目录
1、DataFrame类型
DataFrame是一个二维数据类型。由多行多列组成,每个列的类型可以不同。DataFrame既有行索引,也有列索引。
行索引和列索引其实都是index,但为了方便区分,创建时用index表示行索引,columns表示列索引,但本质上都是index。
操作DataFrame时需要导入的模块:
import numpy as np
import pandas as pd# 忽略警告
import warnings
warnings.filterwarnings('ignore')
2、DataFrame创建方式
我们可以使用如下的方式创建(初始化)DataFrame类型的对象(常用):
- 二维数组结构(列表,ndarray数组,DataFrame等)类型。
- 字典类型,key为列名,value为一维数组结构(列表,ndarray数组,Series等)。
说明:
- 如果没有显式指定行与列索引,则会自动生成以0开始的整数值索引。我们可以在创建DataFrame对象时,通过index与columns参数指定。
- 可以通过head(n),tail(n)访问前 / 后n行记录(数据)。
- 通过sample(n) 随机抽取n行
- df.index.name = "index_name" ,指定行索引名称
df.columns.name = "columns_name" ,指定列索引名称
案例:
# 使用二维数据结构创建DataFrame。没有指定行列索引,自动生成行列索引。都是从0开始的自然数
array1 = np.random.rand(3, 5)
df = pd.DataFrame(array1)
display(df)
0 1 2 3 4 0 0.878552 0.164219 0.934828 0.762890 0.283276 1 0.783461 0.969697 0.999134 0.557880 0.322521 2 0.775136 0.423268 0.051412 0.063281 0.863997
# 使用字典来创建DataFrame。一个键值对为一列。key指定列索引,value指定该列的值。
df = pd.DataFrame({"贵阳":[101,102,103],"杭州":[201,202,203],"广州":[301,302,303]})
display(df)

df = pd.DataFrame(np.arange(15).reshape((3,5)),index=list("abc"),columns=list("ABCDE")) #指定行列索引
# 显示前N条记录
display(df.head(2))
# 显示后N条记录
display(df.tail(2))
# 随机抽取N条记录
display(df.sample(2))


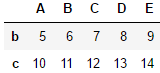
df = pd.DataFrame(np.random.rand(3, 5), index=["地区1", "地区2", "地区3"], columns=["北","上", "广","深", "杭"])
df.index.name = "index_name" #指定行索引名称
df.columns.name = "columns_name" #指定列索引名称
display(df)

df = pd.DataFrame(np.random.rand(3, 5), index=["地区1", "地区2", "地区3"], columns=["北","上", "广","深", "杭"])
# 注意Index首字母大写
idx = pd.Index(["GDP增长", "人口增长", "人才增长"], name = "index_name") #修改行索引index
df.index = idx
display(df)

3、DataFrame相关属性
- index 索引
- columns 列
- values 值
- shape 形状
- ndim 维度
- dtypes 数据类型
说明:
- 可以通过index访问行索引,columns访问列索引,values访问数据,其中index与columns也可以进行设置(修改)。
- 可以为DataFrame的index与columns属性指定name属性值。
- DataFrame的数据不能超过二维。
案例:
df = pd.DataFrame(np.random.rand(3, 5), index=["GDP增长", "人口增长", "人才增长"], columns=["北","上", "广","深", "杭"])
display(df)
display(df.values, type(df.values)) # 返回DataFrame关联的ndarray数组
display(df.index) # 返回行索引
display(df.columns) # 返回列索引
display(df.shape) # 返回形状
display(df.ndim) # 返回维度
display(df.dtypes) # 返回各列的类型信息。
df.index = ["r1", "r2", "r3"] #修改行索引
df.index.name = "index_name" #给行索引起名
df.columns.name = "columns_name" #给列索引起名
display(df)
4、DataFrame相关操作
4.1.列操作
df = pd.DataFrame(np.random.rand(5, 5), columns=list("abcde"), index=list("hijkl"))
display(df)
-
获取列:
- df[列索引]
- df.列索引
- 案例:
# 获取DataFrame的列。通过df[索引]的方式,永远是获取列,不会获取行。【索引永远被解析为是列索引。】
display(df["a"], type(df["a"]))
# 获取列的第二种方式:(建议大家使用前者,因为不受特殊名称的限制。)
display(df.a)
# 获取多个列(返回一个DataFrame,即使只选择一个列)
display(df[["a", "d"]])
-
增加(修改)列:df[列索引] = 列数据
# 增加列
df["f"] = [1, 2, 3, 4, 5]
display(df)
-
修改列
# 修改列 的值
df["e"] = [6, 7, 8, 9, 10]
display(df)
# 修改列
df["f"] = df["a"] + df["b"]
display(df)
-
删除列
- del df[列索引]
- df.pop(列索引)
- df.drop(列索引, inplace=False, axis=1)
- df.drop(列索引数组, inplace=True, axis=1)
- 案例:
# 删除列
df["e"] = [6, 7, 8, 9, 10]
del df["e"]
display(df)
df["e"] = [6, 7, 8, 9, 10] # 把e列加回去
display(df.pop("e")) # 从df中删除e列,会单独返回删除的列e
display(df)
df["e"] = [6, 7, 8, 9, 10] # 把e列加回去
# drop可以删除行,也可以删除列,也可以就地删除
df1 = df.drop("e", inplace=False, axis=1) #删除列
display(df, df1)
df2 = df.drop("h", inplace=False, axis=0) #删除行
display(df, df2)
# 可以指定标签数组,同时删除多列
# 需要注意的是,使用drop()方法返回的是Copy而不是视图,要想真正在原数据里删除行,就要设置inplace=True
df.drop(["a", "e"], inplace=True, axis=1)
display(df)df["e"] = [6, 7, 8, 9, 10]
df["a"] = [1, 2, 3, 4, 5]
4.2.行操作
df = pd.DataFrame(np.random.rand(5, 5), index=list("abcde"), columns=list("yuiop"))
display(df)
-
获取行
- df.loc 根据标签进行索引。
- df.iloc 根据位置进行索引。
- df.ix 混合索引。先根据标签索引,如果没有找到,则根据位置进行索引(前提是标签不是数值类型)。【已不建议使用, 新版本废弃】
- 案例:
# 先获取行,再获取列, 其实loc是从高维到低维逐渐定位的。
display(df.loc["c"]["i"]) #第c行i列的值
display(df.loc["c", "i"]) #第c行i列的值
display(df.loc["c"].loc["i"]) #第c行i列的值
display(df.loc["c"]) # 第c行 ,loc函数是从高维到低维依次定位的。不能不指定高维,直接定位到低维
display(df.loc[:, "i"]) #第i列
# 先获取列,在获取行。
df["i"].loc["a"] = 3
display(df)# 标签索引组定位列,然后loc切片行
display(df[["i", "o", "p"]].loc["b":"d"])
# 注意:df[索引]是对列进行操作。df[切片]是对行进行操作。
# 获取列,永远对列进行操作。
display(df["y"])# df[切片] 说明:df[切片]既可以根据标签索引切片,也可以根据位置索引切片。【先按标签,再按索引,行为类似与ix,故不建议使用。】
display(df["a":"c"])
display(df[0:2])
# 通过布尔数组,是对行进行操作。
bool_array = [True, False, True, True, False]
display(df[bool_array])# 通过标签数组,是对列进行操作。
lable_array = ["y", "i", "p"]
display(df[lable_array])
# 如果布尔数组是二维结构,则True对应的位置元素原样显示,False对应位置的元素置为空值(NaN)
display(df > 0.5)
display(df[df > 0.5])
display(df["i"] > 0.5)
display(df[df["i"] > 0.5])
-
增加行:
append【多次使用append增加行会比连接计算量更大,可考虑使用pd.concat来代替】
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None) 用法 将其他行添加到此DataFrame的末尾,返回一个新对象。 不在此DataFrame中的列将作为新列添加。 参数 other:DataFrame或Series / dict-like对象,或者这些要附加的数据的列表 ignore_index: 布尔值,默认False。如果为真,就不会使用索引标签。 例如: >>> df = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB')) >>> df A B 0 1 2 1 3 4 ignore_index=False >>> df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB')) >>> df.append(df2) A B 0 1 2 1 3 4 0 5 6 1 7 8 ignore_index=True >>> df.append(df2, ignore_index=True) A B 0 1 2 1 3 4 2 5 6 3 7 8 # 增加一行 df = pd.DataFrame(np.random.rand(5, 5), columns=list("abcde"), index=list("hijkl")) display(df) line = pd.Series([23, 33, 12., 334.22, 200], index=list("abcde"), name="p") df = df.append(line) display(df)
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) 参数说明 : objs: series,dataframe或者是panel构成的序列lsit axis: 需要合并链接的轴,0是行,1是列 join:连接的方式 inner,或者outer 其他一些参数不常用。
-
修改行
df = pd.DataFrame(np.random.rand(5, 5), columns=list("abcde"), index=list("hijkl"))
display(df)
#注意:列索引本质上也是index,columns只是创建时为了区分
# 修改行
df.loc["k"] = pd.Series([1,1,1,1,1], index=list("abcde"))
display(df)
-
删除行
- df.drop(行索引或数组)
- df.drop(列索引, inplace=False/True, axis=0)
- df.drop(列索引数组, inplace=False/True, axis=0)
df.drop(["a","b"])
df.drop("c", inplace=True, axis=0) #True删除原始数据
df.drop(["d","e"], inplace=True, axis=0) #True删除原始数据
4.3.行列混合操作综合应用(重点):
- 先获取行,再获取列。
- 先获取列,在获取行。
说明:
- drop方法既可以删除行,也可以删除列,通过axis指定轴方向。【可以原地修改,也可以返回修改之后的结果。】
- 通过df[索引]访问是对列进行操作。
- 通过df[切片]访问是对行进行操作。【先按标签,然后按索引访问。如果标签是数值类型,则仅会按标签进行匹配。】
- 通过布尔索引是对行进行操作。
- 通过数组索引是对列进行操作。
这个地方重点区分,极易混淆。
换种方式进行总结:
- 行操作:切片 和 布尔数组
- 列操作:索引 和 标签数组/位置数组
案例:
import pandas as pd
import numpy as np#准备数据
data = {'name': ['jalen', 'xr', 'jalenbig', 'bigdata', 'ajalen', 'bjalen', 'cjalen', 'djalen', 'ejalen', 'fjalen'],
'age': [25, 32, 18, np.nan, 15, 20, 41, np.nan, 37, 32],
'gender': [1, 0, 1, 1, 0, 1, 0, 0, 1, 0],
'isMarried': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(data, index=labels)
display(df)
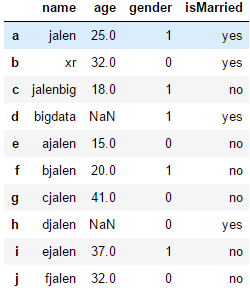
#获取指定行
display(df.loc["a"]) #第a行
display(df.loc[["a","d"]]) #第a、d行
display(df.iloc[0]) #第0行
display(df["a":"a"]) #第a行到第a行
display(df["c":"e"]) #第c行到第e列
display(df[df["age"] > 25]) #获取age>25
#获取指定列
display(df["age"])
display(df[["name","gender"]])
# 混合使用1
display(df.loc["c"]["age"]) #第c行age列的值
display(df.loc["c", "age"]) #第c行age列的值
display(df.loc["c"].loc["age"]) #第c行i列的值
display(df.loc[:, "i"]) #第i列
# 混合使用2
display(df["name"].loc["a"]) #第name列第a行
display(df.loc["a":"c", ["name", "age"]]) #a到c行,name和age列
display(df.loc[df["age"]>25,["name", "age"]]) #age>25的行,name和age列
display(df.ix[2,'name']) # 第2行第name列
display(df.at["b", "age"]) # 第b行第age列
display(df.iat[1, 1]) #第1行第1列
总结
1)选取某一整行(多个整行)或某一整列(多个整列)数据时,可以用df[]、df.loc[]、df.iloc[],此时df[]的方法书写要简单一些。
2)进行区域选取时,如果只能用标签索引,则使用df.loc[]或df.ix[],如果只能用整数索引,则用df.iloc[]或df.ix[]。不过我看到有资料说,不建议使用df.ix[],因为df.loc[]和df.iloc[]更精确(有吗?我没理解精确在哪,望告知)。
3)如果选取单元格,则df.at[]、df.iat[]、df.loc[]、df.iloc[]都可以,不过要注意参数。
4)选取数据时,返回值存在以下情况:
如果返回值包括单行多列或多行单列时,返回值为Series对象; 如果返回值包括多行多列时,返回值为DataFrame对象; 如果返回值仅为一个单元格(单行单列)时,返回值为基本数据类型,例如str,int等。
5)df[]的方式只能选取行和列数据,不能精确到单元格,所以df[]的返回值一定DataFrame或Series对象。
6)当使用DataFrame的默认索引(整数索引)时,整数索引即为标签索引。
4.4.DataFrame结构
DataFrame的一行或一列,都是Series类型的对象。
对于行来说,Series对象的name属性值就是行索引名称,其内部元素的值,就是对应的列索引名称。
对于列来说,Series对象的name属性值就是列索引名称,其内部元素的值,就是对应的行索引名称。
# DataFrame的每一行,或每一列,都是Series类型
df = pd.DataFrame([[1, 2], [3, 4]], columns=["a", "b"])
display(df)
display(type(df["a"]), df["a"])
display(type(df.loc[0]), df.loc[0])
4.5.DataFrame运算(重点)
DataFrame的一行或一列都是Series类型的对象。因此,DataFrame可以近似看做是多行或多列Series构成的,Series对象支持的很多操作,对于DataFrame对象也同样适用,我们可以参考之前Series对象的操作。
- 转置
df = pd.DataFrame(np.arange(12).reshape(3, 4))
# 转置
display(df, df.T)
- DataFrame进行运算时,会根据行索引与列索引进行对齐。当索引无法匹配时,产生空值(NaN)。如果不想产生空值,可以使用DataFrame提供的运算函数来代替运算符计算,通过fill_value参数来指定填充值。
df1 = pd.DataFrame(np.arange(9).reshape(3, 3))
df2 = pd.DataFrame(np.arange(9, 18).reshape(3, 3))
display(df1, df2)
display(df1 + df2)
display(df1 * df2)
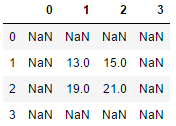
df2 = pd.DataFrame(np.arange(9).reshape(3, 3))
df3 = pd.DataFrame(np.arange(9, 18).reshape(3, 3), index=[1, 2, 3], columns=[1, 2, 3])
display(df2, df3)# DataFrame进行计算时,会根据标签进行对齐,如果标签无法对齐,则会产生空值(NaN)。
display(df2 + df3)# 如果不想结果为NaN,可以采用DataFrame提供的计算方法,来代替运算符的计算。
# 如果参与运算的二者都是NaN,那么就不能生效
display(df2.add(df3, fill_value=1000))
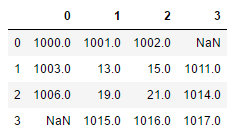
- DataFrame与Series混合运算。【默认Series索引匹配DataFrame的列索引,然后进行行广播。可以通过DataFrame对象的运算方法的axis参数,指定匹配方式(匹配行索引还是列索引)。】
# Series与DataFrame混合运算,运算时会【根据标签进行对齐】。
df = pd.DataFrame(np.arange(12).reshape(4, 3))
ss = pd.Series([1000, 2000, 3000])
display(df, ss)
display(df + ss)


# 当进行混合运算时,默认情况下,Series用自己的标签匹配DataFrame的列标签,然后进行运算。
# 如果需要匹配行标签,则可以使用axis进行设置。
df = pd.DataFrame(np.arange(9).reshape(3, 3))
s1 = pd.Series([1000, 2000, 3000])
display(df.add(s1, axis="index"))df = pd.DataFrame(np.arange(9).reshape(3, 3))
s2 = pd.Series([1000, 2000, 3000], index=[0, 1, 2])
display(df.add(s2))


4.6.DataFrame排序(重点)
索引排序
Series与DataFrame对象可以使用sort_index方法对索引进行排序。DataFrame对象在排序时,还可以通过axis参数来指定轴(行索引还是列索引)。也可以通过ascending参数指定升序还是降序。
df = pd.DataFrame(np.random.random((3, 5)), index=[3,1,2], columns=[1,3,5,2,4])
display(df)
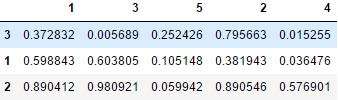
# 默认根据行索引进行排升序。
df1 = df.sort_index()
display(df1)

# 指定按照行索引排序 axis=0 ,列索引排序axis=1,ascending=False降序True升序
display(df.sort_index(axis=0, ascending=False))

值排序
Series与DataFrame对象可以使用sort_values方法对值进行排序。
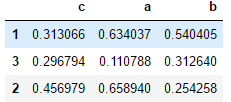
df = pd.DataFrame(np.random.random((3,3)), index=[1,3,2], columns=list("cab"))
display(df)

# 按照列排序,指定顺序
df1 = df.sort_values("c", ascending=False)
display(df1)

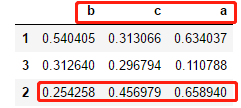
df = pd.DataFrame(np.random.random((3,3)), index=[1,3,2], columns=list("cab"))
display(df)
# 按照行排序,指定顺序(行不变,列排序,当然axis=1)
df2 = df.sort_values(2, axis=1, ascending=True)
display(df2)
df = pd.DataFrame([[1, 3, 300], [66, 5, 100], [1, 3, 400]])
display(df)
# 先按照第1列,再按照第2列
df3 = df.sort_values([1, 2])
display(df3)


4.7.DataFrame索引对象Index
Series(DataFrame)的index或者DataFrame的columns就是一个索引对象。
- 索引对象可以向数组那样进行索引访问。
- 索引对象是不可修改的。
idx = pd.Index([1, 2, 3])
# 支持通过下标来访问
display(idx[0])
# 索引对象的元素不支持修改。下面两句代码都会报错
# ind[0] = 30
# df.index = []
4.8.DataFrame统计相关方法(重点)
- mean / sum / count
- max / min
- cumsum / cumprod
- argmax / argmin
- idxmax / idxmin
- var / std
df = pd.DataFrame(np.random.rand(3, 4), index=[0, 1, 2], columns=list("abcd"))
df.loc[0:2:2,"a"] = np.nan
display(df)

# count 统计不包含 nan。
display(df.count(axis=0)) # 默认按照 列 统计非nan的值的个数
display(df.count(axis=1)) # 按照 行 统计非naa的值的个数


df = pd.DataFrame(np.floor(10 * np.random.rand(3, 3)), index=["a", "b", "c"], columns=["d", "e", "f"], dtype=np.int32)
#display(df)#默认按照列统计,同时不统计NaN的值
display(df.sum())
display(df.mean())
display(df.max())
display(df.min())
display(df.count())





df = pd.DataFrame(np.floor(10 * np.random.rand(3, 3)), index=["a", "b", "c"], columns=["d", "e", "f"], dtype=np.int32)
display(df)
display(df.cumsum())
display(df.cumprod())



df = pd.DataFrame(np.floor(10 * np.random.rand(3, 3)), index=["a", "b", "c"], columns=["d", "e", "f"], dtype=np.int32)
display(df)
display(df.idxmax())
display(df.idxmin())


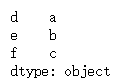
4.9.unique 和 value_counts
- unique
- value_counts
# Series unique 去掉重复的元素。(没有排序的功能) s = pd.Series([3, 1, 2, 3]) display(s.unique()) array([3, 1, 2], dtype=int64) # 按Series的值进行分组,分别统计该值出现的数量。 s = pd.Series([4, 5, 6, 4, 6, 4]) result = s.value_counts() display(result) 4 3 6 2 5 1 dtype: int64
