机器学习分类实例——SVM
20180423-20180426学习笔记
25去首届数字中国会展参观了,没学习。(想偷懒)由于是最后一天,感觉展出的东西少了,因为24号闭幕了。。。但是可以去体验区。主要体验了VR,其他展出的东西要么没意思,要么看不懂,马云马化腾他们来的时候,我因为要开会,没去看。失去了找他们要签名的机会,唉。

一、工作
主要是学习分类器的一些理论,通过实践,最终得出了结果,虽然结果没那么完美,到底怎么不完美,下面会提到。
1.1学习理论:
因为对这方面的知识,仅限于本科阶段的“人工智能”与“数据挖掘”课程中了解一些,应付考试用。所以真的要运用起来,还真是麻烦。虽说不用理解每个公式,每个数字的含义,但是对整个模型“输入什么”、“输出什么”、“做什么”、“核心思想”等还是需要理解的。
知乎中的高票答案一答主“简之”,把SVM模型的各个部分进行了形象生动的比喻
再之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
通过他的描述,SVM的运行机制可以有个大体的理解。
高票答案二答主“靠靠靠谱”,则进一步详细地介绍了整个模型。由“苹果香蕉”的分类问题,引出SVM的原理,以及其中各个参数的介绍,写得也很好。
知乎链接:支持向量机(SVM)是什么意思?
1.2学习实例:
看了理论,还是挺懵的。本次毕设是采用scikit-learn v0.19.1。去官方查询文档,看如何设置参数、调用函数、输入输出格式等。
官方文档:Support Vector Machines、中文文档:支持向量机, SVM(不用看中文也能明白意思,但一些参数还是无法理解)

搜索到一篇博客,写得很好:Python中的支持向量机SVM的使用(有实例)
文中详细地写了各个参数意义,逐步按照博主的步骤,就能正确分类,并绘出图。
还挺漂亮:
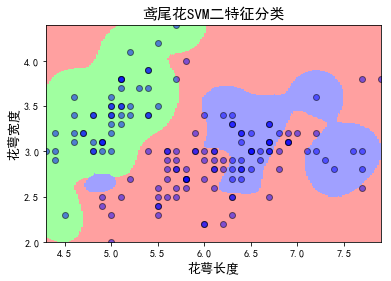
但是我要做的多维特征,所以这种“二特征”绘图不适合我。(老师要求最后用图表来表示判别结果,但是具体怎么表示还没想清楚)
1.3开始编码:
读取文件"test.txt",里面存储的是一系列特征以及三个label值。在我的“非民主相关帖子处理”有test.txt的样式,里面是200个特征以及3个label值。
(1)导入需要的包
import numpy as np
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report(2)读取文件并存储
with open("test.txt","r") as file:
ty=-3 #代表取哪一列label值,-1代表取倒一列所有值
result=[]
for line in file.readlines():
result.append(list(map(str,line.strip().split(','))))
vec = np.array(result)
x = vec[:,:-3]#取除掉最后三列以外的所有列,即所有特征列
y = vec[:,ty]#标签列(3)划分测试集及训练集
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.2)(4)模型训练及预测
clf = SVC(kernel='linear',C=0.4)
clf.fit(train_x,train_y)
pred_y = clf.predict(test_x)
print(classification_report(test_y,pred_y))其中Kernel在参考文档中有介绍,常数C是靠经验得出的数值,并没有具体的公式。不过有关于它设置的一些意义。知乎答主“顾凌峰”是这样介绍C的:
原则上C可以根据需要选择所有大于0的数。
C越大表示整个优化过程中对于总误差的关注程度越高,对于减小误差的要求越高,甚至不惜使间隔减小。
- 当C趋于无穷大时,这个问题也就是不允许出现分类误差的样本存在,那这就是一个hard-margin
- SVM问题当C趋于0时,我们不再关注分类是否正确,只要求间隔越大越好,那么我们将无法得到有意义的解且算法不会收敛。
知乎链接:关于SVM中,对常数C的理解?
(5)训练结果分析
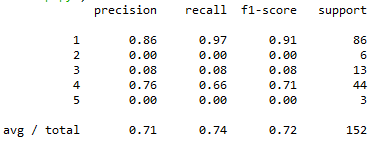
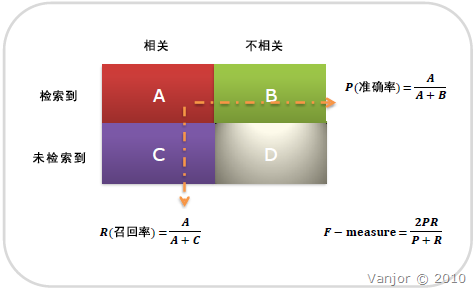
关于函数“classification_report(test_y,pred_y)”介绍以及precision/recall/f1-score的具体含义,详见两篇博客
简单来说就是:
(6)测试文本分析
- 任务是输入一段文本,用jieba找出关键词,把关键词数量选大一些,尽量覆盖全文。(此处用关键词还是用分词存疑)
- 然后再和关键词库比对,得到该文本的特征向量
代码比较简单,和之前的类似:
from openpyxl import load_workbook
from openpyxl import Workbook
import jieba.analyse
wr=load_workbook('sta.xlsx')
osheet=wr.active
orow=osheet.max_row
print(orow)
testL=[]
num=200
tempc=0
for i in osheet["A"]:
if tempc<num:
testL.append(i.value)
else:
break
tempc=tempc+1
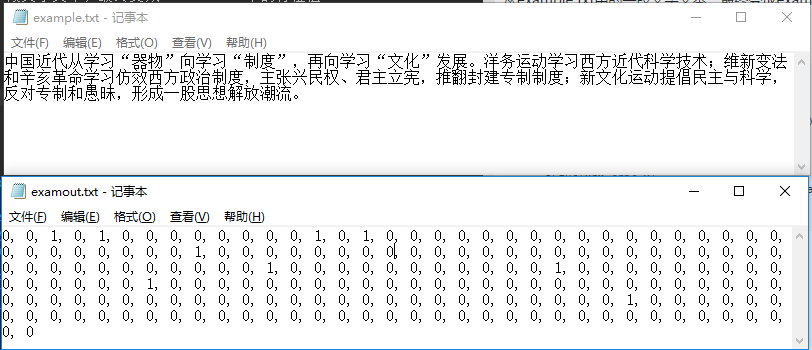
with open("example.txt","r") as f:
ftxt=f.read()
print(ftxt)
content=ftxt
keywords=jieba.analyse.extract_tags(content,topK=1000)
print(keywords)
L3=[]
L2=[]
flag=False
print(testL)
L2=[]
for g in testL:
flag=False
for i in keywords:
if g==i:
flag=True
break
if flag:
L2.append(1)
else:
L2.append(0)
print(L2)
file=open('examout.txt','w')
file.write(str(L2).strip('[').strip(']'))
file.close()
从example.txt中的一段文字文本,最终变成examout.txt中的特征值
(7) 文本特征测试
f = open("examout.txt","r")
newl =f.read()
newl=list(map(str,newl.strip().split(',')))
newv = np.array(newl)
new_test_x = newv[:]
print(new_test_x)
new_pred_y = clf.predict(new_test_x.reshape(1,-1))
print(new_pred_y)输出结果:
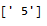
要注意,我们是对单列进行测试。上文中
ty=-3
y = vec[:,ty]表示的是,只对倒数第三列,也就是第一个子话题“民主制度”进行训练。对该文本进行判别,得出的是其在“民主制度”标签下的评分——5分,看来很相关
我的评分制度是1-5,1为不相关,5为很相关。
注意到函数“clf.predict(new_test_x.reshape(1,-1))”,该函数接收的必须是一个二维数组。而特征向量只有一维,所以需要reshape(1,-1)进行转换否则会报错
一点说明:这里只进行了少部分文本的测试,大量文本测试还尚需时日。
二、总结反思
- 实现了SVM并对其有了一定了解,但是内部原理,由于没有时间看相关论文,所以还是不是很懂,毕设做完,在写论文的时候可以多查查相关材料。
- 对scilearn的使用有了比较浅显地理解,并可以熟练地读取文本及表格
- SVM和DecisionTree表现尚可,但是朴素贝叶斯的分类效果就比较差了。。。(三个分类均已做完、限于篇幅只写了SVM,剩下的分类过两天写)
三、接下来的任务
怎么将结果展示出来?该展示那些内容?采用哪种形式?
因为要做三种分类准确度的对比,所以先学习一下Python的表格绘制吧。明天要给学长学姐展示到目前为止所做的工作。