这是这门课程第二周的内容。
当深度学习遇到大数据(样本量在十万级以上)时,我们之前的常规操作在这时可能会变得很笨重。
1. Mini-batch gradient descent
之前在模型训练过程时,每一轮迭代都需要遍历整个训练集样本,当样本集非常大时,这样的每一轮都将经历漫长的时间。为了应对这一难题,有人提出了Mini-batch gradient descent,与之对应的是batch gradient descent。
batch gradient descent即我们之前常用到的梯度下降算法,它在每一轮计算梯度时考虑所有的训练样本集;
mini-batch gradient descent的特殊之处在于,每一轮计算梯度时,只考虑一部分(m)训练样本集;一种极端情况,每轮只考虑一个训练样本,这样的优化算法又称之为Stochastic Gradient Descent。
如:将整个训练集划分为64个样本为单个mini_batch。
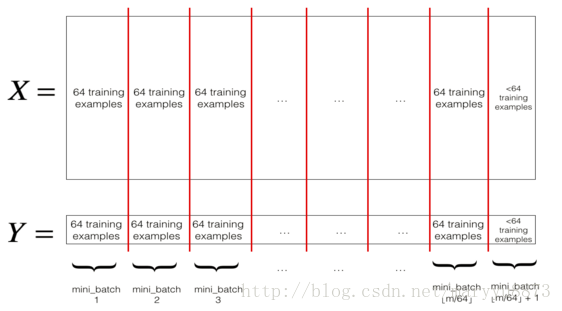
由于mini-batch每次更新梯度时只考虑一部分训练样本,因此更新所得参数并不能保证使训练集总体的损失函数值一直处于下降的趋势,所得到的结果一般是训练集的损失函数值在震荡中逐渐降低。
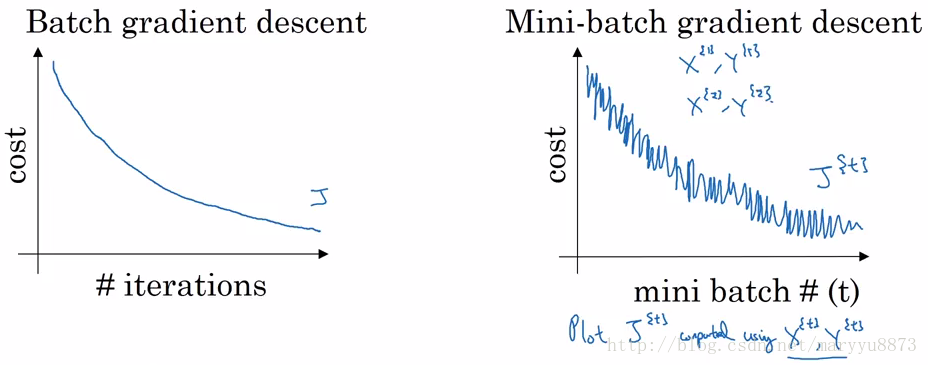
mini-batch的优点是训练速度快,对资源的要求低;缺点是往往很难收敛。

常用的mini-batch大小:64(2^6), 128(2^7),256(2^8), 1024(2^10)
2. Gradient descent with momentum
上一节提到,mini-batch gradient descent每次更新参数并不能保证训练集的损失值一直变小,表现出来的结果会比较震荡。可以这样理解:mini-batch在一些我们比较不关心的方向上过度学习,并且拖缓了我们希望它前进的方法的速度。
为了应对这一挑战,我们采用 exponentially weighted average的思路来计算梯度。即我们希望新的梯度由当前batch样本计算的梯度和以往的梯度组合而成,组合方式就是上面提到的指数权重平均法。
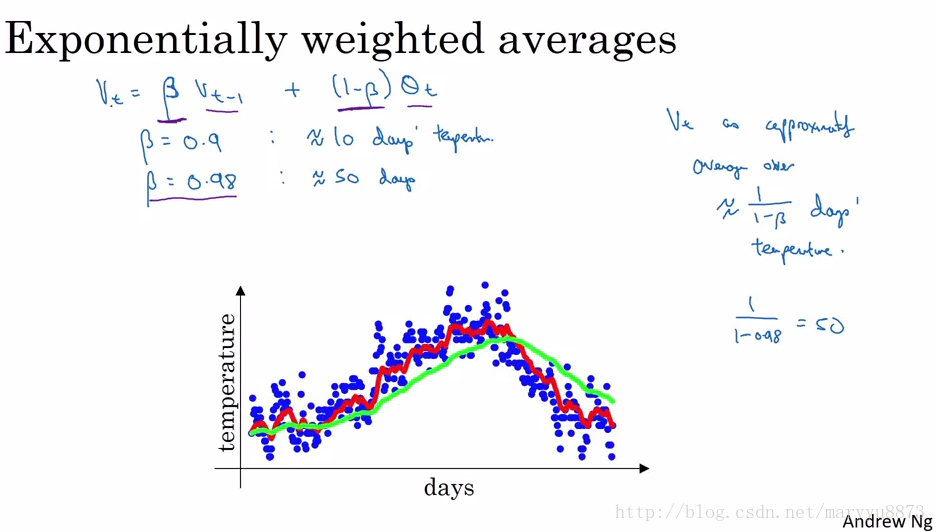
下图可以帮我们很好地理解exponentially weighted average。

其中

Exponentially weighted average
指数权重平均法可以有效地降低数据的波动性,并且代码实现简单,运行时不需要缓存过多数据,在深度学习算法中很受欢迎。
下图为采用指数权重平均法描述一年当中温度的变化情况,其中红线
Momentum
使用指数权重平均法更新梯度的梯度下降算法便可称之为 Gradient descent with momentum,那么它的梯度更新公式如下:
如下:Momentum的梯度用红色箭头表示,蓝线代表当前batch计算的梯度,它只是影响红色箭头的走向,红色箭头并不完全按它的方向前进。
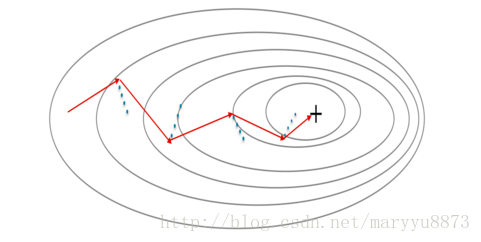
Momentum在更新梯度时考虑了以前的梯度值,这样它的梯度更新变得更平滑,Momentum可以应用在batch gradient descent, mini-batch gradient descent 或 stochastic gradient descent。
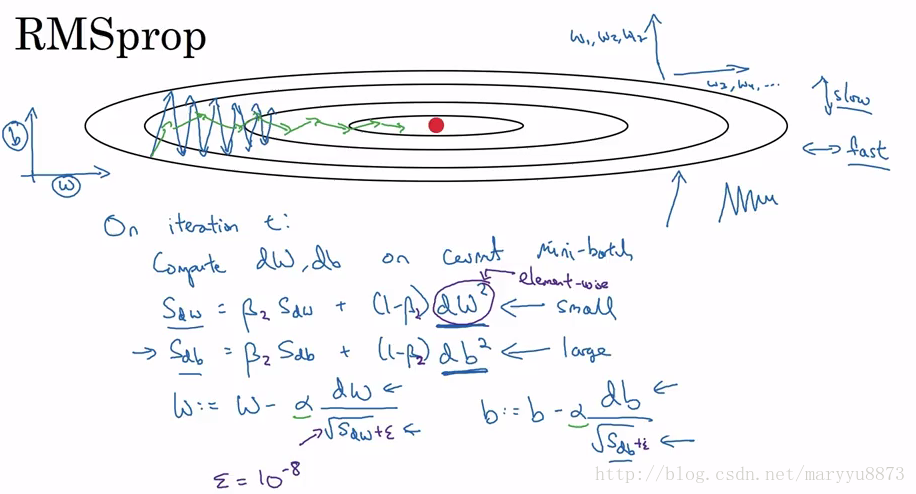
3. Gradient descent with RMSprop
RMSprop是另一种可以加速梯度下降的方法。可以认为RMSprop和Momentum两种方法的目的都是一样的——加速梯度下降,只是具体实现策略不同。
4. Adam
Adam是用于训练神经网络的最有效方法之一,它结合了Momentum和RMSprop两者的思想。我们来看一下Adam在更新梯度时的策略:

Adam是怎样工作的?在每一轮进行梯度更新时:
首先它会计算出前面梯度值的指数权重平均值,并保存为变量
然后它会计算出前面梯度值的指数权重平均值的平方值,并保存为变量
最后基于前两步的结果更新梯度。(Combination)
其中更新
更新参数
Adam的优点:
- 相对较小的内存需求(当然比gradient descent和gradient descent with momentum还是要高一些);
- 收敛非常迅速。
5. Learning-rate-decay
有时候我们在训练模型时会遇到模型无法在全局最优点收敛的问题。如下蓝线所示:
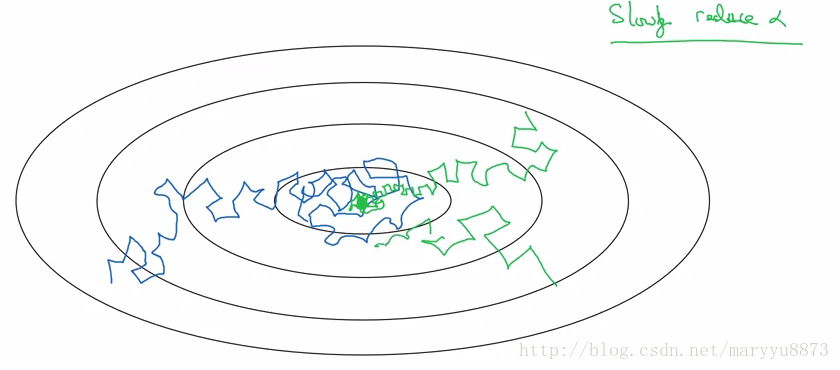
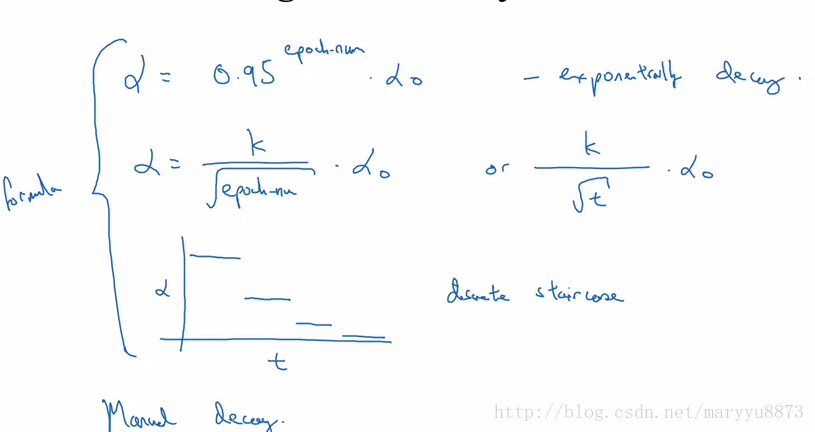
然而如果设置
通常用于缩小
注:如无特殊说明,以上所有图片均截选自吴恩达在Coursera开设的神经网络系列课程的讲义。