(一)Title
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ndwWn8ra-1687154576169)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230616145909128.png)]](https://img-blog.csdnimg.cn/2bb836a80f0c46ba9b1fed6ce8408e34.png)
写在前面: 本文介绍PPO优化方法及其一些公式的推导。原文中作者给出了三种优化方法,其中第三种是第一种的拓展,这两种使用广泛,且效果好,第二种方法在实验中验证效果不好,但也算一个trick,作者也在文中进行了分析。
(二)Abstract
深度强化学习在训练过程中难以避免效果容易发生退化并且很难恢复这类问题,导致训练不稳定。自然策略梯度[1](NPG,Natural Policy Gradient)算法解决了策略梯度算法的收敛性问题,但该算法需要计算二阶导矩阵,在实际使用过程中性能受限,扩展性差。现有许多研究工作都是围绕如何通过近似二阶优化算法来降低算法复杂度。本文将基于近端策略优化[2](PPO,Proximal Policy Optimization)算法展开讨论,分析一种不同思想的优化策略。PPO没有引入一个强约束,而是将约束项作为目标函数中的一个惩罚项,并使用一阶优化算法来进行模型优化,大大降低了算法复杂度。同时通过实验结果表明,它比信赖域策略优化(TRPO,Trust Region Policy Optimization)更通用,更容易实现,且具有更好的采样复杂度。
(三)Introduction
近年来,众多研究者提出了几种不同的方法将利用神经网络函数逼近器进行强化学习,比如Deep Q-Learning[3]、”Vanilla”policy gradient[4]、 trust region/natural poliicy gradient[5]等方法。但是这些方法都有其不足的地方,比如:Deep Q-Learning在许多简单的任务上都失败了,并且理解能力较差;”Vanilla”policy gradient方法在处理数据的效率和鲁棒性方面表现很差;TRPO相对其他方法虽然性能较优,但是算法复杂度高,并且不能与其他框架兼容。本文研究的PPO[2]算法,仅使用一阶优化的情况下,实现了TRPO的数据效率和可靠性能,来改善当前算法的情况。
PPO算法中提出了一种新的目标函数,该目标函数具有截断的概率比,而截断的概率比一般会造成对性能比较悲观的估计,即估计出性能的下界。为了优化这个策略,PPO在策略中采样的数据中进行选择,然后在采样的数据中进行几个轮次的优化。另外,PPO采用重要性采样方法,即数据采样不依赖于当前策略。因此允许使用单个样本进行多轮的训练,可以增加数据利用的效率。
作者提出了三种优化方法来实现PPO算法。同时最后的实验表明PPO算法与其他几种算法相比,PPO表现的更好且复杂度更低,特别是在连续任务上。
(四)Background: Policy Optimization
1、策略梯度算法(Policy Gradient Methods)
策略梯度方法通过计算策略梯度的估计量并将其插入随机梯度上升算法来工作。通常使用如下的目标函数进行梯度提升,一般实现时取负以使用梯度下降优化算法:
g ^ = E t ^ [ ∇ θ l o g π θ ( a t ∣ s t ) A ^ t ] (1) \hat{g}=\hat{\mathbb{E}_t}[\nabla_{\theta}log\pi_{\theta}(a_t\mid{s_t})\hat{A}_t]\tag{1} g^=Et^[∇θlogπθ(at∣st)A^t](1)
其中, π θ \pi_{\theta} πθ是随机策略, A ^ t \hat{A}_t A^t是时刻t的优势函数的估计, E ^ t \hat{E}_{t} E^t是期望,表示采样值有限batch的平均经验值。实际实现时,可以使用自动微分的软件来构建一个目标函数,其梯度是策略梯度估计;而该梯度估计可以通过微分下面的目标来得到:
L P G ( θ ) = E t ^ [ l o g π θ ( a t ∣ s t ) A ^ t ] (2) L^{PG}(\theta)=\hat{\mathbb{E}_t}[log\pi_{\theta}(a_t\mid{s_t})\hat{A}_t]\tag{2} LPG(θ)=Et^[logπθ(at∣st)A^t](2)
虽然人们推荐使用相同的轨迹对 L P G ( θ ) {L^{P G}(\theta)} LPG(θ)进行多步优化,但该优化方法的缺点很明显,在每次更新参数后,都需要重新与环境互动,计算新的策略的优势函数,再进行参数更新。即一条轨迹只能更新参数一次,导致大部分时间都浪费在与环境互动上。
2、信赖域算法(Trust Region Methods)
在TRPO[5],在策略更新大小时服从约束条件来最大化目标函数。
m a x i m i z e θ E t ^ [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A ^ t ] (3) \underset {\theta}{maximize} {\quad} \hat{\mathbb{E}_t}[\frac{\pi_{\theta}(a_t\mid{s_t})}{\pi_{\theta_{old}}(a_t\mid{s_t})}\hat{A}_t]\tag{3} θmaximizeEt^[πθold(at∣st)πθ(at∣st)A^t](3)
s . t . m a x i m i z e θ E t ^ [ K L [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] ≤ δ (4) s.t.\underset {\theta}{maximize} {\quad}\hat{\mathbb{E}_t}[KL[\pi_{\theta_{old}}(·|s_t),\pi_{\theta}(·|s_t)]]\leq\delta\tag{4} s.t.θmaximizeEt^[KL[πθold(⋅∣st),πθ(⋅∣st)]]≤δ(4)
其中, θ o l d \theta_{old} θold 是更新以前的策略参数的向量。可以看出跟式2的主要区别在于:添加了一个约束项,要求前后两个策略之间的 KL散度小于某一阈值。在对目标函数进行线性逼近和对约束进行二次估计后,利用共轭梯度算法可以有效的近似求解该问题。
由于TRPO算法中需要近似计算二阶导数,算法复杂度高。一种直观的解决方法就是直接将约束项作为目标函数的惩罚项,就可以直接进行一阶算法优化。作者在式5证明了TRPO实际上ke使用的是一个惩罚项而不是约束项,即求解非受限优化问题。
m a x i m i z e θ E t ^ [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A ^ t − β K L [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] (5) \underset {\theta}{maximize} {\quad} \hat{\mathbb{E}_t}[\frac{\pi_{\theta}(a_t\mid{s_t})}{\pi_{\theta_{old}}(a_t\mid{s_t})}\hat{A}_t-\beta KL[\pi_{\theta_{old}}(·|s_t),\pi_{\theta}(·|s_t)]]\tag{5} θmaximizeEt^[πθold(at∣st)πθ(at∣st)A^t−βKL[πθold(⋅∣st),πθ(⋅∣st)]](5)
TRPO算法可以使一条轨迹多次更新参数,从而节省时间。但是TRPO将新旧策略差异不能太大作为约束项,在实际操作中比较困难,即使将约束性作为惩罚项放入目标函数中,也需要自适应调整超参数 β \beta β以获得最佳性能,在不同的问题上选择合适的值 β \beta β是非常困难的,甚至在单个问题上,不同的特征也会随着学习而变化。所以,仅仅简单的设置一个固定参数来使用SGD优化TRPO的目标函数是不够的,需要进行额外的修改。
(五)Clipped Surrogate Objective
使用 r t ( θ ) r_t (\theta) rt(θ) 表示概率比: r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_t (\theta)=\frac{\pi_{\theta}(a_t\mid{s_t})}{\pi_{\theta_{old}}(a_t\mid{s_t})} rt(θ)=πθold(at∣st)πθ(at∣st),并且 r ( θ o l d ) = 1 r (\theta_{old})=1 r(θold)=1 。
TRPO的目标函数可进一步改写为:
L C P I ( θ ) = E t ^ [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A ^ t ] = E t ^ [ r t ( θ ) A ^ t ] (6) L^{CPI}(\theta)=\hat{\mathbb{E}_t}[\frac{\pi_{\theta}(a_t\mid{s_t})}{\pi_{\theta_{old}}(a_t\mid{s_t})}\hat{A}_t]=\hat{\mathbb{E}_t}[r_t (\theta)\hat{A}_t]\tag{6} LCPI(θ)=Et^[πθold(at∣st)πθ(at∣st)A^t]=Et^[rt(θ)A^t](6)
其中,上标CPI表示 Conservative Policy Iteration (CPI)[6]。在没有了约束项之后,最大化CPI目标函数将会得到一个过大的策略更新。因此,作者在这里考虑当 r t ( θ ) r_t (\theta) rt(θ)远离1时该如何修改目标函数使其能够惩罚策略的更新。这是因为 r t ( θ ) r_t (\theta) rt(θ)远离1时说明,更新前后的策略差异较大,而作者并不想大幅度的更新策略。
为了确保新旧策略差异不能太大,作者采用了一个截断函数来限制新旧策略之间的变化。该方法所提出的目标函数如下:
L C L I P ( θ ) = E t ^ [ m i n ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] (7) L^{CLIP}(\theta)=\hat{\mathbb{E}_t}[min(r_t (\theta)\hat{A}_t,clip(r_t (\theta),1-\epsilon,1+\epsilon)\hat{A}_t)]\tag{7} LCLIP(θ)=Et^[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)](7)
其中, ϵ \epsilon ϵ 是一个超参数,设置为 0.2。该目标函数的第一项就是 L C P I L^{CPI} LCPI,而第二项是对TPRO的目标函数进行截断,截断了概率比例,这保证 r t r_t rt 始终位于设定的范围 [1- ϵ \epsilon ϵ, 1+ ϵ \epsilon ϵ]之间。最后,作者取截断和未截断的目标函数最小值,因此最终的目标函数是未截断目标函数的下界。有了这种机制,只有当对概率比的改变可能会改善其目标函数时,才会忽略该改变,不对其进行调整。当调整后会使其恶化时,就会将概率比包含进来,进行修正。作者绘制了一个示意图来说明该问题,如图1所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qI2b7Aqw-1687154576170)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230619104922513.png)]](https://img-blog.csdnimg.cn/b0c1f5de8f7346a3a7e3c077f552f7cf.png)
从图1中可以分析得出:
-
当 A > 0 A>0 A>0时,最大化目标函数 L C P I L^{CPI} LCPI相当于最大化 r r r,当 r r r过于大时,即 r > 1 + ϵ r>1+\epsilon r>1+ϵ, L L L为常数,不再继续上升,此时 L L L对 θ \theta θ的导数为0,策略不再更新,迫使新旧策略差异不那么大。
-
当 A < 0 A<0 A<0时,最大化目标函数 L C P I L^{CPI} LCPI相当于最小化 r r r,当 r r r过于小时,即 r > 1 − ϵ r>1-\epsilon r>1−ϵ, L L L为常数,不再由 r r r改变而改变,此时 L L L对 θ \theta θ的导数为0,策略不再更新,迫使新旧策略差异小。
-
r = 1 r=1 r=1为优化起点,表示新旧策略一致无差别。
-
根据经验值 ϵ \epsilon ϵ取为0.2。
图2中显示了沿着策略更新方向进行插值时,几个目标函数是如何变化的,这是通过对连续控制问题的近端策略优化获得的。可以直观的观察到, L C L I P L^{CLIP} LCLIP 是 L C P I L^{CPI} LCPI 的一个下界,惩罚过大的策略更新。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PslrUm9c-1687154576170)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230619110637835.png)]](https://img-blog.csdnimg.cn/d62e6790b6004484b668f0902c3b4f68.png)
(六)Adaptive KL Penalty Coefficient
另一种来优化TRPO的方法,就是对KL散度施加惩罚,并自适应调整惩罚系数 β \beta β,以便每次策略更新时都能达到KL散度的目标值 d t a r g d_{targ} dtarg。但是在后续实验中发现,该方法的效果不如第一种方法,即截断目标函数,但在这里也对其展开分析,用作一个基准算法进行对比。
首先利用几个批次的Minibatch SGD,对KL惩罚目标函数进行优化:
L K L P E N ( θ ) = E t ^ [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A ^ t − β K L [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] (8) L^{KLPEN}(\theta)=\hat{\mathbb{E}_t}[\frac{\pi_{\theta}(a_t\mid{s_t})}{\pi_{\theta_{old}}(a_t\mid{s_t})}\hat{A}_t-\beta KL[\pi_{\theta_{old}}(·|s_t),\pi_{\theta}(·|s_t)]]\tag{8} LKLPEN(θ)=Et^[πθold(at∣st)πθ(at∣st)A^t−βKL[πθold(⋅∣st),πθ(⋅∣st)]](8)
其次,计算 d = E t ^ [ K L [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] d=\hat{\mathbb{E}_t}[KL[\pi_{\theta_{old}}(·|s_t),\pi_{\theta}(·|s_t)]] d=Et^[KL[πθold(⋅∣st),πθ(⋅∣st)]]用来调整自适应惩罚系数 β \beta β的大小:
-
当 d < d t a r g / 1.5 , β ← β / 2 d <d_{targ}/1.5,\beta \leftarrow \beta/2 d<dtarg/1.5,β←β/2
-
当 d > d t a r g × 1.5 , β ← β × 2 d > d_{targ}\times1.5,\beta \leftarrow \beta \times2 d>dtarg×1.5,β←β×2
更新后的 β \beta β用于下次策略的更新。使用这个方法,可能会发现在某次更新过程中,KL散度和 d t a r g d_{targ} dtarg差别很大,但几乎很少出现这种情况,并且 β \beta β会对此迅速调整。上述参数1.5和2是通过实验得到的, β \beta β初始值也是一个超参数,但这些在实际应用中并不重要,因为该算法很快会对其进行调整。
该方法的总体思想还是使得新旧策略之间的差异不能太大,但也不能完全没有变化。直观的理解就是:
-
当差异小时,让惩罚系数也变小,减少这部分的惩罚,这样目标函数 L K L P E N ( θ ) L^{KLPEN}(\theta) LKLPEN(θ)的变化幅度适当大些, L K L P E N ( θ ) L^{KLPEN}(\theta) LKLPEN(θ)对参数 θ \theta θ的梯度会适当变大,使得新旧策略存在一定差异,而非完全一致;
-
当差异大时,让惩罚系数也变大,增大这部分惩罚,这样目标函数 L K L P E N ( θ ) L^{KLPEN}(\theta) LKLPEN(θ)的变化会放缓, L K L P E N ( θ ) L^{KLPEN}(\theta) LKLPEN(θ)对参数 θ \theta θ的梯度会变小,迫使新旧策略差异小。
(七)Algorithm
熵(Entropy),代表分布的混乱程度。在强化学习中,熵代表一个动作的不可预测性。熵越大,分布越混乱,动作的随机性越强,模型的探索能力会越强;熵越小,分布越均匀,策略变为确定性,模型不去探索新方案,从而失去更多选择最优方案的机会。一般强化学习的方法是通过优化期望折扣奖励来学习一系列的动作,但这种学习过程容易使策略熵减,模型过早收敛于局部最优,一种解决方案是在每次迭代时引入一项Entropy Bonus正则项,以此来鼓励策略熵增,从而确保模型有足够的探索,逃离局部最优。
上述方法均是基于策略梯度(Policy Gradient)的算法。但此类方法解空间很大,很难对其充分采样,导致方差大。为了减少优势函数的方差,一般会引入状态函数 V ( s ) V(s) V(s)。如果使用神经网络结构,在策略和价值函数之间共享参数,必须使用一个结合策略目标和价值函数误差项的损失函数。在此基础上,目标函数可以通过添加Entropy Bonus来进一步确保足够的探索。因此,可以最大化如下目标函数可实现最优化:
L t C L I P + V F + W ( θ ) = E t ^ [ L t C L I P ( θ ) − c 1 L t V F ( θ ) + c 2 S [ π θ ] ( s t ) ] (9) L_t^{CLIP+VF+W}(\theta)=\hat{\mathbb{E}_t}[L_t^{CLIP}(\theta)-c_1L_t^{VF}(\theta)+c_2S[\pi_\theta](s_t)]\tag{9} LtCLIP+VF+W(θ)=Et^[LtCLIP(θ)−c1LtVF(θ)+c2S[πθ](st)](9)
其中, L t C L I P L^{CLIP}_{t} LtCLIP是第三节中提到的目标函数, L θ V F = ( V θ ( s t ) − V t t a r g ) 2 L^{VF}_{\theta}=(V_{\theta}(s_t)-V^{targ}_t)^2 LθVF=(Vθ(st)−Vttarg)2代表价值函数损失项, S [ π θ ] ( s t ) = − ∑ i π θ ( a i ∣ s t ) l o g π θ ( a i ∣ s t ) S[\pi_{\theta}](s_t)=-\sum_{i}{\pi_{\theta}({a_i}|{s_t})}log\pi_{\theta}({a_i}|{s_t}) S[πθ](st)=−∑iπθ(ai∣st)logπθ(ai∣st)代表Entropy Bonus项。
下面确定优势函数A的估计量。
A3C[4]是基于策略梯度的一种流行算法,非常适合与循环神经网络(RNN)一起使用,它在时间步长T上执行策略,并使用收集到的样本进行更新。这种方式需要一个不超越时间步长T的优势估计器。A3C中使用的估计量为:
A ^ t A 3 C = ∑ i = 0 k − 1 ( γ i r t + i + γ k V ( s t + k ) − V ( s t ) ) (10) \hat{A}_t^{A3C}=\sum_{i=0}^{k-1}({\gamma^{i}r_{t+i}+\gamma^{k}V(s_{t+k})-V(s_t)}\tag{10}) A^tA3C=i=0∑k−1(γirt+i+γkV(st+k)−V(st))(10)
令 k = T − t k=T-t k=T−t,则
A ^ t A 3 C = − V ( s t ) + r t + γ r t + 1 + … … + γ T − t − 1 r T − 1 + γ T − t V ( s T ) (11) \hat{A}_t^{A3C}=-V(s_t)+r_t+\gamma r_{t+1}+……+\gamma^{T-t-1}r_{T-1}+\gamma^{T-t}V(s_T)\tag{11} A^tA3C=−V(st)+rt+γrt+1+……+γT−t−1rT−1+γT−tV(sT)(11)
将上述公式进行一般化,可以使用广义优势估计的截断版本:
A ^ t P P O = δ t + ( γ λ ) δ t + 1 + … … + ( γ λ ) T − t − 1 δ T − 1 (12) \hat{A}_t^{PPO}=\delta_t+(\gamma \lambda)\delta_{t+1}+……+(\gamma \lambda)^{T-t-1}\delta_{T-1}\tag{12} A^tPPO=δt+(γλ)δt+1+……+(γλ)T−t−1δT−1(12)
δ t = r t + γ V ( s t + 1 ) − V ( s t ) (13) \delta_t=r_t+\gamma V(s_{t+1})-V(s_t)\tag{13} δt=rt+γV(st+1)−V(st)(13)
当 λ = 1 \lambda =1 λ=1时,发现,
A ^ t , λ = 1 P P O = A ^ t A 3 C (14) \hat{A}_{t,\lambda=1}^{PPO}=\hat{A}_t^{A3C}\tag{14} A^t,λ=1PPO=A^tA3C(14)
如下表所示,是使用固定长度轨迹段的近端策略优化(PPO)算法的伪代码。每次迭代,每N个(并行)参与者收集T个时间步长的数据。然后在这些数据共 N × T N\times T N×T个时间步上构建损失函数,并使用Minibatch SGD(或者使用Adam[7]获取更好的性能)进行K个轮次的优化。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KxqXBOtA-1687154576170)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230619132829496.png)]](https://img-blog.csdnimg.cn/27f3b26c9cf047488faecf43e53dad8c.png)
(八)Experiments
1、各目标函数的比较(Comparison of Surrogate Objectives)
首先,对不同超参数下的几种不同目标函数进行比较。因为需要为每一个算法及其变体寻找合适的超参数,故选择了一个计算成本较低的基准来测试算法,即在Open AI Gym[8]中实现了七个模拟机器人任务,并对每一个都进行了一百万步的训练。对于基于KL惩罚项的目标函数,可以使用固定的惩罚系数 β \beta β或使用第4节中提出的根据KL目标值 d t a r g d_{targ} dtarg得到的自适应系数。其他的超参数如表1所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-odw1k8Kv-1687154576171)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230619133607790.png)]](https://img-blog.csdnimg.cn/02b146b623f04cd09f15ee1e69d32a90.png)
为了表示策略,使用了一个具有两个64单元的全连接MLP,以及非线性激活函数 t a n h tanh tanh,用来输出带有可变标准差的高斯分布的均值[9]。在该实验中,不会在策略和价值函数之间共享参数,也不会使用熵奖励。
每个算法在所有7个环境中运行,每个环境中有3个随机种子。通过计算最后100个episode的平均总奖励来对算法的每次运行进行评分。通过移动和缩放每个环境的分数,以便随机策略给出0分,将最佳结果设置为1分,并在21次运行中取平均值,为每个算法设置生成单个标量。
结果如表2所示。注意,对于没有截断或惩罚的设置,分数是负的,因为对于一个half cheetah环境,它会导致一个非常低的分数,这比初始随机策略更糟糕。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-evPe6vSH-1687154576171)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230619133700038.png)]](https://img-blog.csdnimg.cn/687cb755ae864a65b90962f696f78329.png)
2、在连续域中与其他算法的比较(Comparison to Other Algorithms in the Continuous Domain)
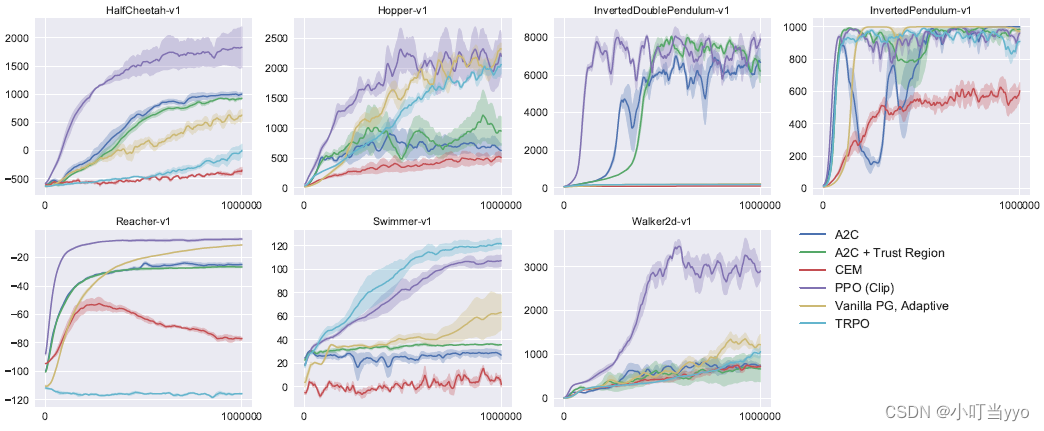
将PPO算法(包括第三节提出的截断目标函数方法)与其他几种方法进行比较,这些问题被证明通常应用在连续控制问题上。具体算法有:信任域策略优化(Trust Region Policy Optimization)[5];交叉熵(Cross-Entropy Method)[10];具有自适应步长的Vanilla策略梯度;A2C[4];具有信任域的A2C[11]。A2C表示Advantage Actor Critic,它是A3C的同步版本,并且它的性能与异步版本相比相同或更好。对于PPO,使用了前一节中的超参数,其中 ϵ = 0.2 \epsilon= 0.2 ϵ=0.2。由图3可以明显看到,PPO在几乎所有的连续控制环境中都优于以前的方法。
3、展示在连续控制环境:Humanoid Running and Steering(Showcase in the Continuous Domain: Humanoid Running and Steering)
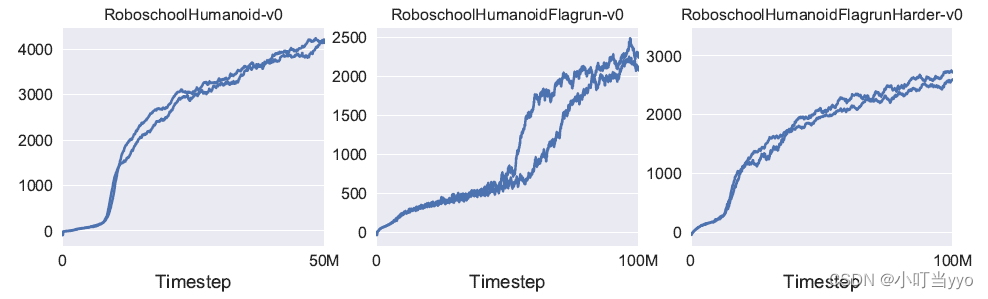
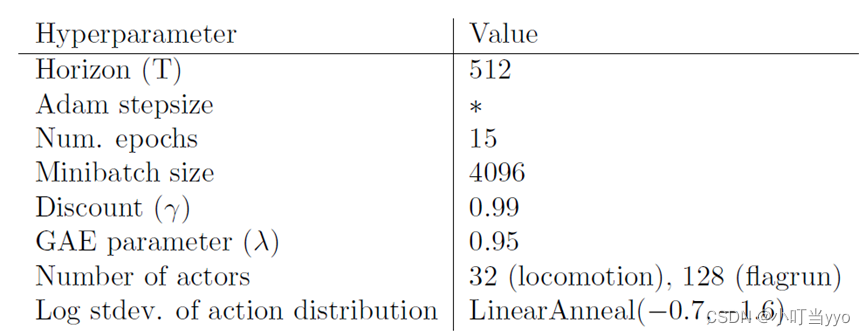
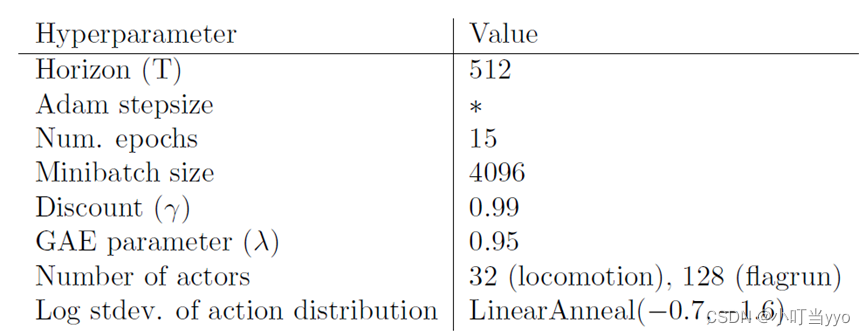
为了展示PPO在高维连续控制问题上的性能,在一组涉及3D人形机器人的问题上进行训练,其中机器人必须移动,转向并离开地面。测试的三个任务难度由高到低分别为:(1)RoboschoolHumanoid:只向前移动;(2)RoboschoolHumanoidFlagrun:目标位置每200个时间步或者每当达到目标时随机变化;(3):RoboschoolHumanoidFlagrunHarder,机器人被立方体投掷,需要离开地面。图4显示了三个任务的学习曲线,图5显示了学习策略的静态框架,表3提供了超参数。在并行工作中,Heess等[12]使用PPO的自适应KL变体(第四节)来学习3D机器人的运动策略。
4、与Atari领域的其他算法的比较(Comparison to Other Algorithms on the Atari Domain)
同样在Arcade Learning Environment[13]基准上运行PPO,并与A2C [4]和ACER [11]的优化实现进行比较。对于这三种算法,使用了与[4]中使用的相同的策略网络架构。表5提供了PPO的超参数。对于另外两种算法,使用了经过调优的超参数,以便在此基准测试中最大化性能。
考虑以下两个评分指标:(1)整个训练期间每章节的平均奖励(有利于快速学习);(2)最后100个训练章节的每章节的平均奖励(有利于最终表现)。表4显示了每种算法“获胜”的游戏数量,通过在三次试验中平均得分指标来计算胜利者。


(九)Conclusion
本文主要基于近端策略优化(PPO)对深度强化学习的策略优化方法进行研究。从传统策略梯度算法,到自然策略梯度算法,再到TRPO算法,以及现在的PPO算法,经过不断的优化迭代,PPO算法已经成为强化学习领域中主流的算法之一。
纵向来看,PPO对策略梯度算法的改进,主要针对的是限制参数迭代的这一步。自然策略梯度算法引入了KL散度约束,TRPO利用线搜索和改进检查来保证限制下的可行性,而PPO则通过clip函数限制了策略可以改变的范围等。相比于前两类算法,PPO在速度、严谨性和可用性之间取得了正确的平衡,具有更好的整体性能。
参考文献:
[1] Kakade S M .A Natural Policy Gradient[C]//Advances in Neural Information Processing Systems 14 [Neural Information Processing Systems: Natural and Synthetic, NIPS 2001, December 3-8, 2001, Vancouver, British Columbia, Canada].2001.
[2] Schulman J , Wolski F , Dhariwal P ,et al.Proximal Policy Optimization Algorithms[J]. 2017.DOI:10.48550/arXiv.1707.06347.
[3] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. “Human-level control through deep reinforcement learning”. In: Nature 518.7540 (2015), pp. 529–533.
[4] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu. “Asynchronous methods for deep reinforcement learning”. In: arXiv preprint arXiv:1602.01783 (2016).
[5] J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel. “Trust region policy optimization”. In: CoRR, abs/1502.05477 (2015).
[6] S. Kakade and J. Langford. “Approximately optimal approximate reinforcement learning”. In: ICML. Vol. 2. 2002, pp. 267–274.
[7] D. Kingma and J. Ba. “Adam: A method for stochastic optimization”. In: arXiv preprint arXiv:1412.6980 (2014).
[8] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W.Zaremba. “OpenAI Gym”. In: arXiv preprint arXiv:1606.01540 (2016)
[9] Y. Duan, X. Chen, R. Houthooft, J. Schulman, and P. Abbeel. “Benchmarking Deep Reinforcement Learning for Continuous Control”. In: arXiv preprint arXiv:1604.06778 (2016).
[10] I. Szita and A. L¨ orincz. “Learning Tetris using the noisy cross-entropy method”. In:Neural computation 18.12 (2006), pp. 2936–2941.
[11] Z. Wang, V. Bapst, N. Heess, V. Mnih, R. Munos, K. Kavukcuoglu, and N. de Freitas. “Sample Efficient Actor-Critic with Experience Replay”. In: arXiv preprint arXiv:1611.01224 (2016).
[12] N. Heess, S. Sriram, J. Lemmon, J. Merel, G. Wayne, Y. Tassa, T. Erez, Z. Wang, A. Eslami, M. Riedmiller, et al. “Emergence of Locomotion Behaviours in Rich Environments”. In: arXiv preprint arXiv:1707.02286 (2017).
[13] M. Bellemare, Y. Naddaf, J. Veness, and M. Bowling. “The arcade learning environment: An evaluation platform for general agents”. In: Twenty-Fourth International Joint Conference on Artificial Intelligence. 2015.