说到准确率accuracy、精确率precision,召回率recall等指标,有机器学习基础的应该很熟悉了,但是一般的理论科普文章,举的例子通常是二分类,而当模型是多分类时,使用sklearn包去计算这些指标会有几种不同的算法,初学者很容易被不同的算法所迷惑。本文用直观的例子讲解micro、macro、weighted几种算法,以及样本不均时加入sample_weight参数的计算方法。
如果有想学习python的程序员,可来我的python学习扣qun:711944363,免费送python的视频教程噢!我每晚上8点还会在群内直播讲解python知识,欢迎大家前来学习哦。
本文以三分类模型举例。首先我们生成一组数据:
import numpy as np
y_true = np.array([-1]*30 + [0]*240 + [1]*30)
y_pred = np.array([-1]*10 + [0]*10 + [1]*10 +
[-1]*40 + [0]*160 + [1]*40 +
[-1]*5 + [0]*5 + [1]*20)
数据分为-1、0、1三类,真实数据y_true中,一共有30个-1,240个0,30个1。然后我们生成真实数据y_true和预测数据y_pred的混淆矩阵,之后的演示中我们会用到混淆矩阵的数据:
>>> confusion_matrix(y_true, y_pred)
array([[ 10, 10, 10],
[ 40, 160, 40],
[ 5, 5, 20]], dtype=int64)
由混淆矩阵我们可以计算出真正类数TP、假正类数FP、假负类数FN,如下:

之后我们以precision_score的计算为例,accuracy_score、recall_score、f1_score等均可以此类推。
首先我们看一下sklearn包中计算precision_score的命令:
sklearn.metrics.precision_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’,
sample_weight=None)
其中,average参数定义了该指标的计算方法,二分类时average参数默认是binary,多分类时,可选参数有micro、macro、weighted和samples。samples的用法我也不是很明确,所以本文只讲解micro、macro、weighted。
1 不加sample_weight
1.1 micro
micro算法是指把所有的类放在一起算,具体到precision,就是把所有类的TP加和,再除以所有类的TP和FN的加和。因此micro方法下的precision和recall都等于accuracy。
使用sklearn计算的结果也是一样:
>>> from sklearn.metrics import precision_score
>>> precision_score(y_true, y_pred, average="micro")
0.6333333333333333
可以看到和手算是相同的。
1.2 macro
macro方法就是先分别求出每个类的precision再算术平均。
用sklearn验证一下:
>>> precision_score(y_true, y_pred, average="macro")
0.46060606060606063
1.3 weighted
前面提到的macro算法是取算术平均,weighted算法就是在macro算法的改良版,不再是取算术平均、乘以固定weight(也就是1/3)了,而是乘以该类在总样本数中的占比。计算一下每个类的占比:
>>> w_neg1, w_0, w_pos1 = np.bincount(y_true+1) / len(y_true)
>>> print(w_neg1, w_0, w_pos1)
0.1 0.8 0.1
然后手算一下weighted方法下的precision:
用sklearn验证一下:
>>> precision_score(y_true, y_pred, average="weighted")
0.7781818181818182
2 加入sample weight
当样本不均衡时,比如本文举出的样本,中间的0占80%,1和-1各占10%,每个类数量差距很大,我们可以选择加入sample_weight来调整我们的样本。
首先我们使用sklearn里的compute_sample_weight函数来计算sample_weight:
sw = compute_sample_weight(class_weight='balanced',y=y_true)
sw是一个和ytrue的shape相同的数据,每一个数代表该样本所在的sample_weight。它的具体计算方法是总样本数/(类数*每个类的个数),比如一个值为-1的样本,它的sample_weight就是300 / (3 * 30)。
使用sample_weight计算出的混淆矩阵如下:
>>> cm =confusion_matrix(y_true, y_pred, sample_weight=sw)
>>> cm
array([[33.33333333, 33.33333333, 33.33333333],
[16.66666667, 66.66666667, 16.66666667],
[16.66666667, 16.66666667, 66.66666667]])
由该混淆矩阵可以得到TP、FN、FP:
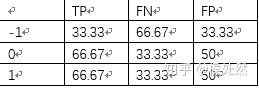
三种precision的计算方法和第一节中计算的一样,就不多介绍了。使用sklearn的函数时,把sw作为函数的sample_weight参数输入即可。
本文介绍了一些sklearn应用时的细节,希望对读到这里的你有所帮助~