一、过拟合
当样本特征很多,样本数相对较少时,模型容易陷入过拟合。为了缓解过拟合问题,有两种方法:
方法一:减少特征数量(人工选择重要特征来保留,会丢弃部分信息)。
方法二:正则化(减少特征参数的数量级)。
二、正则化(Regularization)
正则化是结构风险(损失函数+正则化项)最小化策略的体现,是在经验风险(平均损失函数)上加一个正则化项。正则化的作用就是选择经验风险和模型复杂度同时较小的模型。
防止过拟合的原理:正则化项一般是模型复杂度的单调递增函数,而经验风险负责最小化误差,使模型偏差尽可能小。经验风险越小,模型越复杂,正则化项的值越大。要使正则化项也很小,那么模型复杂程度受到限制,因此就能有效地防止过拟合。
三、线性回归正则化(Regularized Linear Regression)
正则化一般具有如下形式的优化目标:
(1)
其中,是用来平衡正则化项和经验风险的系数。
正则化项可以是模型参数向量的范数,经常用的有范数、
范数(
范数:
,
范数:
)。
我们考虑最简单的线性回归模型。
给定数据集给定数据集,其中
,
。
代价函数为: (2)
(1)范数正则化(Ridge Regression,岭回归)
代价函数为: (3)
(2)范数正则化(LASSO,Least Absolute Shrinkage and Selection Operator)
代价函数为: (4)
(3)正则项和
正则项混合使用(Elastic Net)
代价函数为: (5)
其中,范数和
范数正则化都有助于降低过拟合风险,
范数通过对参数向量各元素平方和求平方根,使得
范数最小,从而使得参数
的各个元素都接近0,但不等于0。而
范数正则化比
范数更易获得“稀疏”解,即
范数正则化求得的
会有更少的非零分量,所以
范数可用于特征选择,而
范数在参数规则化时经常用到。(事实上,
范数得到的“稀疏”解最多,但
范数
是向量中非零元素的个数,不连续,难以优化求解。因此常用
范数来近似)。
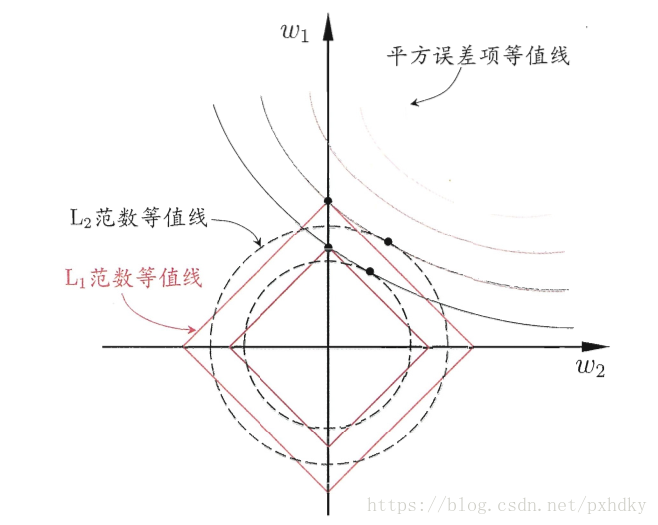
为什么正则化更易获得“稀疏”解呢?
假设仅有两个属性,
只有两个参数
,绘制不带正则项的目标函数——平方误差项等值线,再绘制
、
范数等值线,如图1。正则化后优化目标的解要在平方误差项和正则化项之间折中,即出现在图中等值线相交处。采用
范数时,交点常出现在坐标轴上,即
或
为0;而采用
范数时,交点常出现在某个象限中,即
,
均非0。也就是说,
范数比
范数更易获得“稀疏”解。
四、Ridge回归求解
Ridge回归不抛弃任何一个特征,缩小了回归系数。
Ridge回归求解与一般线性回归一致。
(1)如果采用梯度下降法:
(6)
迭代公式如下:
(7)
(2)如果采用正规方程:
最优解为:
(8)
最后,将学得的线性回归模型为:
(9)
五、LASSO回归求解
由于范数用的是绝对值之和,导致LASSO的优化目标不是连续可导的,也就是说,最小二乘法、梯度下降法、牛顿法、拟牛顿法都不能用。
正则化问题求解可采用近端梯度下降法(Proximal Gradient Descent,PGD)。
(1)优化目标
优化目标为: (10)
若可导,且梯度
满足L-lipschitz(利普希茨连续条件),即存在常数
,使得:
(11)
L-lipschitz(利普希茨连续条件)定义:
对于函数
,若其任意定义域中的
,
,都存在
,使得
,即对于
。
(2)泰勒展开
则在附近可将
进行二阶泰勒展开:
(12)
由(11)式,将泰勒展开式的二阶导用近似代替,得到:
(13)
(3)简化泰勒展开式
将(13)式化简:
(14)
其中,是与
无关的常数。
(4)简化优化问题
这里若通过梯度下降法对(
连续可导)进行最小化,则每一步下降迭代实际上等价于最小化二次函数
,推广到优化目标(10),可得到每一步迭代公式:
(15)
令,
则可以先求,再求解优化问题:
(16)
(5)求解
令为
的第
个分量,将 (16)式按分量展开,其中不存在
这样的项,即
的各分量之间互不影响,所以12)式有闭式解。
为什么(16)式不存在
这样的项?
因为展开(16)式得到,
从而优化问题变为求解d个独立的函数:
。
对于上述优化问题需要用到soft thresholding软阈值函数(证明见参考文献2),即对于优化问题:
(17)
其解为: (18)
而我们的优化问题为(16)式,则得到闭式解为:
(19)
其中,与
分别是
与
的第
个分量。因此,通过PGD能是LASSO和其他基于
范数最小化的方法得以快速求解。
参考文献:
1. 《机器学习》第十一章嵌入式选择与L1正则化-周志华
4. 正则化及正则化项的理解