Hive 简介
1、Hive 由 Facebook 实现并开源
2、是基于 Hadoop 的一个数据仓库工具
3、可以将结构化的数据映射为一张数据库表
4、并提供 HQL(Hive SQL)查询功能
5、底层数据是存储在 HDFS 上
6、Hive的本质是将 SQL 语句转换为 MapReduce 任务运行
7、使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
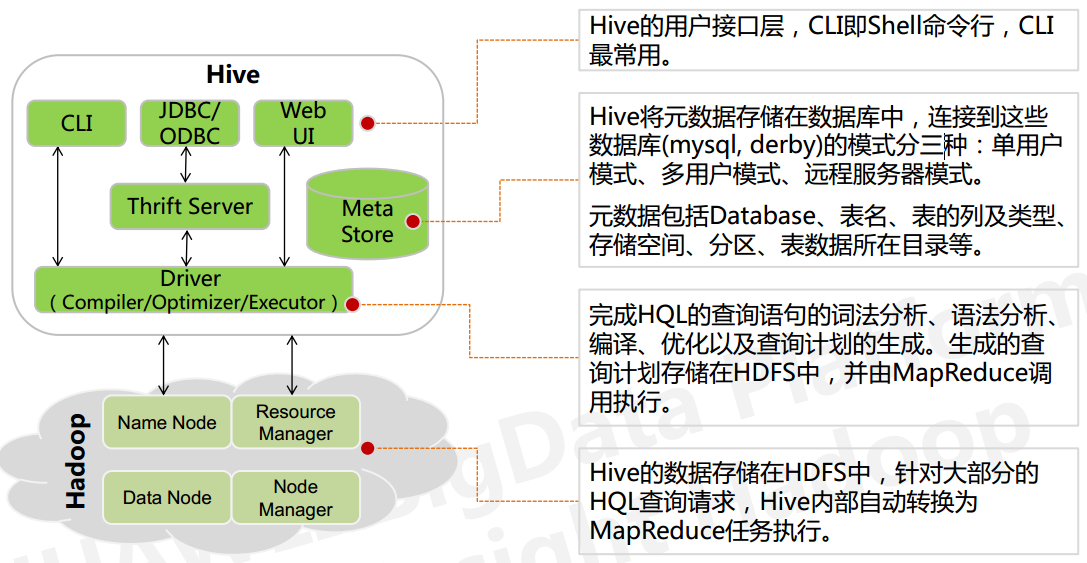
Hive的架构
Hive中表的分类
- 内部表
- 外部表
- 分区表
- 桶表
内部表:什么是内部表需要对比外部表来看
•删表时数据和表一起删除
外部表:
•数据已经存在于HDFS
•外部表只是走一个过程,加载数据和创建表同时完成,不会移动到数据仓库目录中,仅仅是和数据建立了一个连接
•删表数据不会删除数据
内部表外部表区分:
在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而内部表表则不一样;在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
分区表:
•在Hive Select查询中,一般会扫描整个表内容,会消耗很多时间做没必要的工作。 分区表指的是在创建表时,指定partition的分区空间。扫描时可以只扫描某一个分区的数据
•分区表存储时分局所设立的分区分别存储数据(分区字段就是一个文件夹的标识)
桶表
•对于每一个表(table)或者分区,Hive可以进一步组织成桶,也就是说捅是更为细粒度的数据范困划分。
•桶表是对指定的分桶的列进行哈希运算,运算结果模(%)分桶的数量然后把数据根据运算结果分别放入这几个桶中
Hive的DDL操作
1、创建库
语法结构
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] //关于数据块的描述
[LOCATION hdfs_path] //指定数据库在HDFS上的存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性