我敲,辣鸡设计,也怪我手贱,csdn的用书体验设计还得加强。又从头再来
先在chrome浏览器中安装 xpath helper 插件。
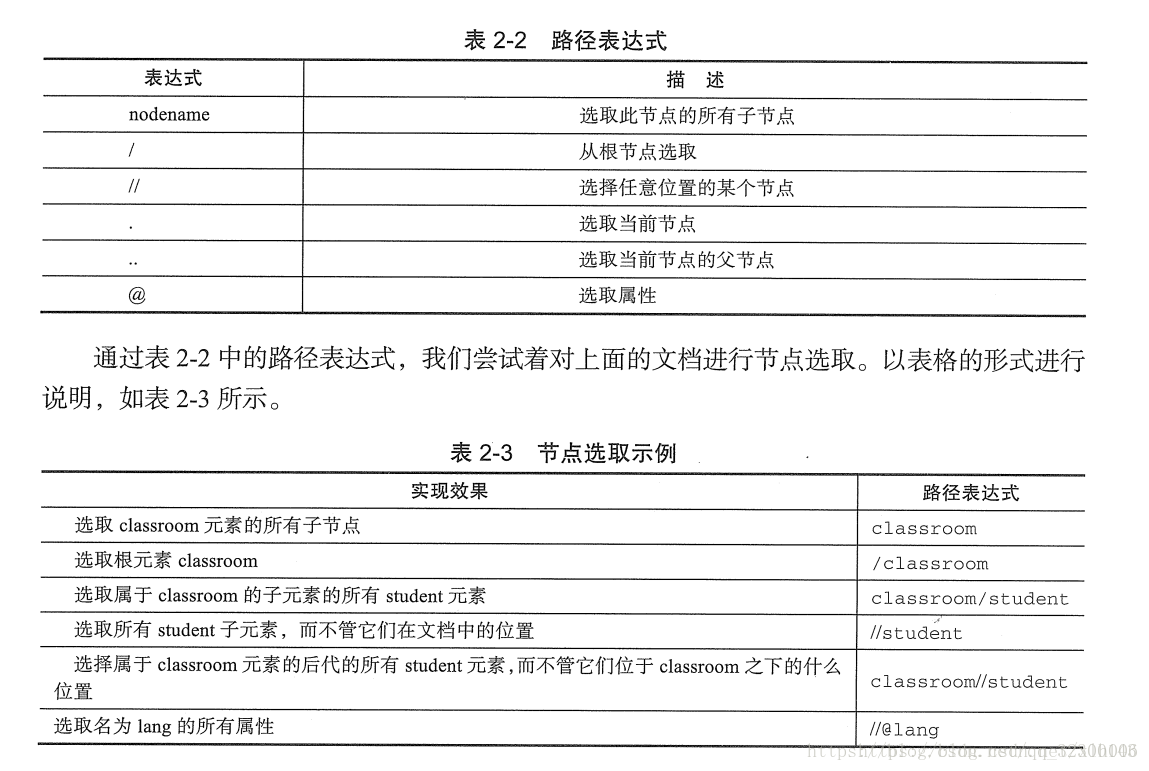
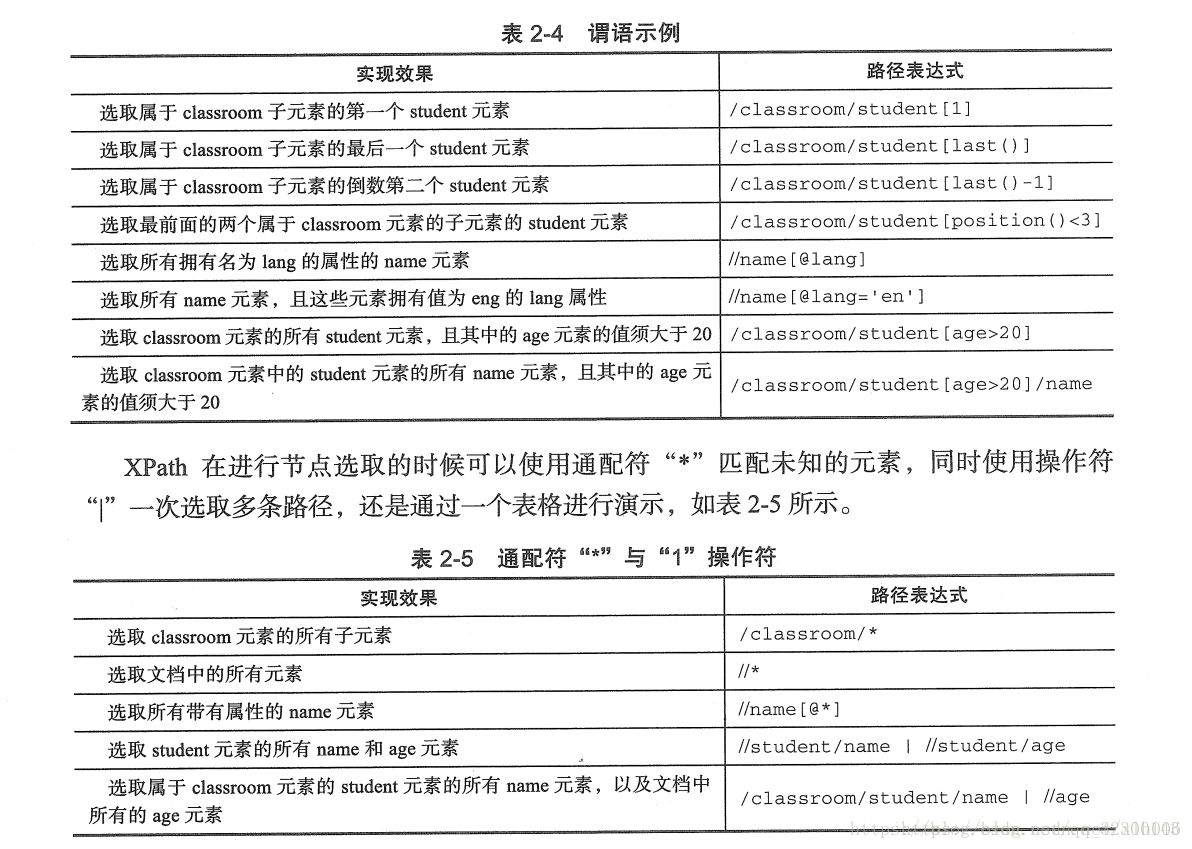
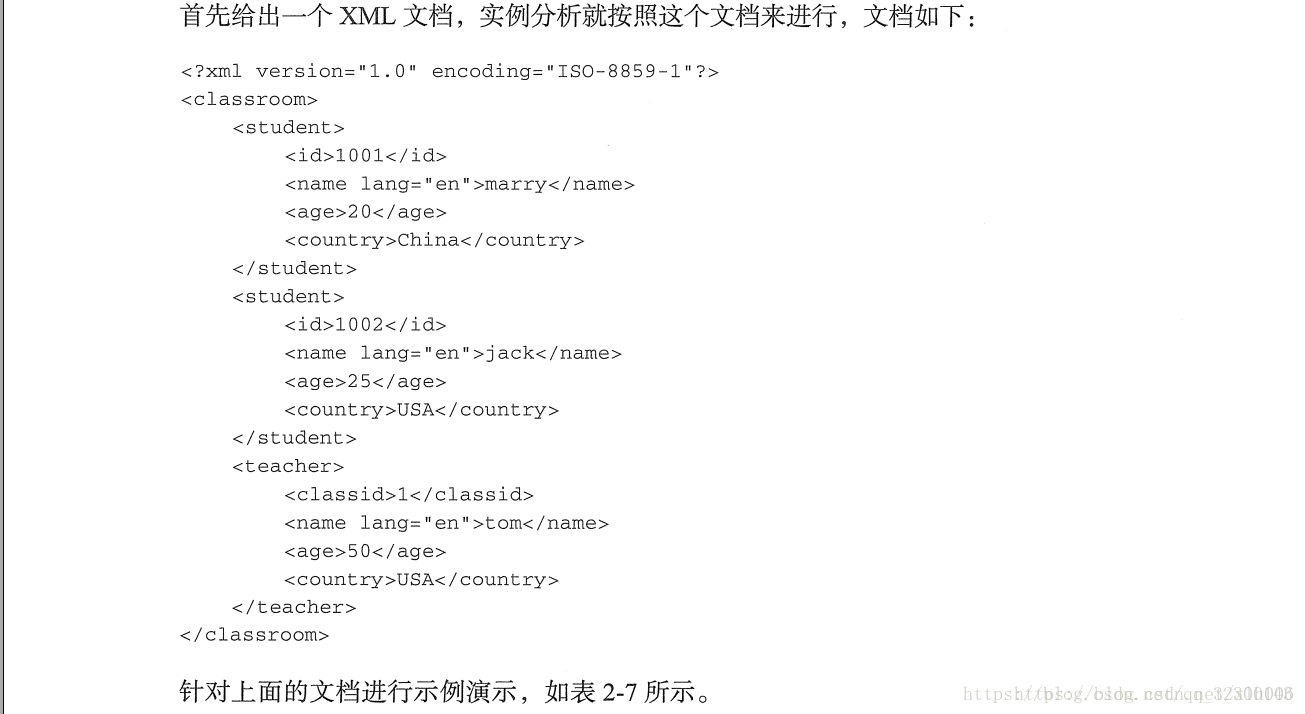
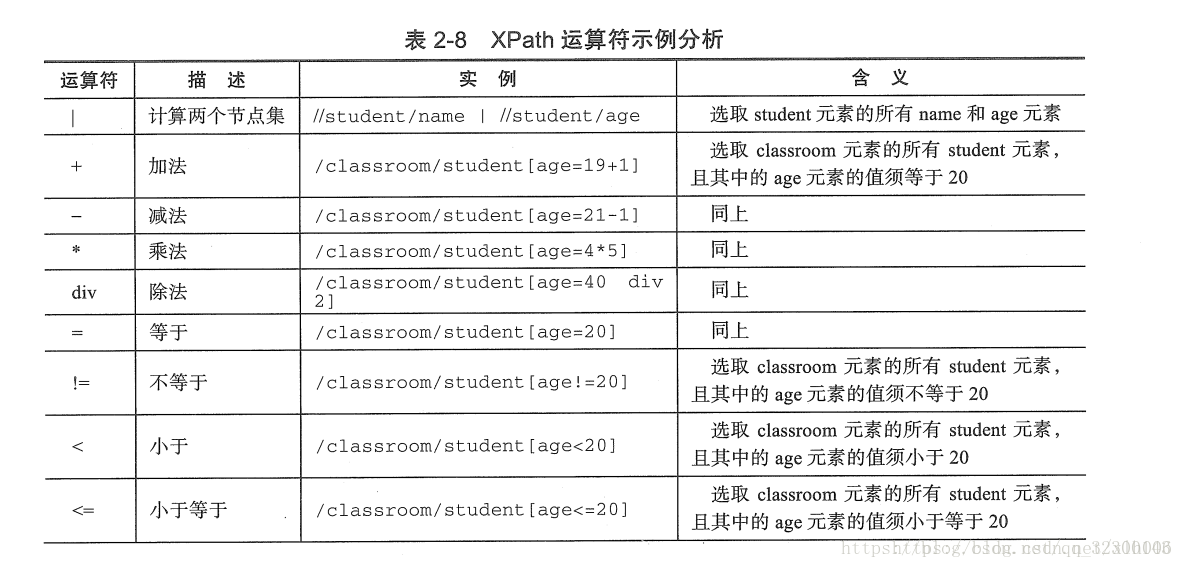
1.xpath的语法
可以去菜鸟教程学习。
python爬虫中xpath的使用方法
前言
这里默认读者已经按照lxml包,因此在使用一下案例的使用,第一步就是导入包:
from lxml import etree- 1
使用案例
这里都使用一下的测试文本
#测试html文档
wb_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用包方法,获取一个一个html页面的对象,需要说明的是,这里会自动补全页面中缺失的必要标签。
#使用etree的HTML方法获取数据,返回的是一个节点对象
html = etree.HTML(wb_data)- 1
- 2
读者可以使用:print((etree.tostring(html)).decode("UTF-8"))进行测试。
01.通过对应的a标签获取a标签中的内容
html = etree.HTML(wb_data)
html_data=html.xpath("/html/body/div/ul/li/a")#此时返回的是各个标签对象
for i in html_data:
print(i.text)- 1
- 2
- 3
- 4
结果为:
first item
second item
third item
fourth item
fifth item- 1
- 2
- 3
- 4
- 5
当然也可以改变xpath的值,使用:"/html/body/div/ul/li/a/text()"返回一个列表:['first item', 'second item', 'third item', 'fourth item', 'fifth item']
02.获取指定路径下a标签的属性
html = etree.HTML(wb_data)
html_data=html.xpath("/html/body/div/ul/li/a/@href")#返回一个列表
print(html_data)- 1
- 2
- 3
结果为:['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
03.获取绝对路径下a标签属性等于link2.html的内容
html_data=html.xpath('/html/body/div/ul/li/a[@href="link2.html"]/text()')
print(html_data)- 1
- 2
结果为:['second item']
04.(相对路径)查找所有li标签下的a标签内容
html_data=html.xpath("//li/a/text()")
print(html_data)- 1
- 2
结果为:['first item', 'second item', 'third item', 'fourth item', 'fifth item']
05.相对路径获取标签的属性
html_data=html.xpath("//li/a/@href")
print(html_data)- 1
- 2
结果为:['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
06.相对路径下查特定属性的方法
html_data=html.xpath("//li/a[@href='link2.html']/text()")
print(html_data)- 1
- 2
结果为:['second item']
07.查找倒数第二个li标签里的a标签的href属性
html_data = html.xpath('//li[last()-1]/a/text()')
print(html_data)- 1
- 2
结果:['fourth item']
当然获取最后一个标签为:li[last()]



在windows系统中实现python3安装lxml
lxml是Python中与XML及HTML相关功能中最丰富和最容易使用的库。lxml并不是Python自带的包,而是为libxml2和libxslt库的一个Python化的绑定。它与众不同的地方是它兼顾了这些库的速度和功能完整性,以及纯Python API的简洁性,与大家熟知的ElementTree API兼容但比之更优越!但安装lxml却又有点麻烦,因为存在依赖,直接安装的话用easy_install, pip都不能成功,会报gcc错误。
爬虫时通常要安装LXML,对于通过一下命令行
pip install lxml
使用lxml解析HTML代码:
1、解析htm字符串:使用"lxml.etree.HTML"进行解析。示例代码如下:
"""python
htmlElement = etree.parse("text")
print(etree.tostring(htmlElement,encoding = "utf-8).decode("utf-8))
"""
2、解析html文件:使用'"lxml.etree.parse"进行解析。实例代码如下:
"""python
htmlElement = etree.parse("tencent.html")
print(etree.tostring(htmlElement,encoding = "utf-8).decode("utf-8))
"""
这个代码使用的是"xml"解析器,所以如果碰到不规范的html代码的时候就会解析错误,这时候要自己创建'HTML'解析器。
"""python
parser = etree.HTMLParser(encoding = 'utf-8')
htmlElement = etree.parse("lagou.html",parser=parser)
print(etree.tostring(htmlElement,encoding = "utf-8).decode("utf-8))
"""