一、MapReduce概念
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
二、MapReduce核心思想
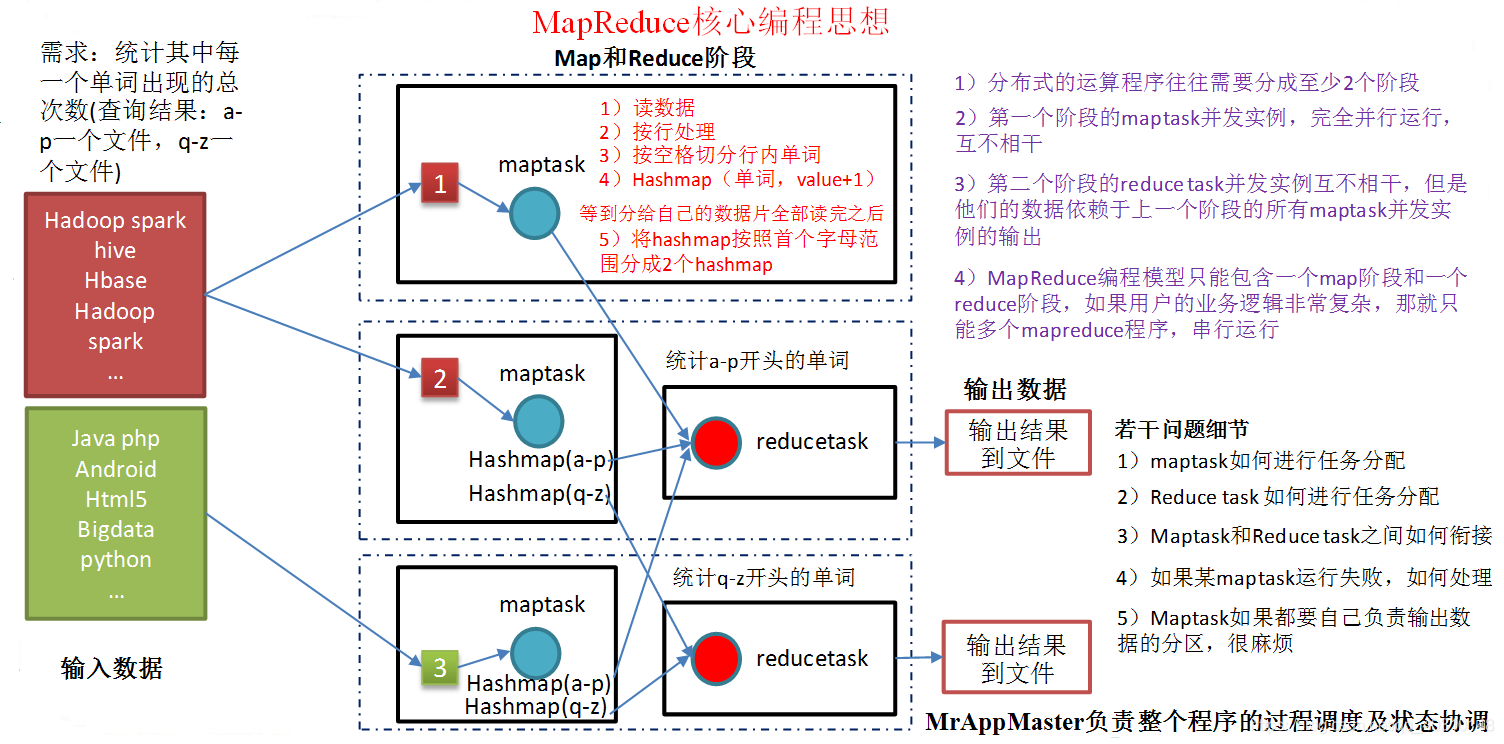
1)分布式的运算程序往往需要分成至少2个阶段
2)第一个阶段的maptask并发实例,完全并行运行,互不相干
3)第二个阶段的reduce task并发实例互不相干,但是他们的数据依赖于上一个阶段的所有maptask并发实例的输出
4)MapReduce编程模型只能包含一个map阶段和一个reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个mapreduce程序,串行运行
三、MapReduce编程规范(八股文)
用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
1)Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map()方法中
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(maptask进程)对每一个<K,V>调用一次
2)Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
3)Driver阶段
整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
四、案例实操
WordCount案例:统计一堆文件中单词出现的个数
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
1)分析


2)编写程序
(1)定义一个mapper类
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* KEYIN:输入数据的key 文件的行号
* VALUEIN:每行的输入数据
* KEYOUT:输出数据的key
* VALUEOUT:输出数据的value类型
*/
public class WordcountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
//hello world
//mjy
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
// 1、获取这一行数据
String line = value.toString();
// 2、获取每一个单词
String[] words = line.split(" ");
for(String word:words) {
// 3、输出每一个单词
context.write(new Text(word),new IntWritable(1));
}
}
}(2)定义一个reducer类
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
//统计所有单词个数
int count = 0;
for(IntWritable value : values) {
count += value.get();
}
//输出所有单词个数
context.write(key,new IntWritable(count));
}
}(3)定义一个主类,用来描述job并提交job
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//驱动主程序
public class WordcountDriver {
public static void main(String[] args) throws Exception {
//1、获取job对象信息
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2、设置加载jar位置
job.setJarByClass(WordcountDriver.class);
//3、设置mapper和reducer的class类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//4、设置输出mapper的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、设置最终数据输出的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、设置输入数据和输出数据路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7、提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}(4)将程序打成jar包,然后拷贝到hadoop集群中。
sftp:/home/atguigu> jar包
(5)启动hadoop集群
(6)执行wordcount程序
hadoop jar xx.jar 全路径 hdfs文件 目的文件