1 模型选择
1.1 数据集
- 验证数据集:一个用来评估模型好坏的数据集
- 例如拿出50%的训练数据
- 不要跟训练数据混在一起
- 测试数据集:只用一次的数据集
- 未来的考试
- 用在Kaggle私有排行榜中的数据集
1.2 K折交叉验证
当训练数据稀缺时,我们甚⾄可能⽆法提供⾜够的数据来构成⼀个合适的验证集。这个问题的⼀个流⾏的解决⽅案是采⽤K折交叉验证。
这⾥,原始训练数据被分成K个不重叠的⼦集。然后执⾏K次模型训练和验证,每次在K - 1个⼦集上进⾏训练,并在剩余的⼀个⼦集(在该轮中没有⽤于训练的⼦集)上进⾏验证。
最后,通过对K次实验的结果取平均来估计训练和验证误差。
2 过拟合和欠拟合
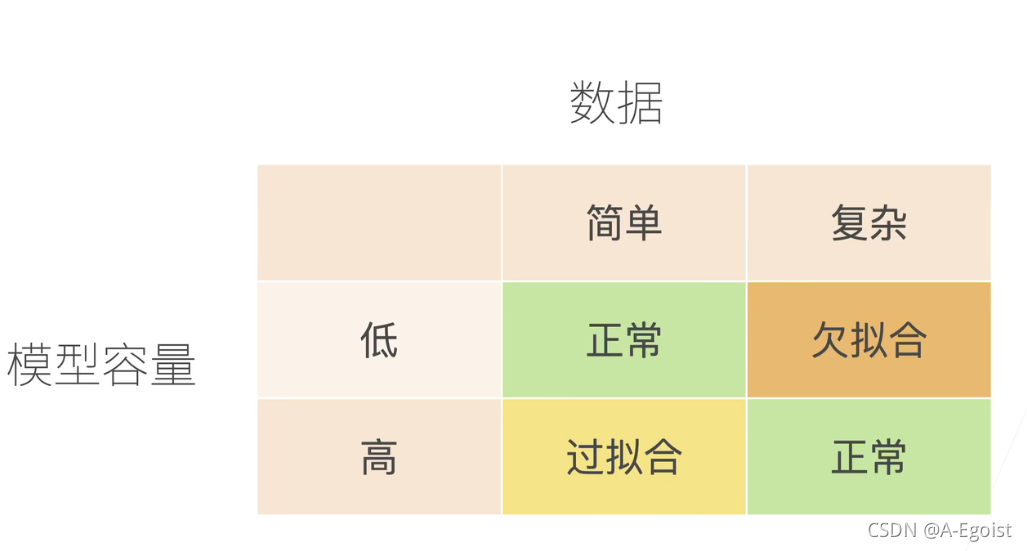
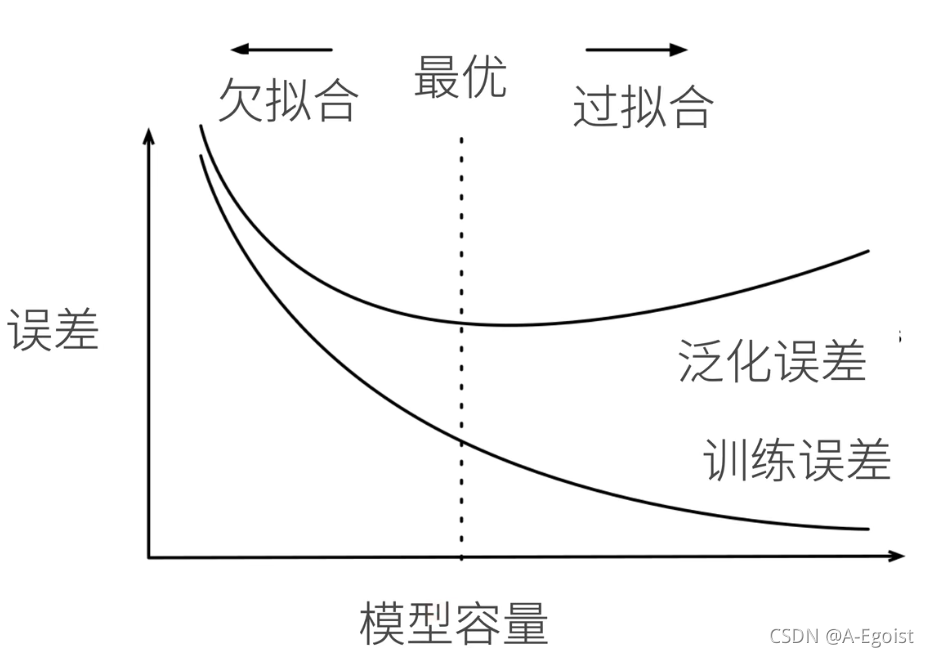
2.1 模型容量
- 模型容量的影响
2.2 数据复杂度
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性
2.3 总结
- 模型容量需要匹配数据复杂度,否则可能会导致欠拟合和过拟合
- 统计机器学习提供数学工具来衡量模型复杂度
- 实际中一般靠观察训练误差和验证误差