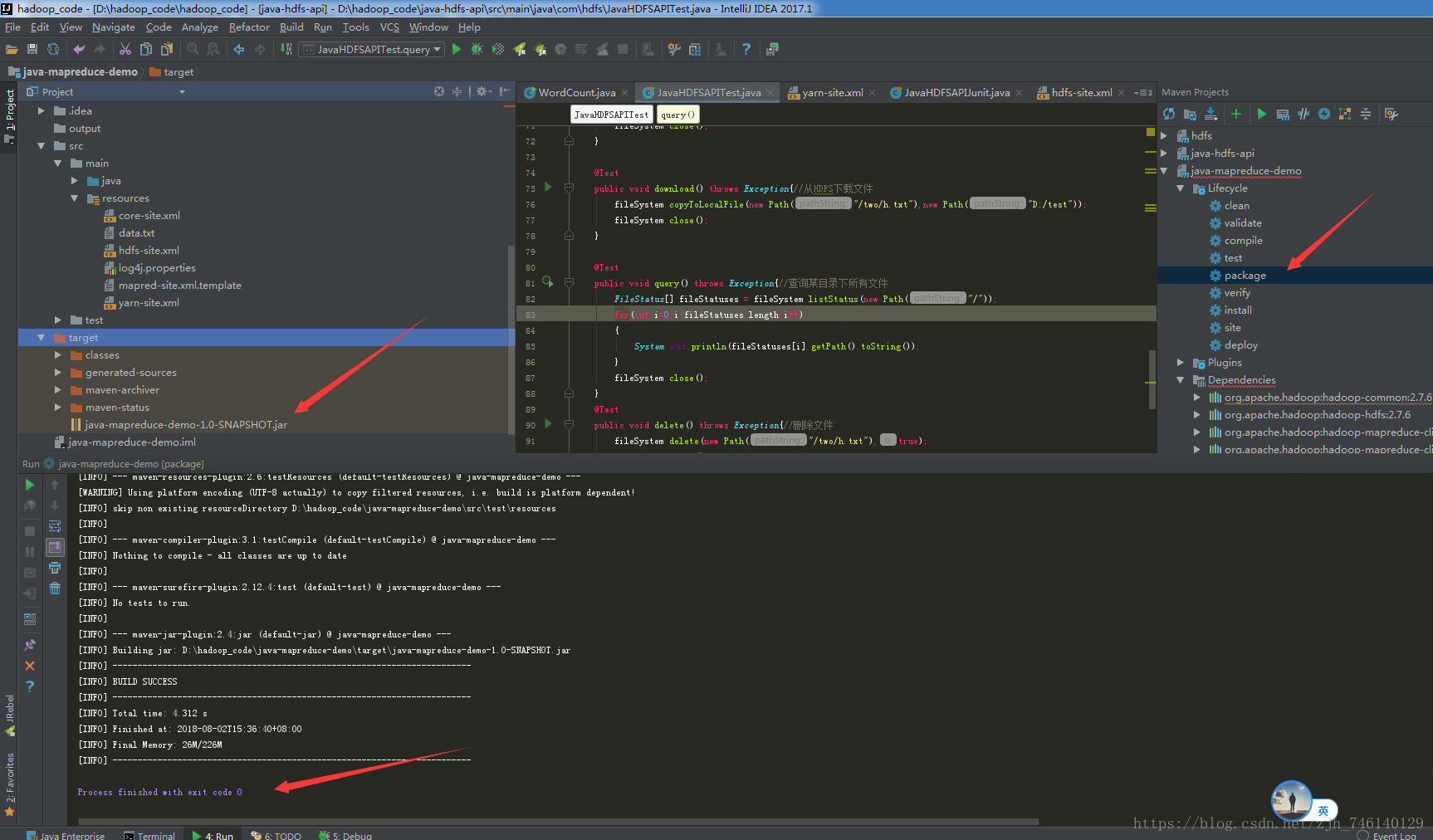
这里可以看到打包的jar,这个也可以直接拿去机器里面执行
hadoop jar datacount.jar
四、hadoop配置文件(core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、slaves)
①、core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- Hadoop 文件系统的临时目录(NameNode和DataNode默认存放在hadoop.tmp.dir目录)-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<!-- 配置NameNode的URI -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
</configuration>
②、hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- Master可替换为IP -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50070</value>
</property>
<!-- 设置系统里面的文件块的数据备份个数,默认是3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- NameNode结点存储hadoop文件系统信息的本地系统路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<!-- DataNode结点被指定要存储数据的本地文件系统路径,这个值只对NameNode有效,DataNode并不需要使用到它 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
③、yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.234.136</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
④、mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
</configuration>
⑤、slaves
Slavel
五、修改idea配置
-DHADOOP_USER_NAME=hadoop
-D
mapred.jar=D:\hadoop_code\java-mapreduce-demo\target\java-mapreduce-demo-1.0-SNAPSHOT.jar
/input
/output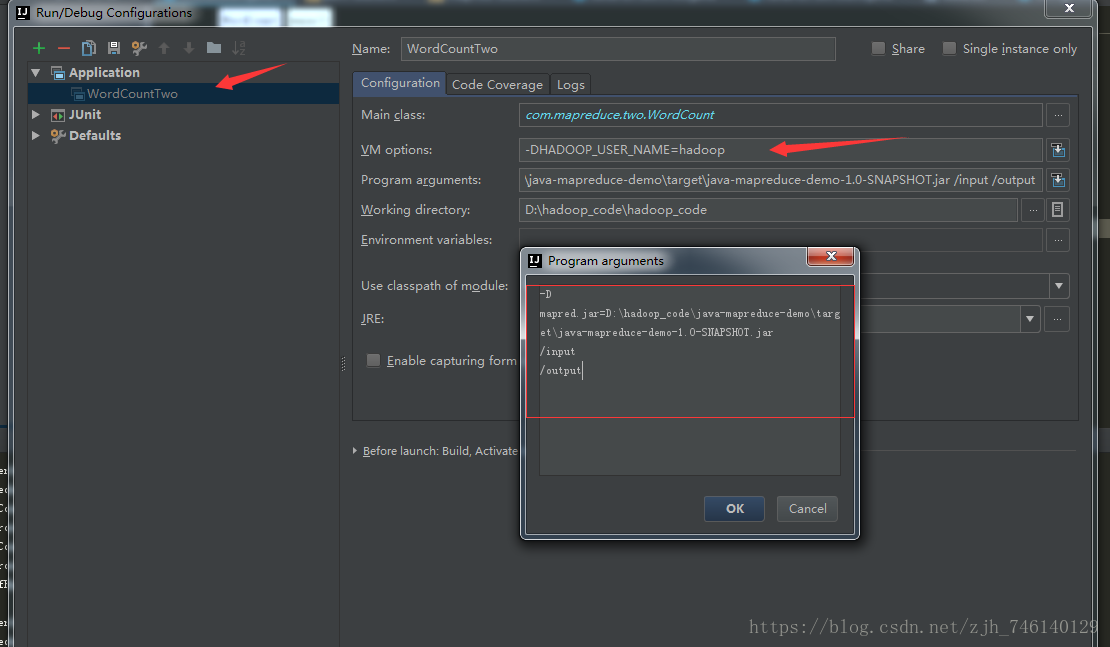
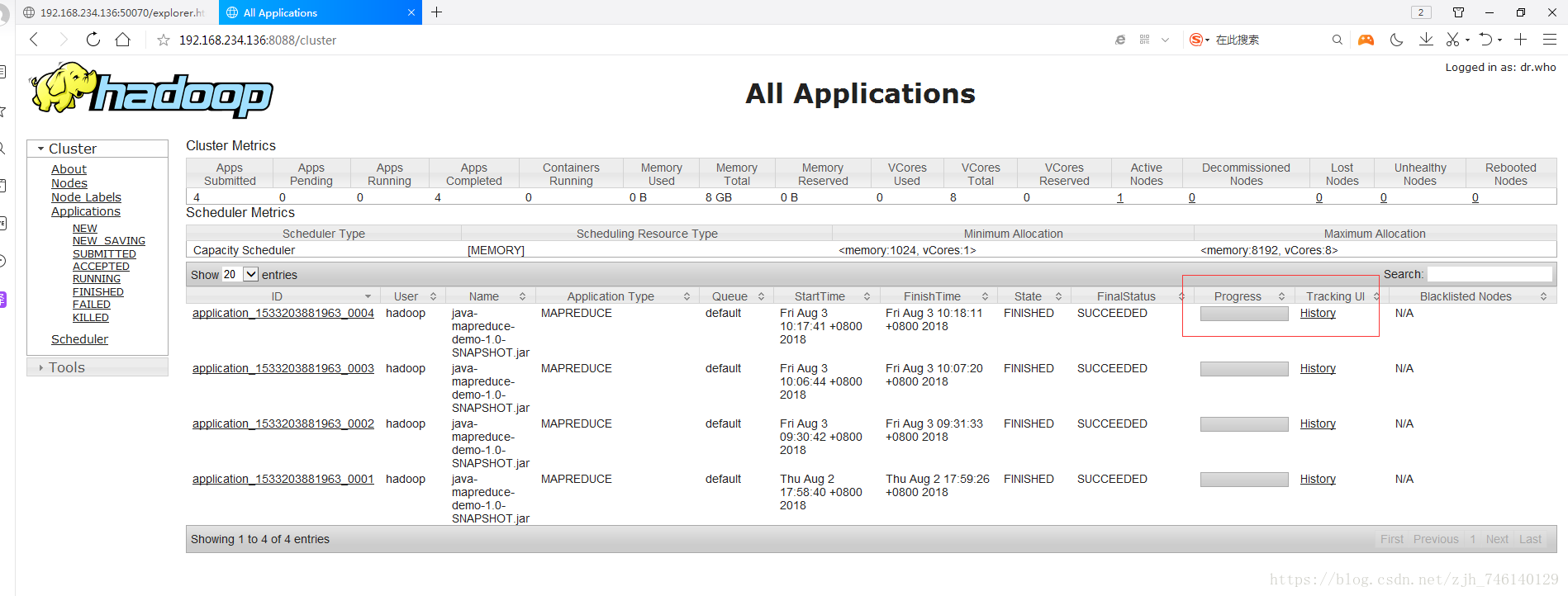
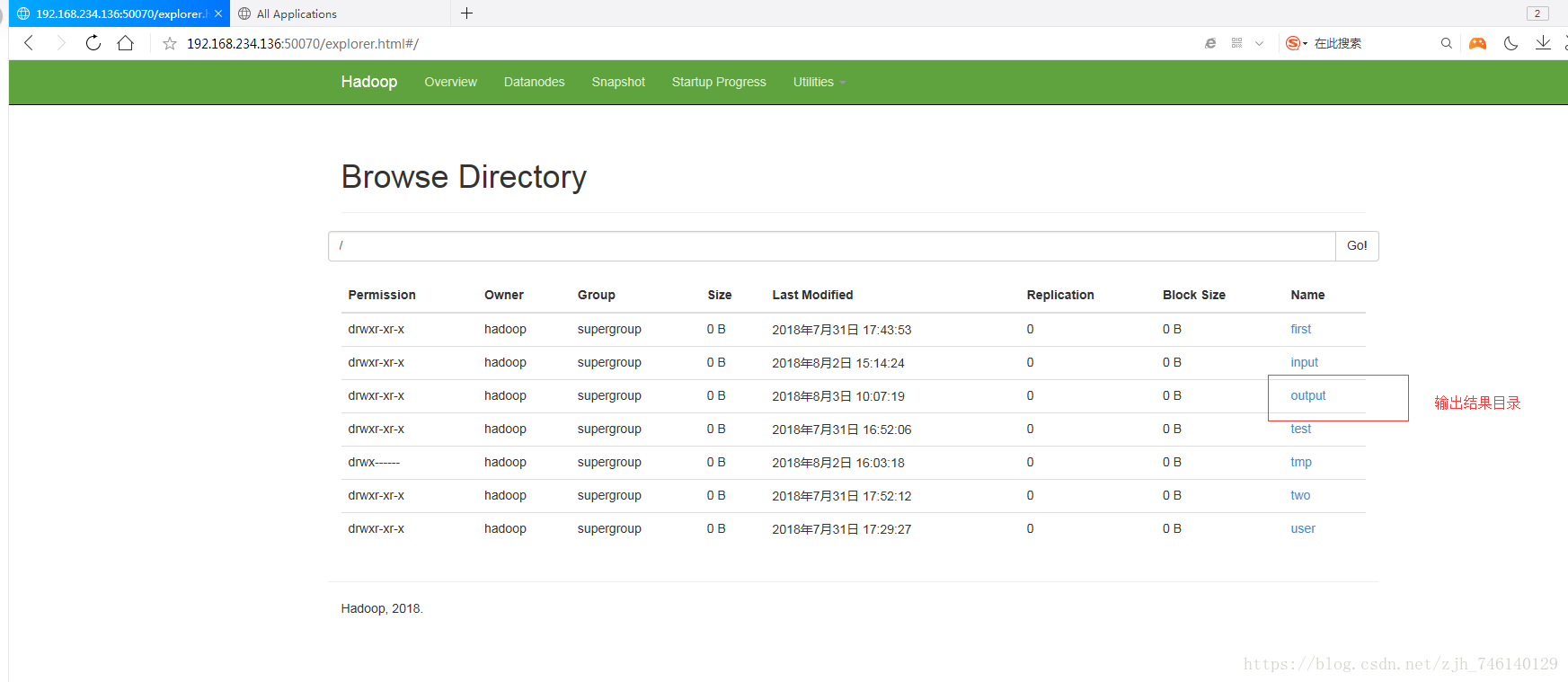
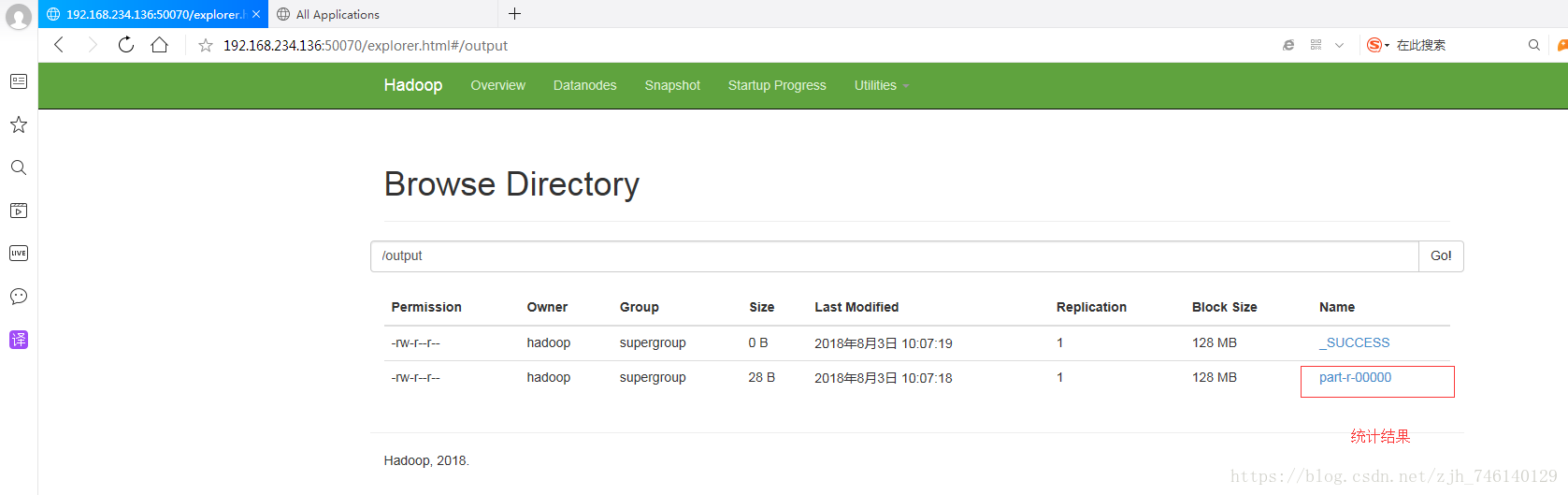
六、启动(运行main方法,过程比较慢,这里加了Log4j日志打印)
System.setProperty("hadoop.home.dir", "E:\\Linux\\hadoop-2.7.6");