判断是否幸福?
首先导入相关包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.svm import SVC, LinearSVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
然后读取数据:
data = pd.read_csv("数据集\\train.csv")
# 因为数据集中列比较多,我们需要把dataframe中的列全部显示出来
pd.set_option('display.max_columns', None)
# 输出属性行
print(data.columns)
# 输出前5个元组
print(data.head(5))
# print(data.describe())
输出如下:
Index(['User ID', 'Age', 'MonthlySalary', 'Happiness'], dtype='object')
User ID Age MonthlySalary Happiness
0 8.094168e+06 19 19000 0
1 8.218457e+06 35 20000 0
2 8.123545e+06 26 43000 0
3 8.079992e+06 27 57000 0
4 8.213829e+06 19 76000 0
接下来进行数据清洗,因为有些数据无实际意义(如User ID),而且有的时候数据含有字符,下面解决这些问题,
data['Happiness'] = data['Happiness'].map({0: '不幸福', 1: '幸福'})
data['Happiness'] = data['Happiness'].map({'不幸福': 0, '幸福': 1})
然后我们要然后做特征字段的筛选,首先需要观察下data.columns各变量之间的关系,这里使用DataFrame的corr()函数,然后用热力图帮助可视化实现,然后将判断结果可视化:
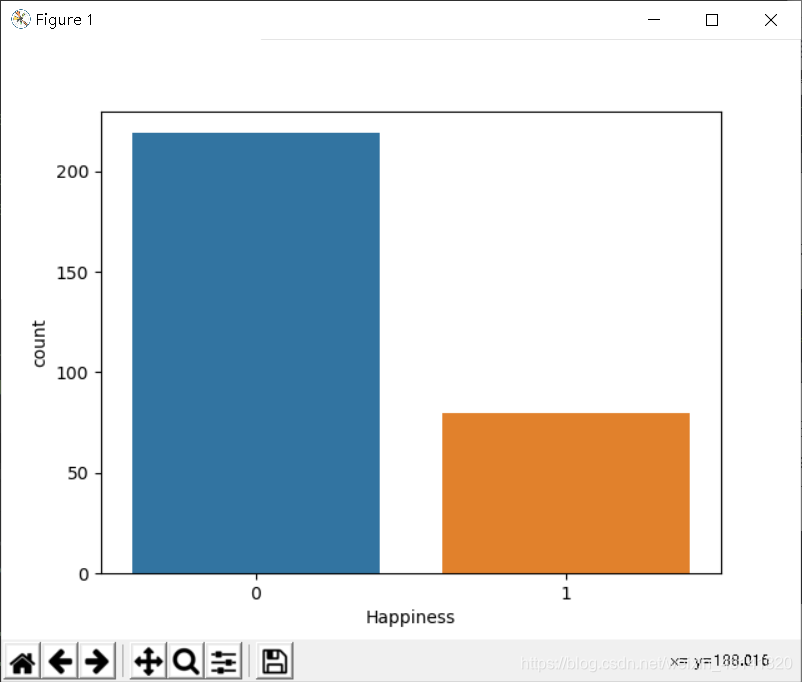
sns.countplot(data['Happiness'], label='happiness or not')
plt.show()
计算相关系数并且使用热力图显示出来:
# 用热力图呈现data字段之间的相关性
corr = data.corr()
plt.figure(figsize=(6, 6))
# annot=True显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()

Happiness为最终的结果,不作为特征字段,所以需要选出特征字段,所以修改一下:
# Happiness为最终的结果,不作为特征字段,所以需要选出特征字段
features = list(data.columns[: -1])
print(features)
# 用热力图呈现data字段之间的相关性
corr = data[features].corr()
plt.figure(figsize=(6, 6))
# annot=True显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()
features: ['Age', 'MonthlySalary']
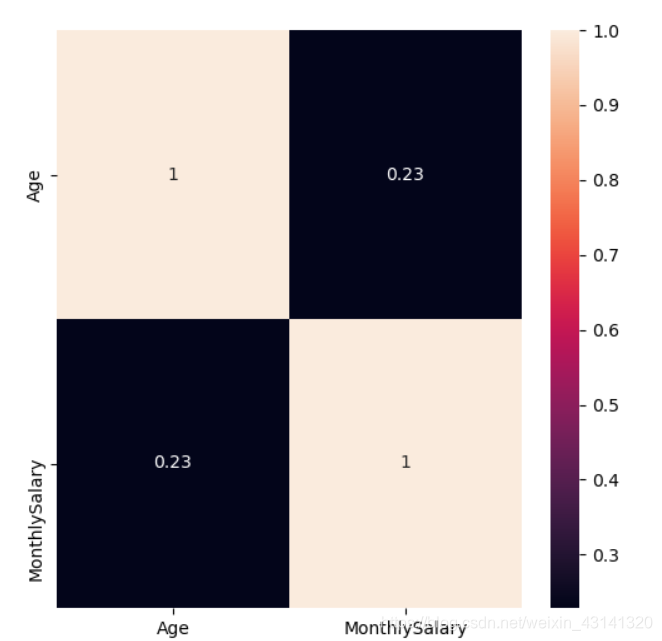
热力图中对角线上的为单变量自身的相关系数是 1。颜色越浅代表相关性越大。可以看见MonthlySalary和Age的相关性是非常大的。
那么如何进行特征选择呢?
特征选择的目的是降维,用少量的特征代表数据的特性,这样也可以增强分类器的泛化能力,避免数据过拟合。
这样我们将特征转化为:

features_remain = ['Age', 'MonthlySalary']
对特征进行选择之后,我们就可以准备训练集和测试集:
如果你的训练集和测试集是混在一起的,可以使用如下指令实现数据集的划分:
# 抽取30%的数据作为测试集,其余作为训练集
train, test = train_test_split(data, test_size = 0.3)# in this our main data is splitted into train and test
# 抽取特征选择的数值作为训练和测试数据
train_X = train[features_remain]
train_y=train['Happiness']
test_X= test[features_remain]
test_y =test['Happiness']
但是我这次的训练集和测试集是分开在两个表格中的,所以只用导入就行了:
# 读入测试集:
train_x = data[features_remain]
train_y = data['Happiness']
test_data = pd.read_csv('数据集\\test.csv')
test_x = data[features_remain]
test_y = data['Happiness']
在训练之前,我们需要对数据进行规范化,这样让数据同在同一个量级上,避免因为维度问题造成数据误差:
# 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)
最后我们可以让 SVM 做训练和预测了:
model = SVC(kernel='rbf', C=1.0, gamma='auto')
# 用训练集训练:
model.fit(train_x, train_y)
# 用测试集预测:
prediction = model.predict(test_x)
print('准确率:', metrics.accuracy_score(prediction, test_y))
准确率: 0.903010033444816
对于模型的选择,还可以选择 model=svm.LinearSVC()。
在 LinearSVC 中没有 kernel 这个参数,限制我们只能使用线性核函数。由于 LinearSVC 对线性分类做了优化,对于数据量大的线性可分问题,使用 LinearSVC 的效率要高于 SVC。
经过测试,LinearSCV()的准确率为:
准确率: 0.8561872909698997
为了弄清楚C最最终准确率的影响,使用如下代码段进行测试:
accuracy = []
x = np.arange(10, 1000, 0.1)
for i in x:
model = SVC(kernel='rbf', C=i, gamma='auto')
model.fit(train_x, train_y)
prediction = model.predict(test_x)
accuracy.append(metrics.accuracy_score(prediction, test_y))
y = np.array(accuracy)
plt.plot(x, y)
plt.show()
结果:
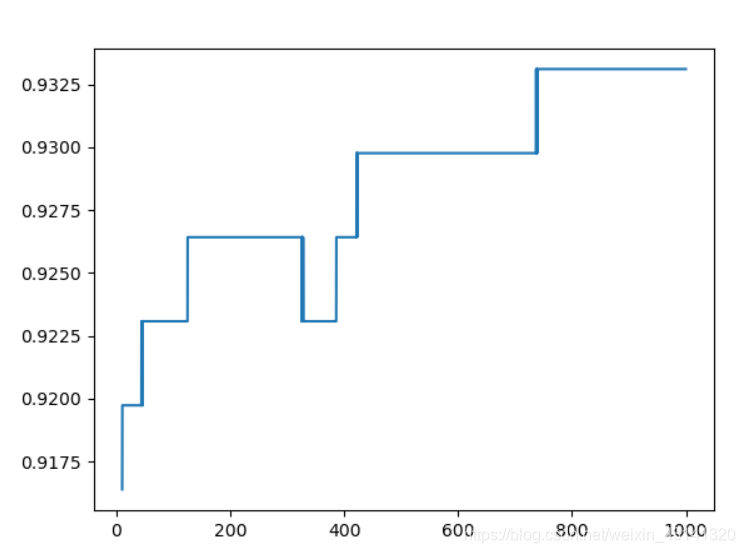
可以看见,不是说C增大准确率一定会增加,可能在某一段c的范围内准确率几乎不变,以至于计算机忽视变化。
下面对SVC()的各个参数进行介绍:
kernel代表核函数的选择,有四种选择,默认rbf,即高斯核函数
linear:线性核函数,是在数据线性可分的情况下使用的,运算速度快,效果好。不足在于它不能处理线性不可分的数据。(在本例中C设为100,换为这个核函数之后的准确率为:0.8595317725752508)
poly:多项式核函数,多项式核函数可以将数据从低维空间映射到高维空间,但参数比较多,计算量大。(在本例中C设为100,换为这个核函数之后的准确率为:0.8729096989966555)
rbf:高斯核函数(默认),高斯核函数同样可以将样本映射到高维空间,但相比于多项式核函数来说所需的参数比较少,通常性能不错,所以是默认使用的核函数。(在本例中C设为100,换为这个核函数之后的准确率为:0.9230769230769231)
sigmoid:sigmoid 核函数,sigmoid 经常用在神经网络的映射中。因此当选用 sigmoid 核函数时,SVM 实现的是多层神经网络。(在本例中C设为100,换为这个核函数之后的准确率为:0.7324414715719063)
参数 C 代表目标函数的惩罚系数,惩罚系数指的是分错样本时的惩罚程度,默认情况下为 1.0。当 C 越大的时候,分类器的准确性越高,但同样容错率会越低,泛化能力会变差。相反,C 越小,泛化能力越强,但是准确性会降低。
参数 gamma 代表核函数的系数,默认为样本特征数的倒数,即 gamma = 1 / n_features。
本例中为了验证User ID是否真的对结果的预测影响不大,我保留User ID字段,使用的模型为SVC,核函数为’rbf’, C值为100,最终的预测结果为:
准确率: 0.9230769230769231
和上面的同条件的删除这个字段的准确率相比无变化。
