什么是Xpath
xpath 是在XML文档中搜索内容的一门语言,html是xml的一个子集
前置知识
<book>
<id>1</id>
<name>2</name>
<num>
<nick>3</nick>
<div>
<nick>4</nick>
</div>
<span>
<nick>5</nick>
</span>
</num>
<author id="6">7</author>
<book/>
其中<>中的内容称为节点,,是兄弟节点,是它们的父节点。xpath找内容时,靠节点关系进行查询,如/book/id
安装lxml模块
pip install lxml
Xpath用法
1.如上边内容,想要拿去id的内容,获得[1]
from lxml import etree
tree = etree.XML(xml)
result = tree.xpath("/book/id/text()") #text()拿文本
2.若想要找到内容[3, 4 ,5]用第一种方法就行不通了,若用第一种方式只能输出3,此时需要另一种方式
result = tree.xpath("/book/num//nick/text()") # //表示拿取所有后代
3.如果想要内容[3, 4, 5],也可以使用通配符的方式
result = tree.xpath("/book/num/*/nick/text()") # *表示任意节点
4.这里有个b.tml,代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
</head>
<body>
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://www.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="feiji">飞机</a></li>
<li><a href="dapao">大炮</a></li>
<li><a href="huoche">火车</a></li>
<ol>
<div class="job">李嘉诚</div>
<div class="common">普遍</div>
</body>
</html>
若只想获取html中一个text内容,如获得一个[百度]的内容
from lxml import etree
tree = etree.parse("b.html")
result = tree.xpath("/html/body/ul/li[1]/a/text()") #xpath的顺序是从1开始的
5.若想拿到href=“dapao”的内容,[大炮]
result = tree.xpath("/html/body/ol/li/a[@href='dapao']/text()") #[@xxx=xxx]是对属性的筛选
6.从ol的li中提取文字信息,想要获得内容[飞机,大炮,火车]
扫描二维码关注公众号,回复:
14919922 查看本文章

ol_li_list = tree.xpath("html/body/ol/li")
for li in ol_li_list:
result = li.xpath("./a/text()") # ./相对路径
7.若想获得ol的li中的a标签的href值
ol_li_list = tree.xpath("html/body/ol/li")
for li in ol_li_list:
result = li.xpath("./a/@href") #拿到属性值通过@属性
另一种方案是
result = tree.xpath("/html/body/ol/li/a/@href")
实例:使用Xpath爬取人邮教育书籍信息
思路
1.首先获取页面源代码,输入关键词查看渲染方式确定是服务器渲染。

2.在页面中按f12打开开发者模式,发现单一书本的模块信息对应于标记的代码,那么我们使用xpath的时候就能直接选中代码右键,copy xpath方便我们爬取信息。解决一个模块以后就可以利用循环解决其他部分的模块。
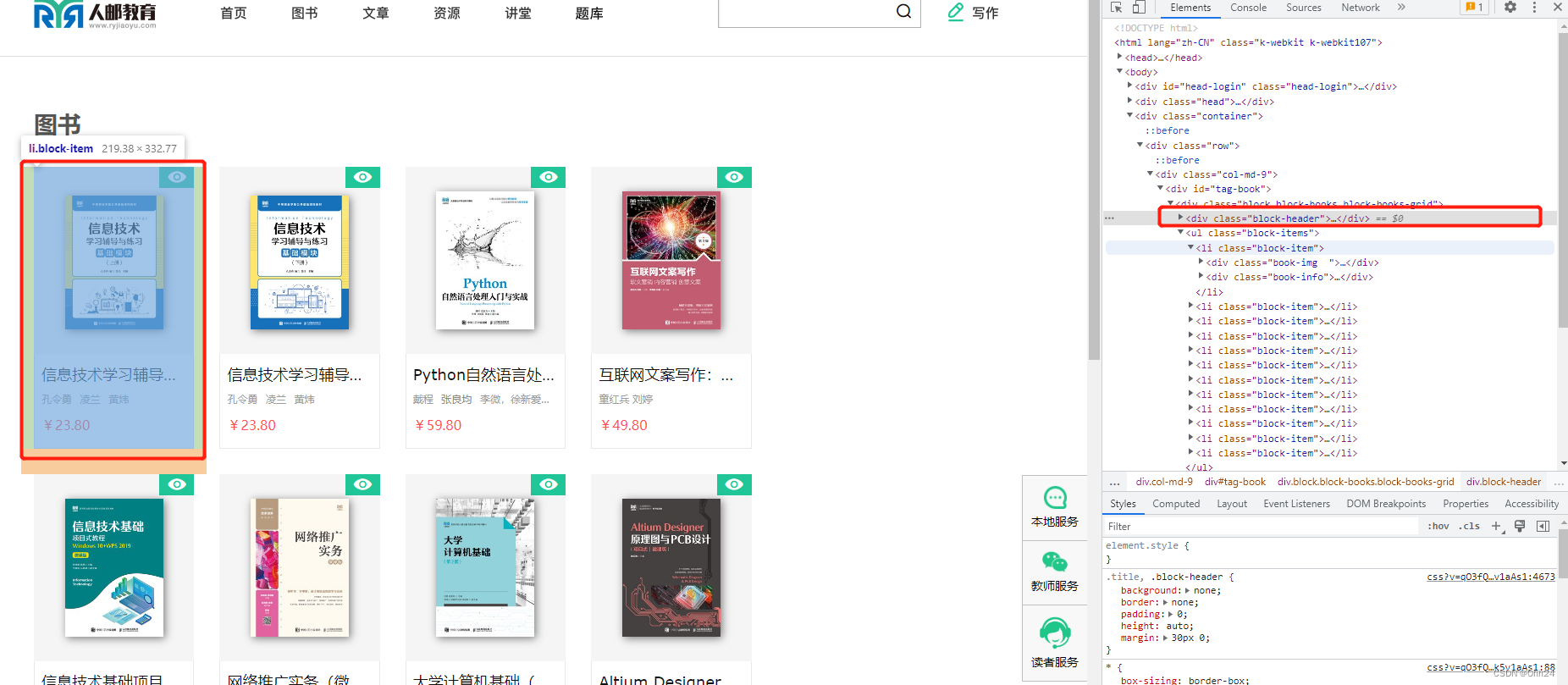
3.进一步观察,可以发现我们需要爬取的信息
代码
import requests
from lxml import etree
import csv
import time
url = "https://www.ryjiaoyu.com/tag/details/7"
resp = requests.get(url)
#print(resp.text)
#解析
html = etree.HTML(resp.text)
f = open("book.csv",mode="w",newline='')
csvwriter = csv.writer(f)
#拿到每一块内容
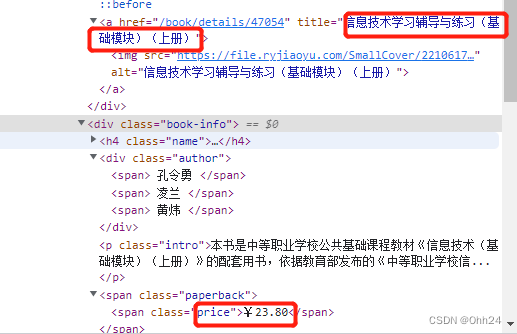
divs = html.xpath("/html/body/div[3]/div/div/div/div/ul/li/div[2]")
for div in divs:
name = div.xpath("./h4/a/text()")[0]
#print(name)
author = div.xpath("./div/span/text()")[0].strip()
#print(author)
price = div.xpath("./span/span/text()")[0].strip("¥")
#print(price)
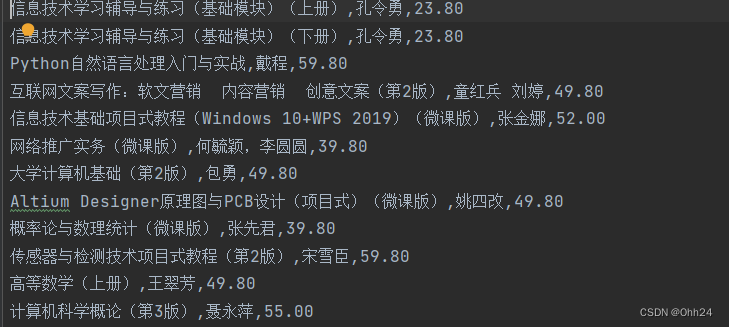
csvwriter.writerow([name,author,price])
time.sleep(1)
f.close()
print("over!")
resp.close()
结果