前言
有时候爬取网站时,我们只需要特定的数据,这时候我们就需要用到正则表达式来匹配数据
代码示例
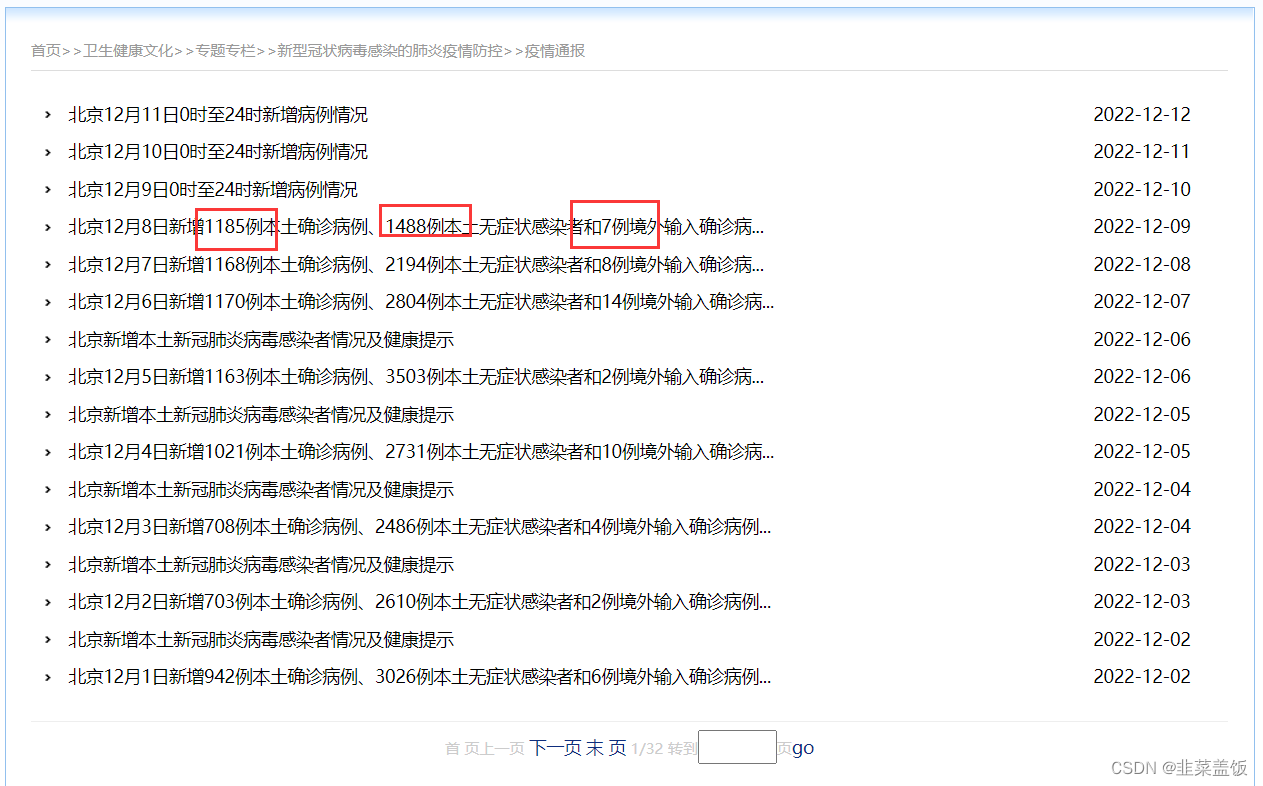
我们只需要爬取红框中的数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
url = 'http://wjw.beijing.gov.cn/wjwh/ztzl/xxgzbd/gzbdyqtb/'
#用户伪装成浏览器
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
#返回请求的html代码
resp = requests.get(url=url,headers=headers)
html = resp.text
bs = BeautifulSoup(html)
#解析特定标签
content = bs.find_all(name='a',attrs={
"target":"_blank"})
print(content)
#遍历每一个匹配的标签
for item in content:
strs = item.string
#正则表达式匹配特定数据
result = re.search("新增(\d+)例本土确诊病例、(\d+)例本土无症状.*(\d+)例境外输",strs)
print(result)
if result:
#print(result.group())
#输出特定的三种数据
print(result.group(1),result.group(2),result.group(3))
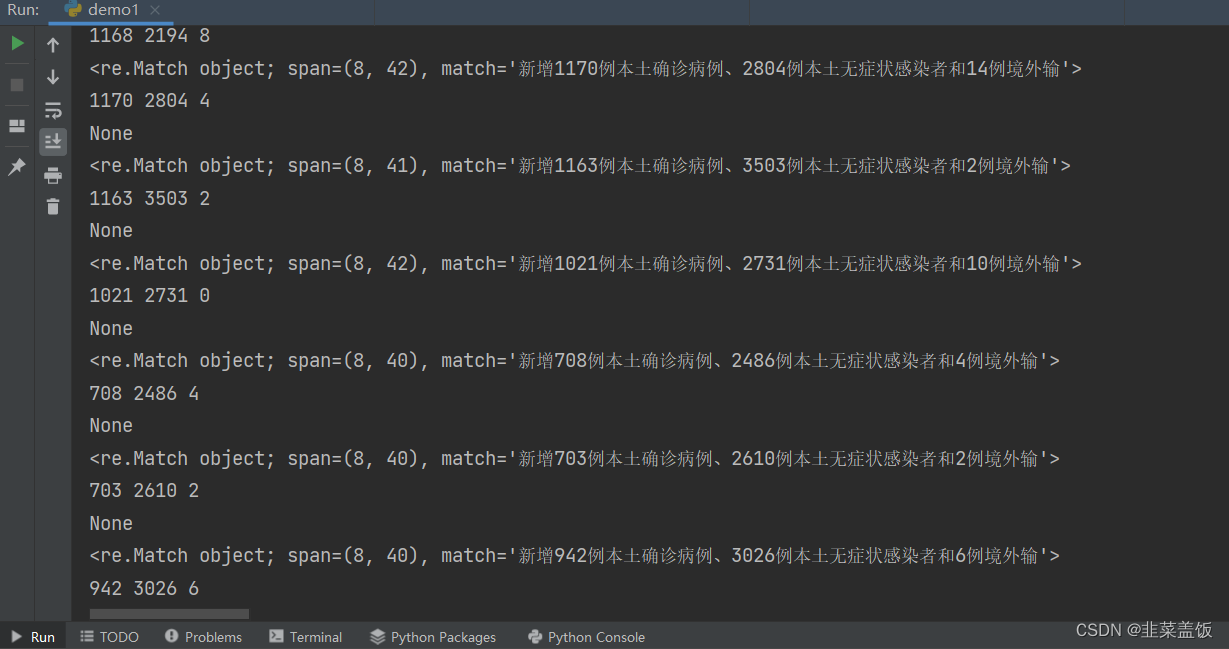
运行结果