版权声明:如需转载请联系本人[email protected] https://blog.csdn.net/u012491646/article/details/79317916
```python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Mon Feb 12 16:11:26 2018
@author: zhangll
"""
from sklearn
import svm
import matplotlib.pyplot
as plt
#
from sklearn
import datasets
# 数据源类(里面包含各种可用的数据类)
import numpy
as np
# numpy 包与scikitlearning包紧密联系在一起,因为所有数据的存储结构一般是以numpy array类型存储的
from sklearn.svm
import SVC
# 这个是svm算法中的svc评估(estimator)器
from sklearn.multiclass
import OneVsRestClassifier
# 这个一般可用于多分类模型训练,顾名思义:一个分类vs剩余的其他分类分类器
#加载sklean包中的所有数据源存储在datasets中,我们加载0-9数字组成的训练样本集合
digits = datasets.load_digits()
#一般而言 可以用datasets.load_数据样本名()获取你想要的数据集合,比如常用的鸢尾花数据集合的加载 datasets.load_iris()
#获取的每一种数据集合都会以字典dict(key,value)的形式存储
#比如:图像digits格式是以{data:..;images:..;target:..;target_names:..;descr:..}
#由五个key:value组成,所以顾明思议,data就是存储图片数据的,格式是(1797,64)也就是1797个样本,64维度(变量)的值
# images存储的shape大小为1797,8,8,它是以8*8的矩阵形式存储的64维data
# target 就是标签数据,shape大小为(1979,1),就是对一个的每个样本所属的类别
# target_names就是set(target),
# descr 就是对这个集合的描述,我们做一下训练需要用到data,target以及画图的时候需要用到image
# multiclass (多分类器(y只有一维))vs multilabel(多标签分类器) fitting
#本文的分类目标就是对1797个样本中的前1796个样本与target作为训练样本,然后对最后一个样本做评估
# 1. multiclass (用到是是target),代码很简单因为sklearn做了很多的封装处理
#a)X代表前1796具有(64,1)维度的矩阵 Y代表对应的标签(1796,1)
X = digits.data[:-
1]
Y = digits.target[:-
1]
#b) OneVsRestClassifier内部聚合了svc评估器,OneVsRestClassifier内部封装了fit,predict等等方法
multiC = OneVsRestClassifier(
estimator=SVC(
random_state=
0))
#c.1) fit代表喂x,y数据,返回的是OneVsRestClassifier类对象,然后对这个评估器类做预测(输入数据),返回的是一个array([])对象
# 在sklearn包中为了开发方便,沿用了pipline工作方式,也就是每个评估器,fit器都会返回评估器类,因此可以写成如下格式
predict1 = multiC.fit(X,Y).predict(digits.data[-
1:])
#predict1 存储的是预测的结果[3]
#c.2).multilabel (需要对target做个变换,变换成具有位置信息的指示向量)
# 标签数据可以简单分成2种类型的y,[1.单分类标签 2.多分类标签
# 先介绍 单分类标签,这里指的是每个图像样本对应的分类具有且只有一种标签
# 这里的含义是对原先的一维的标签target做个指示变量的变换,在统计术语上就是对数做Dummy Variables(哑变量)转换,
# 是属于"预处理"模块中的
# 所以需要调取sklearn预处理模块(正在进行时)中的binarizer器
from sklearn.preprocessing
import LabelBinarizer
as lbb
# y返回的类型是numpy.array类型
y = lbb().fit_transform(Y)
predict2 = multiC.fit(X,y).predict(digits.data[-
1:])
#predict2 存储的是预测的结果
%matplotlib inline
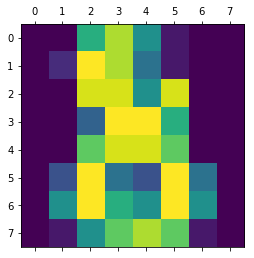
#d)画个图看看是不是自己想要的结果 最后画出来的是一个类似与8的图案
plt.matshow(digits.images[-
1:][
0])
```
```python
print(predict1);
print(predict2)
```
[3]
[[0 0 0 0 0 0 0 0 0 0]]
```python
#多标签分类器
from sklearn.preprocessing
import MultiLabelBinarizer
as mlb
ym = mlb().fit_transform(np.array([[x,y+
1]
for x,y
in
zip(Y,Y)]))
print(ym.shape)
print(y.shape)
#%who#在jupyter中的变量名,有包含类元素,也包含变量元素
ym[
0]
```
(1796, 11)
(1796, 10)
No variables match your requested type.
array([1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0])
```python
# 多标签分类器 如下
labely = [[
"e",
"b"],[
"b",
"c"],[
"c",
"d"],[
"e",
"f"],[
"a",
"i"]]
labely_mult = mlb().fit_transform(labely)
# 多分类标签可以在多分类器中自动地进行指示向量的变换
# 变换的标准是以多分类标签中的a元素对应的ascci码的秩序作为序列的先后标记
labely_mult
```
array([[0, 1, 0, 0, 1, 0, 0],
[0, 1, 1, 0, 0, 0, 0],
[0, 0, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 1, 0],
[1, 0, 0, 0, 0, 0, 1]])
```python
type(y)
```
numpy.ndarray