基本概念:
1、基本假设:
统计学习假定数据存在一定的统计规律,监督学习关于数据的基本假设就是假设X和Y具有联合概率分布P(X, Y)。
统计学习方法的三要素是模型、策略、算法。
2、假设空间(模型):
监督学习的模型可以是概率模型或非概率模型,由条件概率分布P(Y|X)或决策函数Y=f(X)表示,随具体学习方法而定。对具体的输入进行相应的输出预测时,写作P(y|x)或y=f(x)。
3、策略:
在假设空间中选取模型f作为决策函数,对于给定的输入X,由f(X)给出相应的输出Y,这个输出f(X)与真实值Y可能一致也可能不一致,用损失函数来度量预测错误的程度,如果能使这个损失函数足够小,则可以保证模型具有较好的预测精度。损失函数是f(X)和Y的非负实数函数,记作L(Y, f(X))。
- 损失函数:损失函数度量模型
一次预测的好坏; - 风险函数:风险函数度量
平均意义下模型预测的好坏,即期望损失。
(1)损失函数
-
0-1损失函数(0-1 loss function)
可以看出,该损失函数的意义就是,当预测错误时,损失函数值为1,预测正确时,损失函数值为0。该损失函数不考虑预测值和真实值的误差程度,也就是只要预测错误,预测错误差一点和差很多是一样的。
感知机就是用的这种损失函数。但是由于相等这个条件太过严格,因此我们可以放宽条件,即满足 |Y−f(X)|<T 时认为相等。
-
平方损失函数(quadratic loss function)
该损失函数的意义也比较简单,就是取预测差距的平方。 -
绝对值损失函数(absolute loss function)
该损失函数的意义和上面差不多,只不过是取了绝对值,差距不会被平方放大。 -
对数损失函数(logarithmic loss function)
这个损失函数就比较难理解了。事实上,该损失函数用到了极大似然估计的思想。P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。
逻辑斯特回归的损失函数就是对数损失函数,
对数损失函数与极大似然估计的对数似然函数本质上是等价的,所以逻辑回归直接采用对数损失函数来求参数,实际上与采用极大似然估计来求参数是一致的。
-
指数损失函数
AdaBoost就是以指数损失函数为损失函数的。 -
Hinge损失函数
Hinge损失函数和SVM是息息相关的。在线性支持向量机中,最优化问题可以等价于 :
这个式子和如下的式子非常像:
其中 就是hinge损失函数,后面相当于L2正则项。
Hinge函数的标准形式:
y是预测值,在-1到+1之间,t为目标值(-1或+1)。其含义为,y的值在-1和+1之间就可以了,并不鼓励|y|>1,即并不鼓励分类器过度自信,让某个正确分类的样本的距离分割线超过1并不会有任何奖励,从而使分类器可以更专注于整体的分类误差。扫描二维码关注公众号,回复: 3446408 查看本文章
(2)风险函数
全局损失函数:
上面的损失函数仅仅是对于一个样本来说的。而我们的优化目标函数应当是使全局损失函数最小。因此,全局损失函数往往是每个样本的损失函数之和,也叫经验风险函数。
模型的输入、输出(X, Y)是随机变量,遵循联合分布P(X, Y),所以损失函数的期望:
这是理论上f(X)关于联合分布P(X, Y)平均意义下的损失,成为风险函数或期望损失。
如果知道联合分布P(X, Y),可以从联合分布直接求出条件概率分布P(Y | X),就不需要学习了(例如:朴素贝叶斯是不需要学习的). 正是因为不知道联合概率分布,所以才需要学习。
那么,联合概率分布不确定的情况下如何构建模型呢?
一个很自然的想法就是利用现实中观察到的训练样本来对模型进行近似,数据越多,模型却接近全局。
给定一个训练数据集:
模型f(X)关于训练集T的平均损失称为经验风险或经验损失:
根据大数定律,当样本容量N趋于无穷,经验风险趋于期望风险。但由于数据数目有限,需要对经验风险进行一定的校正,从而涉及监督学习的两个基本策略:
- 经验风险最小化
- 结构风险最小化
经验风险最小化和结构风险最小化:
当样本容量足够大时,经验风险可以保证较好的学习效果:
经验风险最小化求最优模型就是求解最优化问题:
当模型是条件概率分布、损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。
当样本容量很小时,则会产生“过拟合”,结构风险最小化是为了防止过拟合而提出的策略。
机构风险最小化等价于正则化,结构风险在经验风险上加上表示模型复杂度的正则化项或惩罚项。
结构风险定义如下:
其中J(f)为模型复杂度。
当模型是条件概率分布、损失函数是对数损失函数、模型复杂度由模型的先验概率表示时,结构风险最小化就等价于最大后验概率估计。
结构风险最小化求最优模型就是求解最优化问题:
因此,监督学习问题就变成了经验风险或结构风险函数的最优化问题,这时经验或结构风险函数是最优化的目标函数。
4、算法
算法是指学习模型的具体计算方法。
(1)统计学习基于训练数据集,根据学习策略,从假设空间中选择最优模型,最后需要考虑用什么样的计算方法求解最优模型。
(2)这时,统计学习问题归结为最优化问题,统计学习的算法成为求解最优化问题的算法。
(3)如果最优化问题有显式的解析解,这个最优化问题就比较简单。但通常解析解不存在,这就需要用数值计算的方法求解。
(4)统计学习中最常用的算法是梯度下降法。
5、模型评估
当损失函数给定时,基于损失函数的模型的训练误差和模型的测试误差就自然成为学习算法的评估标准,但统计学习方法具体采用的损失函数未必是评估时使用的损失函数,让两者一致是比较理想的。对于给定的两种学习方法,测试误差小的方法具有更好的预测能力。
-
错误率和精度
该评估方法与0-1损失函数对应。 -
查准率、查全率
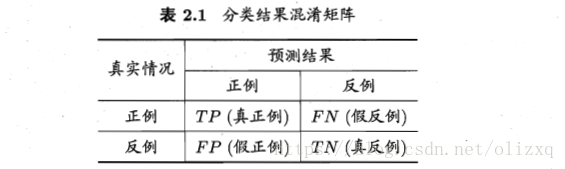
查准率:表示预测为正例的样本中有多少比例真实为正例(检索的信息中有多少比例是用户感兴趣的)。
查全率:表示真实为正例的样本有多少比例被预测为正例(用户感兴趣的信息有多少比例被检索出来)。
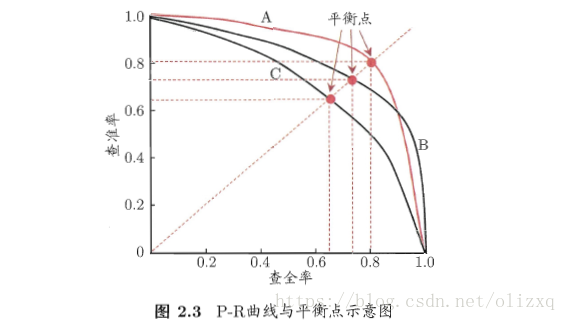
查准率和查全率是一对矛盾的度量,比如选择好瓜:当查准率高时,只会选择最有把握的瓜,从而漏掉不少好瓜,查全率较低;当查全率高时,可通过增加选瓜的数量来实现,如果所有的瓜都被选上,则所有好瓜都被选中,这样查准率就比较低。
-
F1度量
F1度量的一般形式:
写成下面形式更容易理解:
由上式可看出,当 时,即F1度量, 会平衡查准率和查全率;当 时,查全率有更大影响;当 时,查准率有更大影响; -
ROC与AUC
如果要判断两个学习器的性能,通常,比较合理的判据是比较ROC曲线下的面积,即AUC。

6、模型选择
如图描述了训练误差和测试误差与模型的复杂度之间的关系。当模型的复杂度增大时,训练误差会逐渐减小并趋向于0;而测试误差会先减小,达到最小值后又增大。当选择的模型复杂度过大时,过拟合现象就会发生。这样,在学习时就要防止过拟合,进行最优的模型选择,即选择复杂度适当的模型,以达到使测试误差最小的学习目的。两种常用的模型选择方法:正则化与交叉验证。

-
正则化
加入正则化项可以修正模型的过拟合,模型是否过拟合可通过交叉验证来判断,通过调节 来调整惩罚项的大小,改善过拟合可以提高模型泛化性能。 -
交叉验证
交叉验证使用较多的是5折或10折交叉验证。
方法如下:首先随机地将已给数据切分为S个互不相交的大小相同的子集;然后利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的s种选择重复进行;最后选出S次评测中平均测试误差最小的模型。

7、生成模型与判别模型
生成模型 --> 过程(得到输入输出之间的关系)
判别模型 --> 结果(判别最终的结果)

8、习题:
1、说明伯努利模型的极大似然估计以及贝叶斯估计中的统计学习方法三要素。
统计学习方法的三要素是模型、策略、算法。
伯努利模型是定义在取值为0与1的随机变量上的概率分布。
统计学分为两派:经典统计学派和贝叶斯统计学派。两者的不同主要是,经典统计学派认为模型已定,参数未知,参数是固定的,只是还不知道;贝叶斯统计学派是通过观察到的现象对概率分布中的主观认定不断进行修正。
极大似然估计和贝叶斯估计的模型都是伯努利模型也就是条件概率模型;极大似然估计用的是经典统计学派的策略,贝叶斯估计用的是贝叶斯统计学派的策略;为了得到使经验风险最小的参数值,使用的算法都是对经验风险求导,使导数为0(梯度下降法)。
2、通过经验风险最小化推导极大似然估计:证明模型是条件概率分布,当损失函数是对数损失函数时,经验风险最小化等价于极大似然估计。
证明:
模型是条件概率分布:
损失函数是对数损失函数:
经验风险:
最小化经验风险,也就是最大化
,也就是最大化
,这个就是极大似然估计。
参考:
《统计学习方法》 李航
《机器学习》 周志华
课后习题参考