
本文使用
sklearn的逻辑斯谛回归模型,进行
鸢尾花多分类预测,对预测结果进行对比。
1. 预备知识
逻辑斯谛回归模型( Logistic Regression,LR)
基于sklearn的LogisticRegression二分类实践
sklearn 的多分类选项
In the multiclass case, the training algorithm uses the one-vs-rest (OvR) scheme if the ‘multi_class’ option is set to ‘ovr’,
and uses the cross-entropy loss if the ‘multi_class’ option is set to ‘multinomial’. (Currently the ‘multinomial’ option is supported only by the ‘lbfgs’, ‘sag’, ‘saga’ and ‘newton-cg’ solvers.)
multi_class : {‘auto’, ‘ovr’, ‘multinomial’}, default=‘auto’
If the option chosen is ‘ovr’, then a binary problem is fit for each label.
For ‘multinomial’ the loss minimised is the multinomial loss fit across the entire probability distribution, even when the data is binary.
‘multinomial’ is unavailable when solver=‘liblinear’.
‘auto’ selects ‘ovr’ if the data is binary, or if solver=‘liblinear’, and otherwise selects ‘multinomial’.
分类器:
- One-vs-the-rest (OvR),也叫 one-vs-all,n分类的时候进行n次二分类( ),哪个 分类的概率最高取其为结果
- One-vs-one (OvO),需要进行 次二分类,复杂度是 O(n2),比 OvR 慢,但是准确性会比其高,因为没有混入其他的类,最后取得票多的为预测结果
2. 实践代码
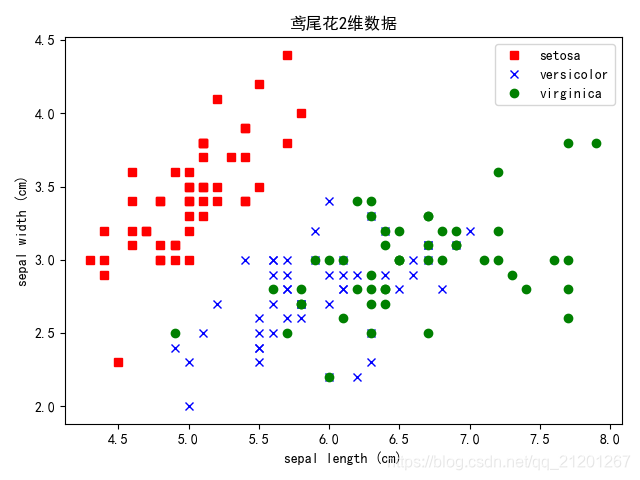
2.1 数据分析展示
- 取sklearn的内置的鸢(yuan)尾花数据作为原始数据
数据集包含150个样本的4个特征,分别是:
sepal length(花萼长度,cm)
sepal width(花萼宽度,cm)
petal length(花瓣长度,cm)
petal width(花瓣宽度,cm)
3种鸢尾属植物分类:Setosa,Versicolour,Virginica
其中一类可以跟另两类线性可分,另两类线性不可分。
>>> print(dir(iris)) # 可查看数据具有的属性和方法
['DESCR', 'data', 'feature_names', 'filename', 'target', 'target_names']
>>> print(iris.target_names)
['setosa' 'versicolor' 'virginica']
由于平面只能展示2维特征,我们取前2个特征进行实践。
def show_data_set(X, y, data):
plt.plot(X[y == 0, 0], X[y == 0, 1], 'rs', label=data.target_names[0])
plt.plot(X[y == 1, 0], X[y == 1, 1], 'bx', label=data.target_names[1])
plt.plot(X[y == 2, 0], X[y == 2, 1], 'go', label=data.target_names[2])
plt.xlabel(data.feature_names[0])
plt.ylabel(data.feature_names[1])
plt.title("鸢尾花2维数据")
plt.legend()
plt.rcParams['font.sans-serif'] = 'SimHei' # 消除中文乱码
plt.show()
iris = datasets.load_iris()
# print(dir(iris)) # 查看data所具有的属性或方法
# print(iris.data) # 数据
# print(iris.DESCR) # 数据描述
X = iris.data[:, :2]
y = iris.target
show_data_set(X, y, iris)
2.2 选择不同的多分类模式进行预测
- OvR
def test1(X_train, X_test, y_train, y_test, multi_class='ovr', solver='liblinear'):
log_reg = LogisticRegression(multi_class=multi_class, solver=solver) # 调用ovr多分类
log_reg.fit(X_train, y_train)
predict_train = log_reg.predict(X_train)
sys.stdout.write("LR(multi_class = %s, solver = %s) Train Accuracy : %.4g\n" % (
multi_class, solver, metrics.accuracy_score(y_train, predict_train)))
predict_test = log_reg.predict(X_test)
sys.stdout.write("LR(multi_class = %s, solver = %s) Test Accuracy : %.4g\n" % (
multi_class, solver, metrics.accuracy_score(y_test, predict_test)))
plot_decision_boundary(4, 8.5, 1.5, 4.5, lambda x: log_reg.predict(x))
plot_data(X_train, y_train)
def test2(X_train, X_test, y_train, y_test):
# multi_class默认auto
# 'auto' selects 'ovr' if the data is binary, or if solver='liblinear',
# and otherwise selects 'multinomial'.
# 看完help知道auto选择的是ovr,因为下面求解器选的是 liblinear
# 所以test1和test2是同种效果,不一样的写法
log_reg = LogisticRegression(solver='liblinear')
ovr = OneVsRestClassifier(log_reg)
ovr.fit(X_train, y_train)
predict_train = ovr.predict(X_train)
sys.stdout.write("LR(ovr) Train Accuracy : %.4g\n" % (
metrics.accuracy_score(y_train, predict_train)))
predict_test = ovr.predict(X_test)
sys.stdout.write("LR(ovr) Test Accuracy : %.4g\n" % (
metrics.accuracy_score(y_test, predict_test)))
plot_decision_boundary(4, 8.5, 1.5, 4.5, lambda x: ovr.predict(x))
plot_data(X_train, y_train)
- OvO
def test3(X_train, X_test, y_train, y_test):
# For multiclass problems, only 'newton-cg', 'sag', 'saga' and 'lbfgs' handle multinomial loss;
log_reg = LogisticRegression(multi_class='multinomial', solver='newton-cg')
ovo = OneVsOneClassifier(log_reg) # ovo多分类
ovo.fit(X_train, y_train)
predict_train = ovo.predict(X_train)
sys.stdout.write("LR(ovo) Train Accuracy : %.4g\n" % (
metrics.accuracy_score(y_train, predict_train)))
predict_test = ovo.predict(X_test)
sys.stdout.write("LR(ovo) Test Accuracy : %.4g\n" % (
metrics.accuracy_score(y_test, predict_test)))
plot_decision_boundary(4, 8.5, 1.5, 4.5, lambda x: ovo.predict(x))
plot_data(X_train, y_train)
2.3 执行预测
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=777) # 默认test比例0.25
test1(X_train, X_test, y_train, y_test, multi_class='ovr', solver='liblinear')
test2(X_train, X_test, y_train, y_test)
test1(X_train, X_test, y_train, y_test, multi_class='multinomial', solver='newton-cg')
test3(X_train, X_test, y_train, y_test)
2.4 结果分析
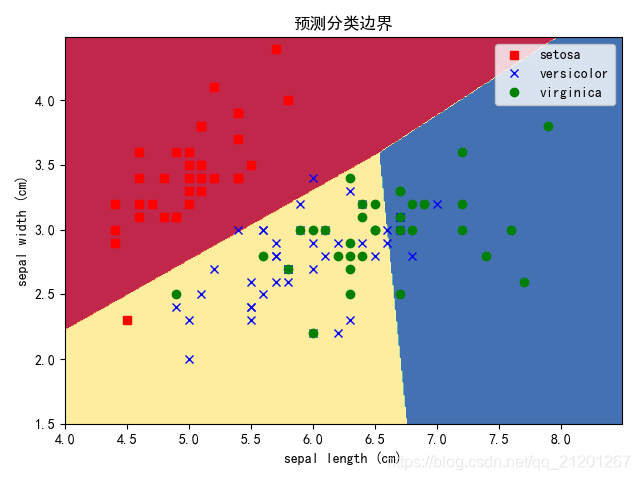
- 前两组是OvR模式的多分类,代码写法有区别,预测结果完全一样
LR(multi_class = ovr, solver = liblinear) Train Accuracy : 0.7589
LR(multi_class = ovr, solver = liblinear) Test Accuracy : 0.7368
LR(ovr) Train Accuracy : 0.7589
LR(ovr) Test Accuracy : 0.7368
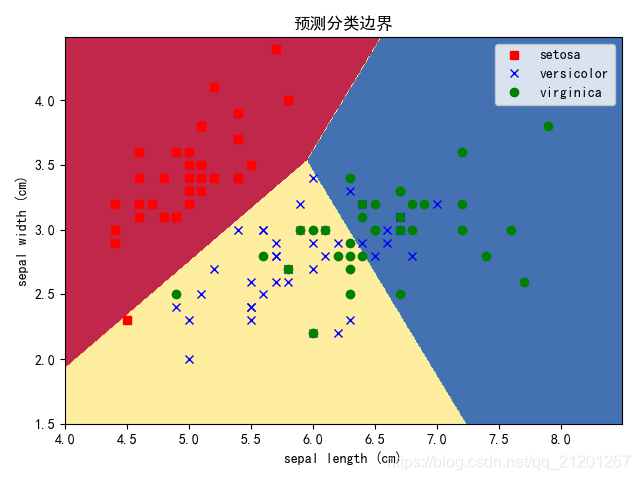
- 后两组是OvO模式的多分类
LR(multi_class = multinomial, solver = newton-cg) Train Accuracy : 0.7768
LR(multi_class = multinomial, solver = newton-cg) Test Accuracy : 0.8158
LR(ovo) Train Accuracy : 0.7946
LR(ovo) Test Accuracy : 0.8158
- 对比两种模式的多分类预测效果,OvO比OvR要好很多
- 看图可见
setosa与剩余2类线性可分,剩余两类之间线性不可分

3. 附完整代码
'''
遇到不熟悉的库、模块、类、函数,可以依次:
1)百度(google确实靠谱一些),如"matplotlib.pyplot",会有不错的博客供学习参考
2)"终端-->python-->import xx-->help(xx.yy)",一开始的时候这么做没啥用,但作为资深工程师是必备技能
3)试着修改一些参数,观察其输出的变化,在后面的程序中,会不断的演示这种办法
'''
# written by hitskyer, I just wanna say thank you !
# modified by Michael Ming on 2020.2.18
# Python 3.7
import sys
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
from sklearn.multiclass import OneVsOneClassifier
def show_data_set(X, y, data):
plt.plot(X[y == 0, 0], X[y == 0, 1], 'rs', label=data.target_names[0])
plt.plot(X[y == 1, 0], X[y == 1, 1], 'bx', label=data.target_names[1])
plt.plot(X[y == 2, 0], X[y == 2, 1], 'go', label=data.target_names[2])
plt.xlabel(data.feature_names[0])
plt.ylabel(data.feature_names[1])
plt.title("鸢尾花2维数据")
plt.legend()
plt.rcParams['font.sans-serif'] = 'SimHei' # 消除中文乱码
plt.show()
def plot_data(X, y):
plt.plot(X[y == 0, 0], X[y == 0, 1], 'rs', label='setosa')
plt.plot(X[y == 1, 0], X[y == 1, 1], 'bx', label='versicolor')
plt.plot(X[y == 2, 0], X[y == 2, 1], 'go', label='virginica')
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.title("预测分类边界")
plt.legend()
plt.rcParams['font.sans-serif'] = 'SimHei' # 消除中文乱码
plt.show()
def plot_decision_boundary(x_min, x_max, y_min, y_max, pred_func):
h = 0.01
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
def test1(X_train, X_test, y_train, y_test, multi_class='ovr', solver='liblinear'):
log_reg = LogisticRegression(multi_class=multi_class, solver=solver) # 调用ovr多分类
log_reg.fit(X_train, y_train)
predict_train = log_reg.predict(X_train)
sys.stdout.write("LR(multi_class = %s, solver = %s) Train Accuracy : %.4g\n" % (
multi_class, solver, metrics.accuracy_score(y_train, predict_train)))
predict_test = log_reg.predict(X_test)
sys.stdout.write("LR(multi_class = %s, solver = %s) Test Accuracy : %.4g\n" % (
multi_class, solver, metrics.accuracy_score(y_test, predict_test)))
plot_decision_boundary(4, 8.5, 1.5, 4.5, lambda x: log_reg.predict(x))
plot_data(X_train, y_train)
def test2(X_train, X_test, y_train, y_test):
# multi_class默认auto
# 'auto' selects 'ovr' if the data is binary, or if solver='liblinear',
# and otherwise selects 'multinomial'.
# 看完help知道auto选择的是ovr,因为下面求解器选的是 liblinear
# 所以test1和test2是同种效果,不一样的写法
log_reg = LogisticRegression(solver='liblinear')
ovr = OneVsRestClassifier(log_reg)
ovr.fit(X_train, y_train)
predict_train = ovr.predict(X_train)
sys.stdout.write("LR(ovr) Train Accuracy : %.4g\n" % (
metrics.accuracy_score(y_train, predict_train)))
predict_test = ovr.predict(X_test)
sys.stdout.write("LR(ovr) Test Accuracy : %.4g\n" % (
metrics.accuracy_score(y_test, predict_test)))
plot_decision_boundary(4, 8.5, 1.5, 4.5, lambda x: ovr.predict(x))
plot_data(X_train, y_train)
def test3(X_train, X_test, y_train, y_test):
# For multiclass problems, only 'newton-cg', 'sag', 'saga' and 'lbfgs' handle multinomial loss;
log_reg = LogisticRegression(multi_class='multinomial', solver='newton-cg')
ovo = OneVsOneClassifier(log_reg) # ovo多分类
ovo.fit(X_train, y_train)
predict_train = ovo.predict(X_train)
sys.stdout.write("LR(ovo) Train Accuracy : %.4g\n" % (
metrics.accuracy_score(y_train, predict_train)))
predict_test = ovo.predict(X_test)
sys.stdout.write("LR(ovo) Test Accuracy : %.4g\n" % (
metrics.accuracy_score(y_test, predict_test)))
plot_decision_boundary(4, 8.5, 1.5, 4.5, lambda x: ovo.predict(x))
plot_data(X_train, y_train)
if __name__ == '__main__':
iris = datasets.load_iris()
# print(dir(iris)) # 查看data所具有的属性或方法
# print(iris.data) # 数据
# print(iris.DESCR) # 数据描述
X = iris.data[:, :2] # 取前2列特征(平面只能展示2维)
y = iris.target # 分类
show_data_set(X, y, iris)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=777) # 默认test比例0.25
test1(X_train, X_test, y_train, y_test, multi_class='ovr', solver='liblinear')
test2(X_train, X_test, y_train, y_test)
test1(X_train, X_test, y_train, y_test, multi_class='multinomial', solver='newton-cg')
test3(X_train, X_test, y_train, y_test)
