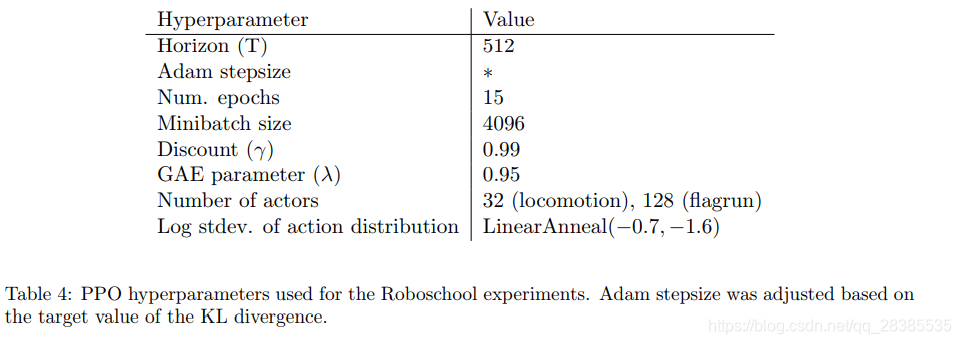
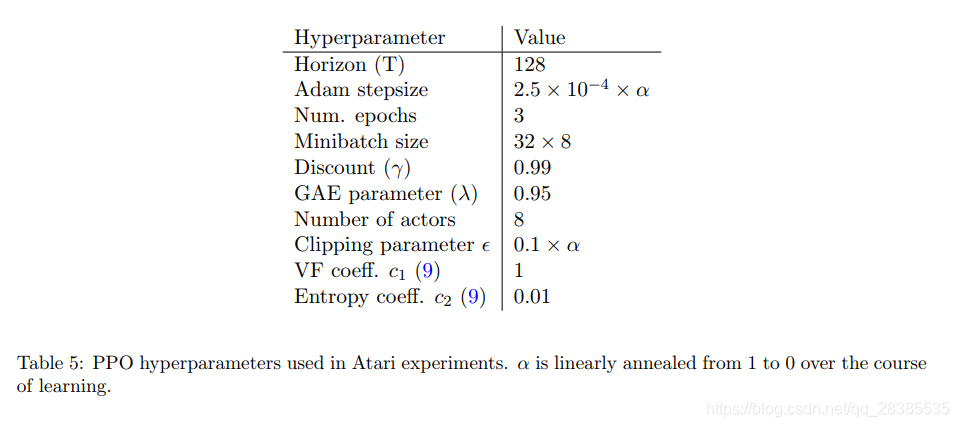
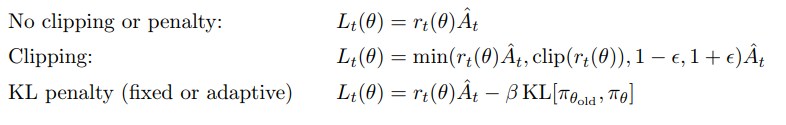我们提出了一类新的用于强化学习的策略梯度方法,该方法可以在与环境交互进行数据采样和使用随机梯度上升优化一个“替代”目标函数之间进行交替。标准策略梯度方法对每个数据样本执行一个梯度更新,而我们提出了一种新的目标函数,该函数可实现多次的小批量更新。我们称为近端策略优化 (PPO)的新方法具有信赖域策略优化(TRPO)的一些优点,但它们实施起来更简单,更通用,并且具有更好的样本复杂性(经验上)。我们的实验在一系列基准任务上测试了PPO,包括模拟机器人运动和Atari游戏,我们证明了PPO的性能优于其他在线策略梯度 方法,并且总体上在样本复杂性,简单性和有效期之间取得了良好的平衡。
近年来,已经提出了几种使用神经网络函数近似器进行强化学习的方法。主要有深度Q学习(DQN),“vanilla”策略梯度方法和信赖域/自然策略梯度方法。然而,在开发一种可扩展(适用于大型模型和并行实现),数据高效且健壮(即在无需超调整参数的情况下成功解决各种问题)的方法方面仍有改进的余地 。Q-learning(带有函数近似器)在许多简单的问题上失败了,人们对其原因知之甚少,“vanilla”策略梯度的数据效率和健壮性也很差。信赖域策略优化(TRPO)相对复杂,并且对于具有噪声(例如,dropout)或参数共享(在策略和价值函数之间或与辅助任务之间)的网络结构不兼容 。仅使用一阶优化即可获得数据效率和TRPO可靠性能的算法 ,来改善当前的事务状态。我们提出了一种具有裁剪概率率 (clipped probability ratios)的新目标函数,该目标函数形成了对策略性能的悲观估计(即下界)。为了优化策略,我们在从策略采样数据和对采样数据执行几个优化时期之间交替进行。
策略梯度方法通过计算策略梯度的估计值并将其插入随机梯度上升算法中来工作。最常用的梯度估计器 具有以下形式:
g
^
=
E
^
[
∇
θ
l
o
g
π
θ
(
a
t
∣
s
t
)
A
^
t
]
(1)
\hat g=\hat \mathbb E[\nabla_\theta log~\pi_{\theta}(a_t|s_t)\hat A_t]\tag{1}
g ^ = E ^ [ ∇ θ l o g π θ ( a t ∣ s t ) A ^ t ] ( 1 )
π
θ
π_θ
π θ
A
^
t
\hat A_t
A ^ t
t
t
t
E
^
[
…
]
\hat \mathbb E[\dots]
E ^ [ … ]
g
^
\hat g
g ^
L
P
G
(
θ
)
=
E
^
t
[
l
o
g
π
θ
(
a
t
∣
s
t
)
A
^
t
]
.
(2)
L^{PG}(\theta)=\hat \mathbb E_t[log~\pi_{\theta}(a_t|s_t)\hat A_t].\tag{2}
L P G ( θ ) = E ^ t [ l o g π θ ( a t ∣ s t ) A ^ t ] . ( 2 )
L
P
G
L^{PG}
L P G
在TRPO中,目标函数(“替代”目标函数)在策略更新的步长上受到限制 。即:
m
a
x
i
m
i
z
e
θ
E
^
t
[
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
A
^
t
]
(3)
\mathop{maximize}\limits_{\theta}\quad \hat \mathbb E_t[\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\hat A_t]\tag{3}
θ ma x imi ze E ^ t [ π θ o l d ( a t ∣ s t ) π θ ( a t ∣ s t ) A ^ t ] ( 3 )
s
u
b
j
e
c
t
t
o
E
^
t
[
K
L
[
π
θ
o
l
d
(
⋅
∣
s
t
)
,
π
θ
(
⋅
∣
s
t
)
]
]
≤
δ
.
(4)
subject~to\quad\hat \mathbb E_t[KL[\pi_{\theta_{old}}(\cdot|s_t),\pi_{\theta}(\cdot|s_t)]]\le\delta.\tag{4}
s u b j e c t t o E ^ t [ K L [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] ≤ δ . ( 4 )
θ
o
l
d
θ_{old}
θ o l d 共轭梯度算法 有效地解决该问题。
m
a
x
i
m
i
z
e
θ
E
^
t
[
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
A
^
t
−
β
K
L
[
π
θ
o
l
d
(
⋅
∣
s
t
)
,
π
θ
(
⋅
∣
s
t
)
]
]
(5)
\mathop{maximize}\limits_{\theta}~\hat \mathbb E_t[\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\hat A_t-\beta KL[\pi_{\theta_{old}}(\cdot|s_t),\pi_{\theta}(\cdot|s_t)]]\tag{5}
θ ma x imi ze E ^ t [ π θ o l d ( a t ∣ s t ) π θ ( a t ∣ s t ) A ^ t − β K L [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] ( 5 )
β
β
β
π
π
π
β
β
β 因此,为了实现我们的模拟TRPO单调改进的一阶算法的目标,实验表明,仅仅选择固定惩罚系数
β
β
β 。需要其他修改。
r
t
(
θ
)
r_t(\theta)
r t ( θ ) 概率率
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
)
(
a
t
∣
s
t
)
r_t(\theta)=\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old}}(a_)(a_t|s_t)}
r t ( θ ) = π θ o l d ( a ) ( a t ∣ s t ) π θ ( a t ∣ s t )
r
(
θ
o
l
d
)
=
1
r(\theta_{old})=1
r ( θ o l d ) = 1
L
C
P
I
(
θ
)
=
E
^
t
[
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
)
(
a
t
∣
s
t
)
A
^
t
]
=
E
^
t
[
r
t
(
θ
)
A
^
t
]
.
(6)
L^{CPI}(\theta)=\hat \mathbb E_t[\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old}}(a_)(a_t|s_t)}\hat A_t]=\hat \mathbb E_t[r_t(\theta)\hat A_t].\tag{6}
L C P I ( θ ) = E ^ t [ π θ o l d ( a ) ( a t ∣ s t ) π θ ( a t ∣ s t ) A ^ t ] = E ^ t [ r t ( θ ) A ^ t ] . ( 6 )
C
P
I
CPI
C P I 约束策略迭代 ,其论文中提出了该目标函数。在没有约束项的情况下,
L
C
P
I
L^{CPI}
L C P I 因此,我们现在考虑如何修改该目标函数,以惩罚
r
t
(
θ
)
r_t(θ)
r t ( θ )
1
1
1 。
L
C
L
I
P
(
θ
)
=
E
^
t
[
m
i
n
(
r
t
(
θ
)
A
^
t
,
c
l
i
p
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
^
t
)
]
(7)
L^{CLIP}(\theta)=\hat \mathbb E_t[min(r_t(\theta)\hat A_t,clip(r_t(\theta),1-\epsilon,1+\epsilon)\hat A_t)]\tag{7}
L C L I P ( θ ) = E ^ t [ m i n ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] ( 7 )
ϵ
\epsilon
ϵ
ϵ
=
0.2
\epsilon=0.2
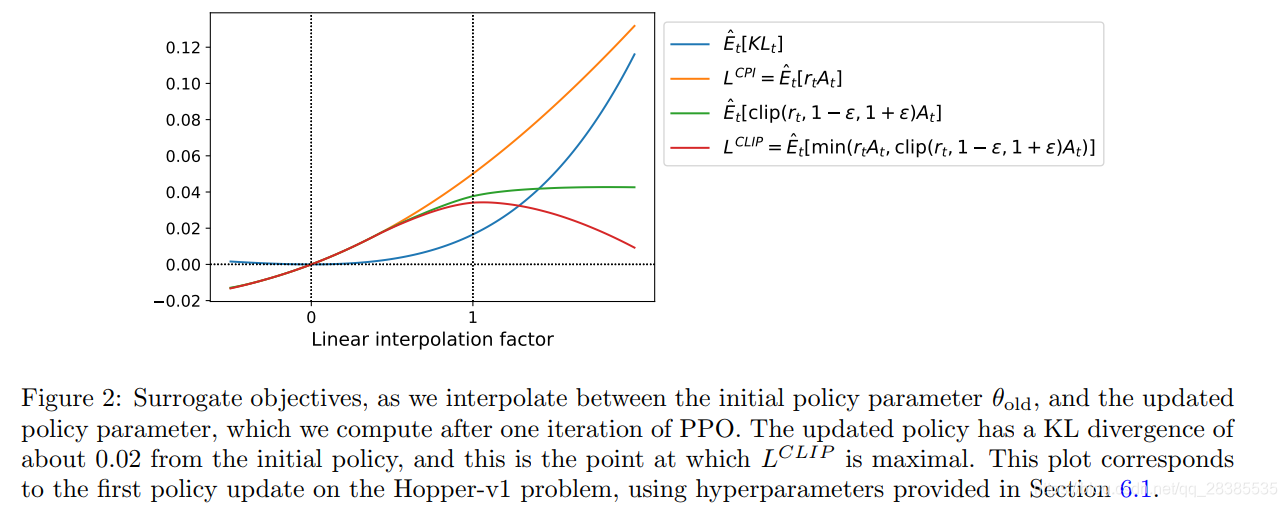
ϵ = 0 . 2 目标函数提出的动机如下 :位于
m
i
n
(
)
min()
m i n ( )
L
C
P
I
L^{CPI}
L C P I
m
i
n
(
)
min()
m i n ( )
c
l
i
p
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
^
t
)
clip(r_t(\theta),1-\epsilon,1+\epsilon)\hat A_t)
c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t )
r
t
r_t
r t
[
1
−
ϵ
,
1
+
ϵ
]
[1-\epsilon,1+\epsilon]
[ 1 − ϵ , 1 + ϵ ] 通过这种方案,我们仅在概率率提高目标函数时才忽略概率率的变化,而在概率率使目标函数减少时将其包括在内 。注意,在
θ
o
l
d
θ_{old}
θ o l d
r
=
1
r=1
r = 1
L
C
L
I
P
(
θ
)
=
L
C
P
I
(
θ
)
L^{CLIP}(θ)= L^{CPI}(θ)
L C L I P ( θ ) = L C P I ( θ )
θ
θ
θ
θ
o
l
d
θ_{old}
θ o l d
L
C
L
I
P
L^{CLIP}
L C L I P
t
t
t
r
r
r
1
+
ϵ
1+\epsilon
1 + ϵ
1
−
ϵ
1-\epsilon
1 − ϵ
L
C
L
I
P
L^{CLIP}
L C L I P
L
C
L
I
P
L^{CLIP}
L C L I P
L
C
P
I
L^{CPI}
L C P I
另外一种能够替代或补充裁剪替代目标函数的方法是使用一个KL散度作为惩罚项,并自适应调整惩罚系数
β
β
β
d
t
a
r
g
d_{targ}
d t a r g 。在我们的实验中,我们发现KL惩罚项的表现要比裁剪替代目标函数差,但是,由于它是重要的baseline,因此我们在此处进行介绍。
使用具有mini-batch的SGD进行若干次迭代,以优化KL惩罚目标函数:
L
K
L
P
E
N
(
θ
)
=
E
^
t
[
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
A
^
t
−
β
K
L
[
π
θ
(
⋅
∣
s
t
)
,
π
θ
(
⋅
∣
s
t
)
]
]
(8)
L^{KLPEN}(\theta)=\hat \mathbb E_t[\frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\hat A_t-\beta KL[\pi_{\theta}(\cdot|s_t),\pi_{\theta}(\cdot|s_t)]]\tag{8}
L K L P E N ( θ ) = E ^ t [ π θ o l d ( a t ∣ s t ) π θ ( a t ∣ s t ) A ^ t − β K L [ π θ ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] ( 8 )
计算
d
=
E
^
t
[
K
L
[
π
θ
(
⋅
∣
s
t
)
,
π
θ
(
⋅
∣
s
t
)
]
]
d=\hat \mathbb E_t[KL[\pi_{\theta}(\cdot|s_t),\pi_{\theta}(\cdot|s_t)]]
d = E ^ t [ K L [ π θ ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ]
d
<
d
t
a
r
g
/
1.5
d<d_{targ}/1.5
d < d t a r g / 1 . 5
β
←
β
/
2
\beta \leftarrow\beta/2
β ← β / 2
d
>
d
t
a
r
g
×
1.5
d>d_{targ}\times1.5
d > d t a r g × 1 . 5
β
←
β
×
2
\beta \leftarrow\beta\times2
β ← β × 2
更新后的
β
β
β
d
t
a
r
g
d_{targ}
d t a r g
β
β
β
β
β
β
L
C
L
I
P
L^{CLIP}
L C L I P
L
K
L
P
E
N
L^{KLPEN}
L K L P E N
L
P
G
L^{PG}
L P G
V
(
s
)
V(s)
V ( s ) 如果使用在策略和价值函数之间共享参数的神经网络体系结构,则必须使用将策略损失和价值损失项组合在一起的损失函数。如过去的工作所建议的,可以通过增加熵值奖赏以确保足够的探索来进一步增强此目标函数 。结合这些损失项,我们获得以下目标函数,并在每次迭代时最大化该目标函数:
L
t
C
L
I
P
+
V
F
+
S
(
θ
)
=
E
^
t
[
L
t
C
L
I
P
(
θ
)
−
c
1
L
t
V
F
(
θ
)
+
c
2
S
[
π
θ
]
(
s
t
)
]
,
(9)
L^{CLIP+VF+S}_{t}(\theta)=\hat \mathbb E_t[L^{CLIP}_t(\theta)-c_1L^{VF}_t(\theta)+c_2S[\pi_{\theta}](s_t)],\tag{9}
L t C L I P + V F + S ( θ ) = E ^ t [ L t C L I P ( θ ) − c 1 L t V F ( θ ) + c 2 S [ π θ ] ( s t ) ] , ( 9 )
c
1
,
c
2
c_1,c_2
c 1 , c 2
S
S
S
L
t
V
F
L^{VF}_t
L t V F
(
V
θ
(
s
t
)
−
V
t
t
a
r
g
)
2
(V_{\theta}(s_t)-V^{targ}_t)^2
( V θ ( s t ) − V t t a r g ) 2
T
T
T
T
T
T
T
T
T
A
^
t
=
−
V
(
s
t
)
+
r
t
+
γ
r
t
+
1
+
⋯
+
γ
T
−
t
+
1
r
T
−
1
+
γ
T
−
t
V
(
s
T
)
(10)
\hat A_t=-V(s_t)+r_t+\gamma r_{t+1}+\cdots+\gamma^{T-t+1}r_{T-1}+\gamma^{T-t}V(s_T)\tag{10}
A ^ t = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) ( 1 0 )
t
t
t
T
T
T
[
0
,
T
]
[0,T]
[ 0 , T ]
λ
=
1
λ=1
λ = 1
A
^
t
=
δ
t
+
(
γ
λ
)
δ
t
+
1
+
⋯
+
(
γ
λ
)
T
−
t
+
1
δ
T
−
1
,
(11)
\hat A_t=\delta_t+(\gamma \lambda)\delta_{t+1}+\cdots+(\gamma \lambda)^{T-t+1}\delta_{T-1},\tag{11}
A ^ t = δ t + ( γ λ ) δ t + 1 + ⋯ + ( γ λ ) T − t + 1 δ T − 1 , ( 1 1 )
w
h
e
r
e
δ
t
=
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
(12)
where\quad \delta_t=r_t+\gamma V(s_{t+1})-V(s_t)\tag{12}
w h e r e δ t = r t + γ V ( s t + 1 ) − V ( s t ) ( 1 2 ) 算法1显示了使用固定长度轨迹段的近端策略优化(PPO)算法 。每次迭代中,N个(并行)actors中的每一个都收集T个时间步长的数据。然后,我们在这些
N
T
NT
N T
K
K
K