一. 前言
此次作业共可分为4个部分,前三个部分是利用支持向量机和高斯来对数据集进行分类,类似前几章的逻辑回归,第四部分是对垃圾邮件进行分类,理论什么的可以看看大神的笔记,讲的比较细致,数据集分别是ex6data(1-3),spainTest,spainTrain
二.代码部分
1)ex6data1.mat(第一部分)
1.导入常规的工具包
这次需要用到pandas中的pd.DataFrame()的方法,将数据集整合到一起并且准确找出特征值,sklearn工具包中包括了许多高级算法,支持向量机与高斯就在其中
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm2.提取数据
这里提取出数据并查看了X,y的维度,这里将X,y整合到一起,对X的特征值,也就是X的每一列进行命名,为了后面画图做铺垫
# 提取数据 ex6data1.mat
data1 = loadmat('ex6data1.mat')
X = data1['X'] # 维度为(51 * 2)
y = data1['y'] # 维度为(51 * 1)
# 利用pd.dataframe函数将X和y整合到一起,方便画图等操作
data_X_y = pd.DataFrame(X, columns=['X1', 'X2'])
# 添加y一列
data_X_y['y'] = y
# print(data_X_y)
# print(X.shape, y.shape)
下面是整合后的形状

3.画出数据集的散点图
首先分别找出y为0与y为1的行,然后找出与其对应的俩个特征值X1,X2,将俩个特征值当作横坐标与纵坐标,设置成不同的颜色和符号以便看清
# 正值和负值的分布图
def plot_diagram(data_X_y):
plt.figure(figsize=(15, 8))
real = data_X_y['y'].isin([1]) # 找出y里面等于1的所有项
fake = data_X_y['y'].isin([0]) # 找出y里面等于0的所有项
# real,fake可以看成一个集合里面存放着true和false,之后在下面data_X_y套用之后会默认
# 匹配拥有true的所有行索引
print(data_X_y[real])
plt.scatter(data_X_y[real]['X1'],data_X_y[real]['X2'],s = 150,marker='+',c='r',label = 'real')
plt.scatter(data_X_y[fake]['X1'],data_X_y[fake]['X2'],s = 150,marker='*',c='b',label = 'fake')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend()
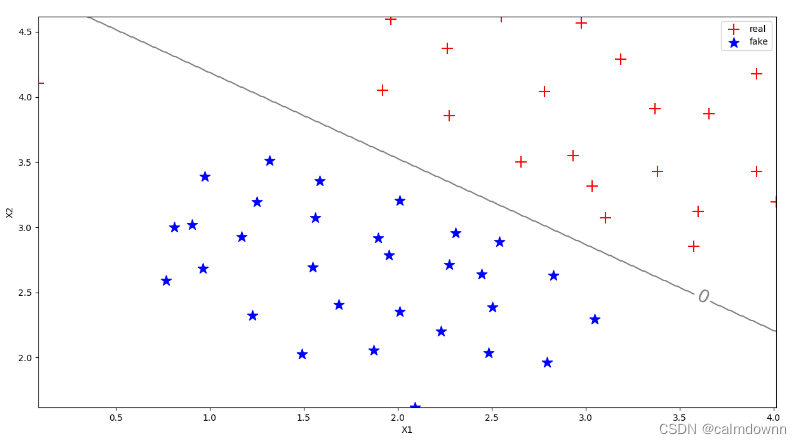
pass图片如下:注意看图片的左上角有一个数据集有很严重的偏差,后面可通过参数C来调整

4.创建SVC模型
这里用了支持向量机的方法,svm.SVC(),svc.fit(),svc.predict(),svc.score()我说一下我自己的理解
svm.SVC():
C:参数C可以理解为惩罚函数,看成C = (1/lamda),当C非常大的时候,其后面的损失函数会无限接近于0,导致出现高方差(过拟合)的状态,相反当C非常小的时候,会出现高偏差(欠拟合)的状态
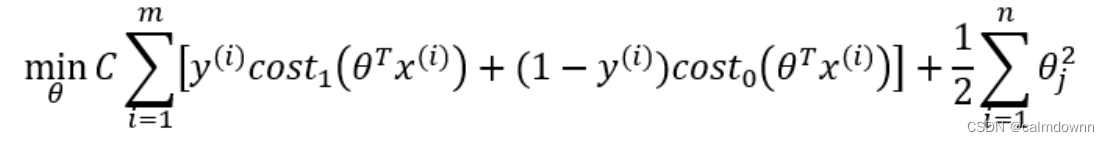
kernel: kernel这个参数其实就是选择不同的内核,比如里面有高斯函数,sigmod函数,线性函数,这里所用的linear就是线性函数,因为我们要画的是一条直线作为分界线
svc.fit():
如果说svm.SVC是建造一个模型的话,那么svm.fit()就是将数据集放入刚刚建造好的模型中进行拟合操作,其中的俩个参数分别是原数据集的特征值与预测结果
svc.predict():
进行拟合之后,模型已装载完毕,这个函数可以给出当前所需要的数据集的预测结果,比如输入训练集的特征值,返回的是一个一维数组,里面存放着所有的预测值,运行如下:
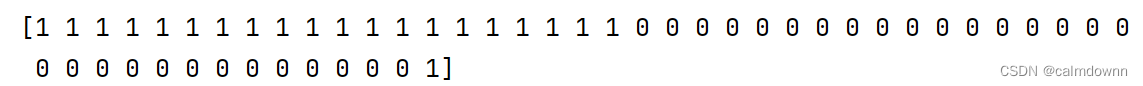
svc.score():
这个函数我认为就是上面在进行predict方法之后,得到的一维预测数组来与本来的结果进行比较,看看到底命中了多少,也就是正确率能达到多少,这个数值当然越高越好
# 下面创建svc模型
svc1 = svm.SVC(C=1.0,kernel='linear')
# 进行模型拟合
svc1.fit(data_X_y[['X1','X2']],data_X_y['y'])
# 看一下模型预测的结果
result = svc1.predict(data_X_y[['X1','X2']])
print(result)
# 看看预测的分数也就是预测的准确率
predict_odd = svc1.score(data_X_y[['X1','X2']],data_X_y['y'])
print(predict_odd)5.绘制边界图
绘制边界图用到了等高线图,也就是超平面图,这个我理解的也不是非常透彻,说一下我理解的:
首先要绘制等高线图,需要三个坐标,x,y,代表的是横纵坐标,z代表的是高度。其次,需要将x,y汇聚成一张网格,就是生成横纵坐标的每一个点,这里举个例子:(x = [1,2,3] , y = [4,5,6],汇聚成网格之后:(1,4),(1,5),(1,6),(2,4),(2,5),(2,6),(3,4),(3,5),(3,6))。可以看出x,y形成了一张大网,z就是在这张大网上凸起的点也就是高度。np.meshgrid(x,y)用来汇聚大网,此函数返回的是俩个变量xx,yy存放的都是网格的横纵坐标。 在求预测数组z时候需要将俩个特征值降维并合并,np.c_会默认将俩个一维数组先变成列向量并合并在一起,在进行预测之后别忘了把z也进行网格化,plt.contour()只接受二维
下面说一下这个过程中xx,yy,z的维度变化
np.linspace()初始化xx,yy,这时候他们的维度为(500,),np.meshgrid()网格化之后xx,yy的维度为(500*500),svc.predict()函数当中对xx,yy进行降维,这时维度为(250000,),在通过np.c_()函数进行合并成维度(250000*2,得到z的维度为(250000,),z也进行网格化最后也成为(500*500)
# 绘制边界图
def plot_bandary(svc1,data_X_y):
X1_min = np.min(data_X_y['X1'])
X1_max = np.max(data_X_y['X1'])
X2_min = np.min(data_X_y['X2'])
X2_max = np.max(data_X_y['X2'])
xx = np.linspace(X1_min,X1_max,500)
yy = np.linspace(X2_min,X2_max,500)
xx1,yy1 = np.meshgrid(xx,yy) # 变成网格(500*500),方便后面画等高线图
# 这里np.c_的方法是把列进行和并,因为这俩都是一维数组,所以是先将俩个一维数组变成列向量在进行合并
z = svc1.predict(np.c_[xx1.flatten(), yy1.flatten()]) # 利用np.c_来进行合并,将xx,yy俩个(500,500)降成一维(250000,)并且合并成(250000*2)
z = z.reshape(xx1.shape) # 这里得到的预测数组维度是(250000,)将其也换成网格,配合等高线
C=plt.contour(xx1,yy1,z,levels = [-1,0,1],colors='gray')
plt.clabel(C, inline=True, fontsize=20)
pass边界图如下:这是C=1.0的图像,可以看出惩罚并不是很强烈,左上角的正值被分配到了下方,牺牲了这一个点却提高了整体分类的适应性,如果再加入其他的特征值,那么大概率会落到正确的乙方,分界线留给俩边的空间很大,可操作性更强,下面看一下C=100时候的图像
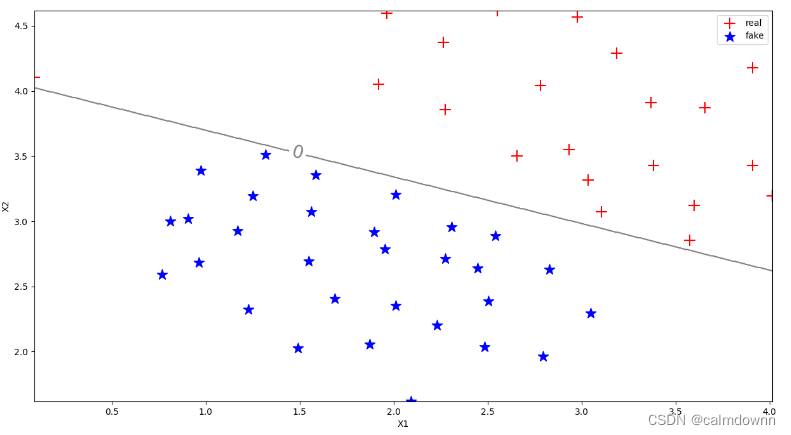
C=100时的图像为下:
可以看到左上角也被完美的分开来了,但是这样真的好吗,一旦添加新的数据集,那么这个分界线还能够很好的分类了吗,这个就是过拟合的状态,也就是高方差
2)ex6data2.mat(第二部分与第一部分大体相同)(第二部分)
前言:这部分主要是为了用高斯内核来做非线性分类,以及看C与gama对模型预测的影响(高偏差/高方差)
1.导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm2.提取数据
# 提取数据 ex6data2.mat
data2 = loadmat('ex6data2.mat')
# 看一下数据集二的建值
# print(data2.keys()) # X,y
X = data2['X']
y = data2['y']
# 还是将X1,X2,y整合到一起
data2_X_y = pd.DataFrame(X, columns=['X1', 'X2'])
data2_X_y['y'] = y3.数据散点图
# 正值和负值的分布图
def plot_diagram(data_X_y):
plt.figure(figsize=(15, 8))
real = data_X_y['y'].isin([1]) # 找出y里面等于1的所有项
fake = data_X_y['y'].isin([0]) # 找出y里面等于0的所有项
# real,fake可以看成一个集合里面存放着true和false,之后在下面data_X_y套用之后会默认
# 匹配拥有true的所有行索引
plt.scatter(data_X_y[real]['X1'], data_X_y[real]['X2'], s=150, marker='+', c='r', label='real')
plt.scatter(data_X_y[fake]['X1'], data_X_y[fake]['X2'], s=150, marker='*', c='b', label='fake')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend()
pass图像如下:
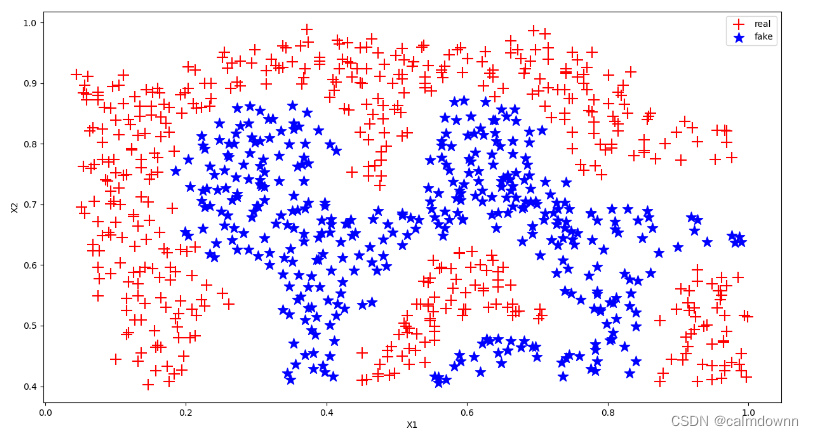
4.构建向量机模型
注意:这里和第一个部分的区别在于SVC()方法里面并没有了kernel参数,所以这里kernel参数默认为'rbl'也就是高斯内核,用于非线性分割
# 下面创建svc模型
svc1 = svm.SVC(C=10,gamma=20)
# 进行模型拟合
svc1.fit(data2_X_y[['X1','X2']],data2_X_y['y'])
# 看一下模型预测的结果
result = svc1.predict(data2_X_y[['X1','X2']])
print(result)
# 看看预测的分数也就是预测的准确率
predict_odd = svc1.score(data2_X_y[['X1','X2']],data2_X_y['y'])
print(predict_odd)5.边界图
def plot_bandary(svc1, data_X_y):
X1_min = np.min(data_X_y['X1'])
X1_max = np.max(data_X_y['X1'])
X2_min = np.min(data_X_y['X2'])
X2_max = np.max(data_X_y['X2'])
xx = np.linspace(X1_min, X1_max, 500)
yy = np.linspace(X2_min, X2_max, 500)
xx1, yy1 = np.meshgrid(xx, yy) # 变成网格(500*500),方便后面画等高线图
# 这里np.c_的方法是把列进行和并,因为这俩都是一维数组,所以是先将俩个一维数组变成列向量在进行合并
z = svc1.predict(np.c_[xx1.flatten(), yy1.flatten()]) # 利用np.c_来进行合并,将xx,yy俩个(500,500)降成一维(250000,)并且合并成(250000*2)
z = z.reshape(xx1.shape) # 这里得到的预测数组维度是(250000,)将其也换成网格,配合等高线
C = plt.contour(xx1, yy1, z, colors='gray')
plt.clabel(C, inline=True, fontsize=20)
pass图片如下,这里C=10,接下来看看C=1.0
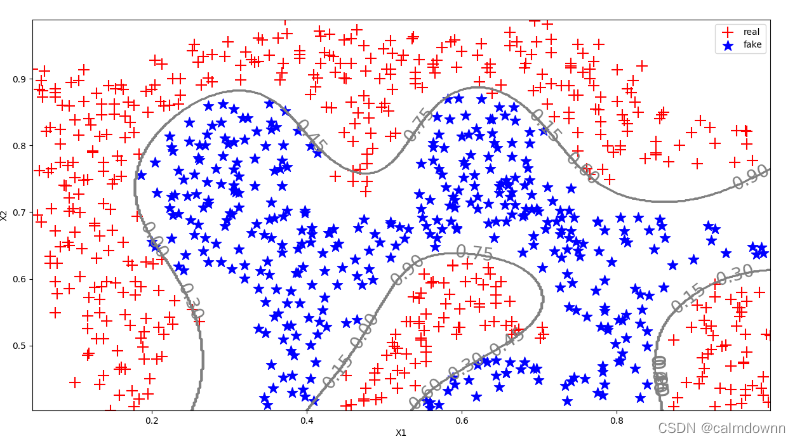
C=0.1,gama = 10 的图像:
可以明显看出欠拟合了

3)ex6data3.mat(主要任务:选出最优的C与gama)(第三部分)
前言:主要目的是在一堆C与gama中找出最好的模型参数,将之用到测试集当中,并画出边界图
1.导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm2.取出数据
# 提取数据 ex6data1.mat
data3 = loadmat('ex6data3.mat')
# 看一下数据集三的建值
# print(data2.keys()) # X,y,yval,Xval
X = data3['X']
y = data3['y']
X_val = data3['Xval']
y_val = data3['yval']
# 将X1,X2,y整合到一起
data3_X_y = pd.DataFrame(X, columns=['X1', 'X2'])
data3_X_y['y'] = y
# 将X1_val,X2_val,y_val整合到一起
data3_X_y_val = pd.DataFrame(X_val, columns=['X1_val', 'X2_val'])
data3_X_y_val['y_val'] = y_val3.数据散点图
# 正值和负值的分布图
def plot_diagram(data_X_y):
plt.figure(figsize=(15, 8))
real = data_X_y['y'].isin([1]) # 找出y里面等于1的所有项
fake = data_X_y['y'].isin([0]) # 找出y里面等于0的所有项
# real,fake可以看成一个集合里面存放着true和false,之后在下面data_X_y套用之后会默认
# 匹配拥有true的所有行索引
plt.scatter(data_X_y[real]['X1'], data_X_y[real]['X2'], s=150, marker='+', c='r', label='real')
plt.scatter(data_X_y[fake]['X1'], data_X_y[fake]['X2'], s=150, marker='*', c='b', label='fake')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend()
pass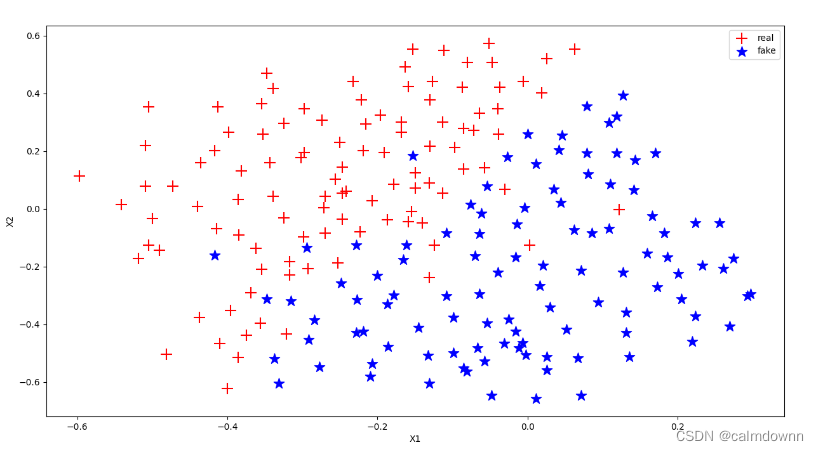
4.绘制边界图
这个先不展示了,在下面选出最优的C与gama再调用这个方法
# 绘制边界图
def plot_bandary(svc1, data_X_y):
X1_min = np.min(data_X_y['X1_val'])
X1_max = np.max(data_X_y['X1_val'])
X2_min = np.min(data_X_y['X2_val'])
X2_max = np.max(data_X_y['X2_val'])
xx = np.linspace(X1_min, X1_max, 500)
yy = np.linspace(X2_min, X2_max, 500)
xx1, yy1 = np.meshgrid(xx, yy) # 变成网格(500*500),方便后面画等高线图
# 这里np.c_的方法是把列进行和并,因为这俩都是一维数组,所以是先将俩个一维数组变成列向量在进行合并
z = svc1.predict(np.c_[xx1.flatten(), yy1.flatten()]) # 利用np.c_来进行合并,将xx,yy俩个(500,500)降成一维(250000,)并且合并成(250000*2)
z = z.reshape(xx1.shape) # 这里得到的预测数组维度是(250000,)将其也换成网格,配合等高线
C = plt.contour(xx1, yy1, z, colors='gray')
plt.clabel(C, inline=True, fontsize=20)
pass5..选出最适合的C与gama
这里建造俩个列表,分别用来存放需要测试的C与gama的数值,用一个二重循环试变所有的C与gama的组合,在进行测试时,对其进行评测也就是svc.score()的方法,选出评分最高的一组C与gama的组合记录并返回
# 下面分别测试C和gama最合适的选值
def test_best_Cgama(data3_X_y, data3_X_y_val):
C_list = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
gama_list = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
best_score = 0
best_C = 0
best_gama = 0
for i in C_list:
for j in gama_list:
svc1 = svm.SVC(C=i, gamma=j)
svc1.fit(data3_X_y[['X1', 'X2']], data3_X_y['y'])
recent_score = svc1.score(data3_X_y_val[['X1_val', 'X2_val']], data3_X_y_val['y_val'])
if (recent_score > best_score):
best_score = recent_score
best_C = i
best_gama = j
pass
return best_C, best_gama, best_score
pass下面将选出的最优C与gama的支持向量机模型带入边界图中
best_C, best_gama, best_score = test_best_Cgama(data3_X_y, data3_X_y_val)
print(f"C:{best_C} best_gama:{best_gama} best_score:{best_score}")
svc1 = svm.SVC(C=best_C, gamma=best_gama)
svc1.fit(data3_X_y[['X1', 'X2']], data3_X_y['y'])
plot_diagram(data3_X_y)
plot_bandary(svc1, data3_X_y_val)
plt.show()最优C,gama以及评分如下 :
![]()
分解图如下:
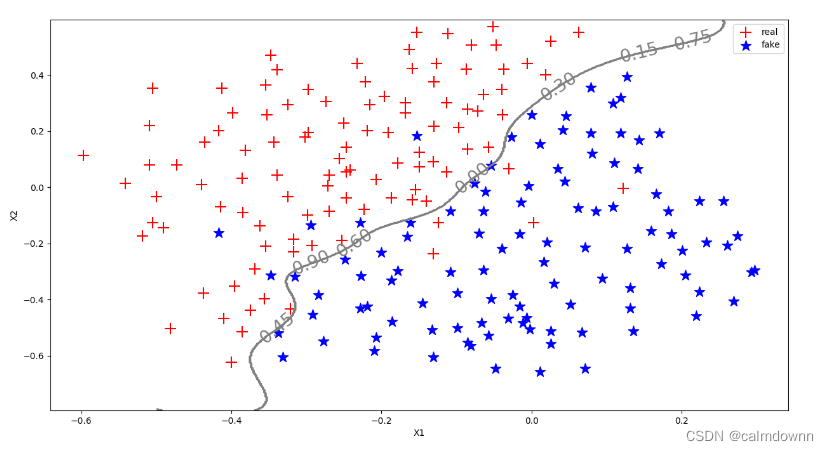
2)spainTrain.mat/spainTest.mat(第四部分)
前言:主要目的是分出哪些是垃圾邮件
1.导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm2.提取数据
# 提取数据 ex6data1.mat
spain_train = loadmat('spamTrain.mat')
spain_test = loadmat('spamTest.mat')
# 看一下数据的建值与维度
# print(spain_train.keys(),spain_test.keys()) # X,y,Xtest,ytest
X = spain_train['X']
y = spain_train['y']
X_test = spain_test['Xtest']
y_test = spain_test['ytest']看一下X的数据,与X的维度
可以看到X的数据都是0或者1,其实这代表的是字母是否存在,4000行代表的是邮件的数量不用过多解释,那1899列其实代表的就是1899个常用的单词,比如一篇邮件中有apple这个单词,那么某一列可能就会为1,这一列用来表示apple的状态,那么当这1899个单词中以某种组合出现在一篇邮件中,可能就会被默认为垃圾邮件,y为1

3.执行分类
这里SVC()函数中没有赋值C与gama参数,就是默认,由其自行分析并执行,kernel默认是高斯函数
svc1 = svm.SVC()
svc1.fit(X, y)
cru_score_train = svc1.score(X, y)
cru_score_test = svc1.score(X_test, y_test)
print(cru_score_train, cru_score_test)预测的分数如下:
对训练集的预测分数为:0.99325
对测试集的预测分数为:0.987

三.全部代码
1)第一部分代码(ex6data1.mat)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
# 提取数据 ex6data1.mat
data1 = loadmat('ex6data1.mat')
X = data1['X'] # 维度为(51 * 2)
y = data1['y'] # 维度为(51 * 1)
# 利用pd.dataframe函数将X和y整合到一起,方便画图等操作
data_X_y = pd.DataFrame(X, columns=['X1', 'X2'])
# 添加y一列
data_X_y['y'] = y
# print(data_X_y)
# print(X.shape, y.shape)
# 正值和负值的分布图
def plot_diagram(data_X_y):
plt.figure(figsize=(15, 8))
real = data_X_y['y'].isin([1]) # 找出y里面等于1的所有项
fake = data_X_y['y'].isin([0]) # 找出y里面等于0的所有项
# real,fake可以看成一个集合里面存放着true和false,之后在下面data_X_y套用之后会默认
# 匹配拥有true的所有行索引
# print(data_X_y[real])
plt.scatter(data_X_y[real]['X1'],data_X_y[real]['X2'],s = 150,marker='+',c='r',label = 'real')
plt.scatter(data_X_y[fake]['X1'],data_X_y[fake]['X2'],s = 150,marker='*',c='b',label = 'fake')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend()
pass
# plot_diagram(data_X_y)
# plt.show()
# 下面创建svc模型
svc1 = svm.SVC(C=100,kernel='linear')
# 进行模型拟合
svc1.fit(data_X_y[['X1','X2']],data_X_y['y'])
# 看一下模型预测的结果
# result = svc1.predict(data_X_y[['X1','X2']])
# print(result)
# # 看看预测的分数也就是预测的准确率
# predict_odd = svc1.score(data_X_y[['X1','X2']],data_X_y['y'])
# print(predict_odd)
# 绘制边界图
def plot_bandary(svc1,data_X_y):
X1_min = np.min(data_X_y['X1'])
X1_max = np.max(data_X_y['X1'])
X2_min = np.min(data_X_y['X2'])
X2_max = np.max(data_X_y['X2'])
xx = np.linspace(X1_min,X1_max,500)
yy = np.linspace(X2_min,X2_max,500)
xx1,yy1 = np.meshgrid(xx,yy) # 变成网格(500*500),方便后面画等高线图
# 这里np.c_的方法是把列进行和并,因为这俩都是一维数组,所以是先将俩个一维数组变成列向量在进行合并
z = svc1.predict(np.c_[xx1.flatten(), yy1.flatten()]) # 利用np.c_来进行合并,将xx,yy俩个(500,500)降成一维(250000,)并且合并成(250000*2)
z = z.reshape(xx1.shape) # 这里得到的预测数组维度是(250000,)将其也换成网格,配合等高线
C=plt.contour(xx1,yy1,z,levels = [-1,0,1],colors='gray')
plt.clabel(C, inline=True, fontsize=20)
pass
plot_diagram(data_X_y)
plot_bandary(svc1,data_X_y)
plt.show()
2)第二部分代码(ex6data2.mat)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
# 提取数据 ex6data2.mat
data2 = loadmat('ex6data2.mat')
# 看一下数据集二的建值
# print(data2.keys()) # X,y
X = data2['X']
y = data2['y']
# 还是将X1,X2,y整合到一起
data2_X_y = pd.DataFrame(X, columns=['X1', 'X2'])
data2_X_y['y'] = y
# print(data2_X_y)
# 正值和负值的分布图
def plot_diagram(data_X_y):
plt.figure(figsize=(15, 8))
real = data_X_y['y'].isin([1]) # 找出y里面等于1的所有项
fake = data_X_y['y'].isin([0]) # 找出y里面等于0的所有项
# real,fake可以看成一个集合里面存放着true和false,之后在下面data_X_y套用之后会默认
# 匹配拥有true的所有行索引
plt.scatter(data_X_y[real]['X1'], data_X_y[real]['X2'], s=150, marker='+', c='r', label='real')
plt.scatter(data_X_y[fake]['X1'], data_X_y[fake]['X2'], s=150, marker='*', c='b', label='fake')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend()
pass
# 下面创建svc模型
svc1 = svm.SVC(C=0.1,gamma=10)
# 进行模型拟合
svc1.fit(data2_X_y[['X1','X2']],data2_X_y['y'])
# 看一下模型预测的结果
result = svc1.predict(data2_X_y[['X1','X2']])
print(result)
# 看看预测的分数也就是预测的准确率
predict_odd = svc1.score(data2_X_y[['X1','X2']],data2_X_y['y'])
print(predict_odd)
# 绘制边界图
def plot_bandary(svc1, data_X_y):
X1_min = np.min(data_X_y['X1'])
X1_max = np.max(data_X_y['X1'])
X2_min = np.min(data_X_y['X2'])
X2_max = np.max(data_X_y['X2'])
xx = np.linspace(X1_min, X1_max, 500)
yy = np.linspace(X2_min, X2_max, 500)
xx1, yy1 = np.meshgrid(xx, yy) # 变成网格(500*500),方便后面画等高线图
# 这里np.c_的方法是把列进行和并,因为这俩都是一维数组,所以是先将俩个一维数组变成列向量在进行合并
z = svc1.predict(np.c_[xx1.flatten(), yy1.flatten()]) # 利用np.c_来进行合并,将xx,yy俩个(500,500)降成一维(250000,)并且合并成(250000*2)
z = z.reshape(xx1.shape) # 这里得到的预测数组维度是(250000,)将其也换成网格,配合等高线
C = plt.contour(xx1, yy1, z, colors='gray')
plt.clabel(C, inline=True, fontsize=20)
pass
plot_diagram(data2_X_y)
plot_bandary(svc1,data2_X_y)
plt.show()
3)第三部分代码(ex6data3.mat)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
# 提取数据 ex6data1.mat
data3 = loadmat('ex6data3.mat')
# 看一下数据集三的建值
# print(data2.keys()) # X,y,yval,Xval
X = data3['X']
y = data3['y']
X_val = data3['Xval']
y_val = data3['yval']
# 将X1,X2,y整合到一起
data3_X_y = pd.DataFrame(X, columns=['X1', 'X2'])
data3_X_y['y'] = y
# 将X1_val,X2_val,y_val整合到一起
data3_X_y_val = pd.DataFrame(X_val, columns=['X1_val', 'X2_val'])
data3_X_y_val['y_val'] = y_val
# print(data3_X_y_val)
# 正值和负值的分布图
def plot_diagram(data_X_y):
plt.figure(figsize=(15, 8))
real = data_X_y['y'].isin([1]) # 找出y里面等于1的所有项
fake = data_X_y['y'].isin([0]) # 找出y里面等于0的所有项
# real,fake可以看成一个集合里面存放着true和false,之后在下面data_X_y套用之后会默认
# 匹配拥有true的所有行索引
plt.scatter(data_X_y[real]['X1'], data_X_y[real]['X2'], s=150, marker='+', c='r', label='real')
plt.scatter(data_X_y[fake]['X1'], data_X_y[fake]['X2'], s=150, marker='*', c='b', label='fake')
plt.xlabel('X1')
plt.ylabel('X2')
plt.legend()
pass
# plot_diagram(data3_X_y)
# plt.show()
# 下面分别测试C和gama最合适的选值
def test_best_Cgama(data3_X_y, data3_X_y_val):
C_list = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
gama_list = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
best_score = 0
best_C = 0
best_gama = 0
for i in C_list:
for j in gama_list:
svc1 = svm.SVC(C=i, gamma=j)
svc1.fit(data3_X_y[['X1', 'X2']], data3_X_y['y'])
recent_score = svc1.score(data3_X_y_val[['X1_val', 'X2_val']], data3_X_y_val['y_val'])
if (recent_score > best_score):
best_score = recent_score
best_C = i
best_gama = j
pass
return best_C, best_gama, best_score
pass
# 绘制边界图
def plot_bandary(svc1, data_X_y):
X1_min = np.min(data_X_y['X1_val'])
X1_max = np.max(data_X_y['X1_val'])
X2_min = np.min(data_X_y['X2_val'])
X2_max = np.max(data_X_y['X2_val'])
xx = np.linspace(X1_min, X1_max, 500)
yy = np.linspace(X2_min, X2_max, 500)
xx1, yy1 = np.meshgrid(xx, yy) # 变成网格(500*500),方便后面画等高线图
# 这里np.c_的方法是把列进行和并,因为这俩都是一维数组,所以是先将俩个一维数组变成列向量在进行合并
z = svc1.predict(np.c_[xx1.flatten(), yy1.flatten()]) # 利用np.c_来进行合并,将xx,yy俩个(500,500)降成一维(250000,)并且合并成(250000*2)
z = z.reshape(xx1.shape) # 这里得到的预测数组维度是(250000,)将其也换成网格,配合等高线
C = plt.contour(xx1, yy1, z, colors='gray')
plt.clabel(C, inline=True, fontsize=20)
pass
best_C, best_gama, best_score = test_best_Cgama(data3_X_y, data3_X_y_val)
print(f"C:{best_C} best_gama:{best_gama} best_score:{best_score}")
svc1 = svm.SVC(C=best_C, gamma=best_gama)
svc1.fit(data3_X_y[['X1', 'X2']], data3_X_y['y'])
plot_diagram(data3_X_y)
plot_bandary(svc1, data3_X_y_val)
plt.show()
4)第四部分代码(spainTrain.mat/spainTest.mat)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
# 提取数据 ex6data1.mat
spain_train = loadmat('spamTrain.mat')
spain_test = loadmat('spamTest.mat')
# 看一下数据的建值与维度
# print(spain_train.keys(),spain_test.keys()) # X,y,Xtest,ytest
X = spain_train['X']
y = spain_train['y']
X_test = spain_test['Xtest']
y_test = spain_test['ytest']
# print(X.shape)
# print(X)
svc1 = svm.SVC()
svc1.fit(X, y)
cru_score_train = svc1.score(X, y)
cru_score_test = svc1.score(X_test, y_test)
print(cru_score_train, cru_score_test)