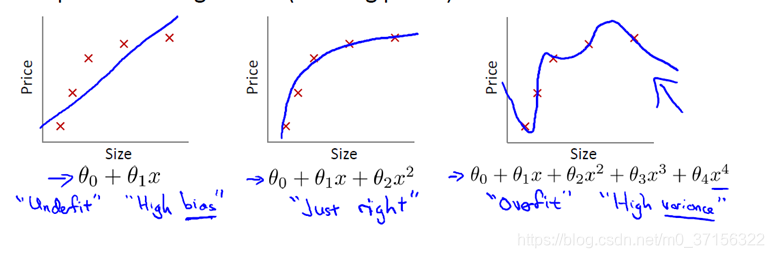
过拟合:
过拟合(over-fitting)是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳的现象。就像上图中右边的情况。
过拟合的模型太过具体从而缺少泛化能力,过度的拟合了训练集中的数据。出现的原因是模型将其中的不重要的变量(特征)或者完全没有用的变量(特征)也当作了需要训练的数据。当变量(特征)过多,而训练集较少的时候会出现过拟合的现象。
欠拟合:
欠拟合(underfitting)是模型在训练集和测试集表现都不好的现象,模型没有很好的拟合训练数据。如上图中左边的情况。
欠拟合比较容易看出来,可添加特征多项式解决,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
过拟合的解决方案:正则化
以岭回归为例:
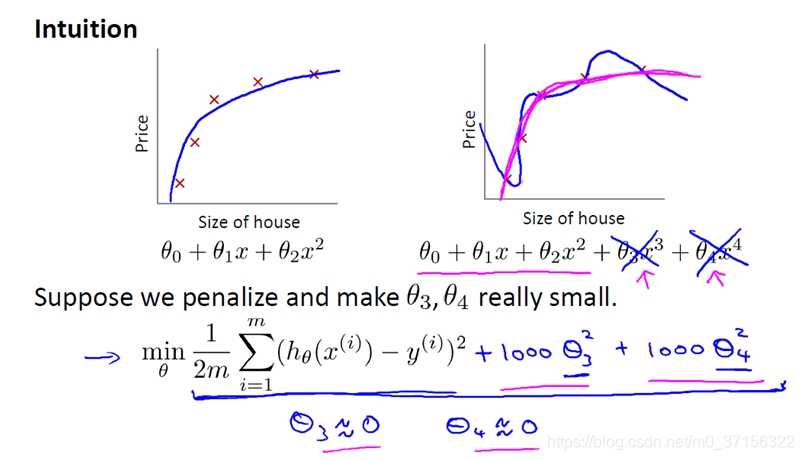
例如上图,一个二次函数就能很好的拟合数据。
通过在损失函数中,给高次项系数添加一个比较大的惩罚系数(1000只是举的例子),这样对损失函数求最小值的时候,使得θ3θ4的值就会很小,接近于0但不会为0( 因为添加的是平方的形式)。
实际上,这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此 就不易发生过拟合的问题。
在实际操作中,我们可以选择一些变量(特征)中影响比较小的添加惩罚系数就可以减少该变量(特征)的影响。
一般我们不知道那些系数应该缩减,因此,我们需要修改代价函数,在这后面添加一项,就像我们在方括号里的这项。当我们添加一个额外的正则化项的时候,我们收缩了每个参数。
这就是岭回归的损失函数:
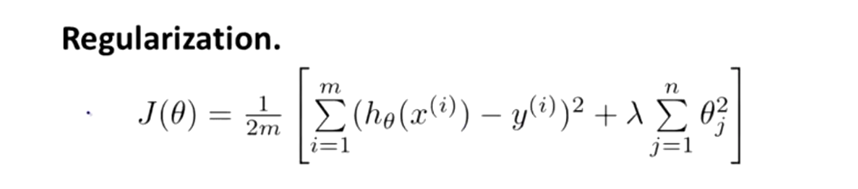
其中θ是从1开始的,没有加第0项,惯例来讲是不带第0项。因为从第1项到第n项求和从第0项到第n项求和只有很小的差异。
L2正则化
这里我们加的正则化项是L2正则化项
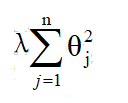
L1正则化项
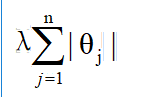
L1正则化项也能起到缩减不必要系数的作用。θ会缩小到0
总结:
- 岭回归可以解决特征数量比样本量多的问题
- 岭回归作为一种缩减算法可以判断哪些特征重要或者不重要,有点类似于降维的效果
- 缩减算法可以看作是对一个模型增加偏差的同时减少方差
岭回归用于处理下面两类问题:
- 数据点少于变量个数
- .变量间存在共线性(最小二乘回归得到的系数不稳定,方差很大)